强化学习Deep Q-Network自动玩flappy bird
这两天看到通过强化学习自动玩游戏的项目,感觉有趣而且技术难度也不高,所以我也实现了一下。
经过一个通宵的训练,模型已经把小鸟控制的很棒了(训练了5万次左右):
该游戏的规则是:
- 点击屏幕则小鸟立即获得向上速度。
- 不点击屏幕则小鸟受重力加速度影响逐渐掉落。
- 小鸟碰到地面会死亡,碰到水管会死亡。(碰到天花板不会死亡)
- 小鸟通过水管会得分。
实现思路
代码地址:https://github.com/owenliang/FlappyBirdTensorflow,我把注释写的很全,还没来得及把训练好的模型保存起来,后续会找时间再完善一下。
游戏部分是pygame实现的,暴露了方法可以逐帧执行游戏,调用时需要告知这次动作为”点击”还是”不点击”,小鸟会执行相应动作,并返回执行动作后的画面截图。
模型部分采用卷积神经网络,因为模型的输入是游戏画面(准确的说是最近连续的4帧画面),输出为2个神经元,一个表示”点击”的收益(也叫价值、激励),一个表示”不点击”的收益,哪个收益大就采取哪个动作。
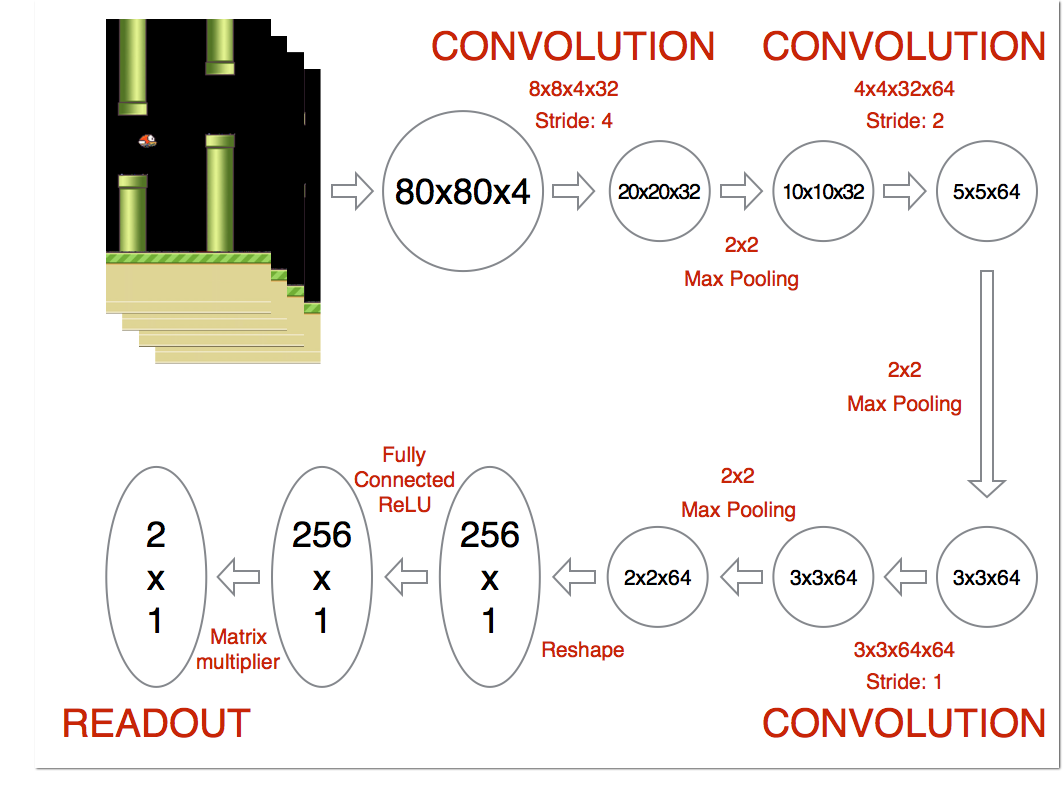
一开始我们让小鸟每一帧随机操作,”点”和”不点”是随机决定的,如果本帧小鸟死掉了则收益为-10,如果通过水管则为+100,如果没死则+0.01,然后不断记录每帧的样本:
(之前的4帧画面stat_t,本次的动作action_index,之后的4帧画面stat_t1,动作收益reward,小鸟是否死了terminal)
上述探索期积攒足够的样本后,我们就可以开始训练模型了,此后我们仍旧会采用一定的概率随机操作,同时有较大概率通过调用模型预测当前画面决定最大收益的操作,这样就相当于”探索”和”经验”并行,继续不断的产生样本再不断的训练模型,通过逐步减小”探索”的概率,以此达到模型的最终收敛。
这个算法叫做Q-learning,属于强化学习的一种:
Q-Learning是强化学习算法中value-based的算法。
Q即为Q(s,a)就是在某一时刻的 s 状态下(s∈S),采取 动作a (a∈A)动作能够获得收益的期望,环境会根据agent的动作反馈相应的回报reward,所以算法的主要思想就是将State与Action构建成一张Q-table来存储Q值,然后根据Q值来选取能够获得最大的收益的动作。
这里s就是当前游戏画面,a就是”点”和”不点”,我们模型要交付的就是输入s,返回”点”和”不点”两个动作的Q值预测,哪个大就采用哪个动作。
Q-learning强化学习原理
如何训练模型呢?需要理解Q(s,a)的含义。
模型就是Q(s,a),它表示在状态s下执行a动作的未来总收益,注意是直到小鸟死掉为止能拿到的总奖励分,而不是当前这一步能得到多少奖励分,也就是一种”长远视角”,说白了就是我们的游戏目标:更高的最终游戏得分。
如何训练模型,让它能预测采取不同动作的各自总收益呢?根据Q-learning思想,其表现为一种递归形式:
模型预测状态s下执行a动作的Q值,应该通过训练不断拟合,尽可能等于”本次a动作获得的即时收益+模型预测状态s1下执行任意动作的最大Q值”。
