大数据日志的多维度设计思路
为了统计APP的各种指标和效果,我们可能会采用友盟、谷歌统计,CNZZ等成熟产品,它们提供了很强大的筛选和聚合统计能力,这里面涉及的就是大数据场景下的多维度日志统计分析,下面记录一些我的想法。
日志与维度
分析与统计的前提是有数据,所以首先需要上报日志,日志是什么样子呢?
我理解日志就是由很多key=vaule组成的,每一个key=value称为一个维度。
举个日志的例子:
| 日期 | 事件类型 | 设备类型 | 屏幕尺寸 |
| 2019-02-21 10:00:00 | 加入购物车 | 安卓 | 6寸 |
这条日志有4个维度,分别是:日期、事件类型、设备类型、屏幕尺寸。
任何一条日志都应该代表发生了某个事件,这才有统计的意义,所以貌似事件类型具有一种特殊性,但其实仍旧可以把它视作一个普通的维度。
我们未来想统计:在2019-02-21当天不同终端(苹果,安卓)加入购物车次数,那么就需要用到日志中的3个维度参与计算,我们可以暂时认为上述日志存储到MYSQL中,那么利用SQL完成计算:select 设备类型, count(*) cart_count from logs where 事件类型=加入购物车 and 日期>=2019-02-21 00:00:00 && 日期<=2019-02-21 23:59:59 group by 设备类型。
所以,我们根据统计分析的需要,让APP在日志中上报所需的维度,那么后续按照不同维度分析就特别灵活了。
存储问题
因为分析需要,经常需要增加维度,比如对上述日志增加一个”网络类型”的维度,比如:4G or wifi。
这时候我们就得考虑日志怎么存的问题了。
大数据放HDFS是标准方案,我们把日志解析后,按照预先定义好的维度顺序排列好key=value,然后把value写入到HDFS的文件中,这就完成了落地操作。
基于HDFS中的文件,可以建立hive外表,从而可以利用SQL完成数据分析。
问题就是,如果维度有增加或者减少怎么办?HDFS文件保存的日志行是按照当前的维度顺序排列的value,增加维度意味着今后的日志上报会增加新的维度值存储到日志行的末尾。此时,我们还需要变更hive的schema,添加新的列到末尾。
因为使用了hive外表,所以改变元信息的操作并没有什么性能损耗,但如果我们要删除维度呢?首先HDFS里已经存在的日志本身是无法改变的,那么还是得改HIVE的schema,但是因为HIVE是按分隔符切分日志行加载数据的各个列的,所以删除一个中间的维度是会影响hive的数据加载关系。
因此,我能想到的方案是日志实时进入到HBASE中存储,因为HBASE是列存储,支持动态列,所以我们的日志可以很方便的扩展上报维度,统一保存到HBASE的列簇下即可。
最终分析数据还是需要HIVE来跑SQL,所以我们需要通过HIVE建立基于HBASE的外表,这是HIVE支持的能力。
这时候,我们就需要一个元信息管理服务了,需要用户首先配置好日志支持哪些维度,那么我们就可以根据配置好的维度完成HIVE表和HBASE表的字段映射,完成HIVE表的创建。一旦HIVE表建立,那么就可以执行SQL来完成多维度的数据分析了。
此后,如果我们需要添加或者删除维度,那么首先去元信息管理服务对维度进行配置,接下来基于新的元信息新建HIVE外表,这样后续的统计就可以基于新的HIVE表进行了,另外APP可以上传新的维度值进入到HBASE存储,这样HIVE就可以拿到对应数据进行分析了。
所以存储这块总结一下:
- 日志多维度存储到HBASE
- 维度配置保存到元信息服务
- HIVE外表根据元信息变化触发重建
加速查询
虽然用了HIVE,但是数据量大了分析起来还是很慢的,毕竟底层跑的是map reduce。
所以需要了解到一款开源项目叫做:apache kylin,它可以加速我们的多维度查询,而不是苦等HIVE的SQL完成。
apache kylin不是取代HIVE,它是加强HIVE,即原始数据仍旧在HIVE里,但是经过kylin的计算后可以提供高效的查询能力。
kylin要求我们先挑选hive表中的某些字段作为维度(日期,事件类型,设备类型,屏幕尺寸),并且定义好要统计的1个目标(比如count(*),也可以是对某个字段求avg,max之类的)。
提交kylin后,它就会基于hive进行多轮的预计算,到底算什么呢,对加速后续查询有什么关系呢?
假设我们有4个维度:A B C D,每个维度有诸多可能的value。kylin会对ABCD四个维度的所有value组合做聚合统计,保存到hbase中。然后会接着基于ABCD的聚合结果,计算ABC组合,ABD组合,ACD组合,BCD组合的聚合结果,这些三个维度的聚合统计,可以基于之前四个维度的聚合统计结果计算得到,而不需要再对原始数据重新计算。对于二维组合可以基于三维组合计算,不断如此可以得到不同维度组合下的聚合结果。
这个过程就像下图一样,计算是从图片下方开始逐层上升的,所有组合的聚合统计结果都保存在hbase中。这样,后续用户按某些维度值进行聚合统计时,就可以直接去hbase拿到结果了。
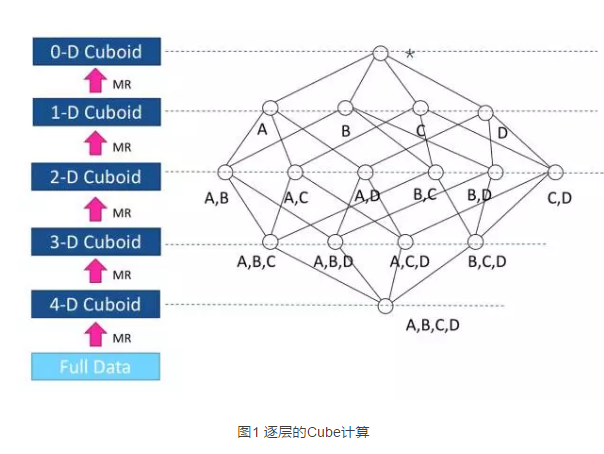
这个过程基于多轮mapreduce实现,具体推荐几篇博客简单了解一下mapreduce过程中的map和reduce关系:
kylin算好所有维度组合的聚合结果后,后续再通过kylin执行SQL就可以加速,数据均可以通过HBASE获取了。
总结
上述就是关于我关于大数据多维度分析的一些初步认识,希望对大家有帮助。
相关参考文章:
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1