也就是t时刻的未来总收益应该为当前所执行动作获得的即时收益 + 预测的t1时刻的最大未来总收益。
所以,我们会让模型输入t时刻画面来预测action_index动作的Q值,然后与(reward+模型输入t1时刻画面的最大Q值) 之间计算loss,进行模型参数修正,这样模型就会逐渐学会选择正确的action来获得更大的总收益。
大家可以看一下Q-learning的非模型实现,更容易理解其原本的原理:https://github.com/BENULL/FlappyBirdBot。
个人经验
如果你也在尝试写自己的强化学习flappy bird,你可能遇到和我一样的问题,下面我说一下我的一些特殊处理。
初期足够的随机探索
模型一开始完全没有学到经验,所以在游戏开始后我采用完全随机操作,积攒了10000个样本之后才开始进行模型训练与模型预测。
一开始的随机探索概率是10%,我只在模型训练一个batch之后才会令其概率降低1e-6,随机操作减少趋势非常缓慢,始终保持模型有足够的新鲜样本学习,而不是被自己的经验逼到死角,我训练了一个通宵睡醒后还剩余4%的随机概率,但模型已经表现很好了。
降低点击概率
一开始我采用50%的概率选择”点”和”不点”,发现随机探索的时候小鸟一直冲向天花板,导致很少有通过水管的样本,模型无法学到成功的经验。
考虑到游戏操作特点,每次”点击”小鸟都会立即得到一个向上的速度并且经过数帧的重力加速度才能开始向下,这与”不点”之间存在一定的不公平性,所以容易导致小鸟总向上飞。
所以我选择了90%+的概率采用”不点”操作,这样小鸟随机飞行时有不错的游戏表现,可以积累有效的样本。
合理设计奖励分
最早我采用了这样的奖励机制:执行一帧,死了reward=-1分,活着reward=0.1分,通过一根水管reward=1分,然后发现训练了大半个下午都没有任何效果。
后来考虑了一下,随机飞行很少可以飞过水管,所以样本里很少有正向激励的样本,小鸟会认为只要”不死”就是好的(不死时reward=0.1分),所以倾向于往天花板飞,因为游戏规则中碰到天花板是不会死的,所以往上操作被模型认为”很好”。
为了避免这个问题,除了上面说的随机探索期”降低点击概率”外,我将奖励分进行了调整:
死了reward=-10,活着reward=0.01,通过水管reward=100,这样就鼓励模型优先记住通过水管时的操作,降低对”活着”的记忆,尽可能避免”死掉”的操作。
最后
实际游戏执行了50万帧,每隔10帧我才会训练一次模型(如果每帧都训练会导致游戏画面卡顿),所以一共训练了5万多次32大小的batch,最终模型真的学会了,起床后看到结果还是小兴奋了一阵。
参考链接:
- https://yanpanlau.github.io/2016/07/10/FlappyBird-Keras.html
- https://junmo1215.github.io/machine-learning/2017/06/26/Practice-Playing-flappy-bird-with-DRL.html
- https://github.com/BENULL/FlappyBirdBot
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
1
1