clickhouse(二)删除/更新方案
接前文《clickhouse(一)环境安装&操作分布式表》。
本文探讨clickhouse的1个经典问题:
如何模拟实现记录更新和删除效果?(因为clickhouse自带的update/delete实现极为低效)
跟着我的例子走吧。
创建数据库db2
CREATE DATABASE IF NOT EXISTS db2 ON CLUSTER mycluster
上述语句创建db2数据库,ON CLUSTER mycluster指定将该DDL操作广播到整个集群的所有节点上。
创建商品表product
|
1 2 3 4 5 6 7 8 |
CREATE TABLE db2.product ON CLUSTER mycluster ( id Int64, name String, sign Int8, version UInt64 ) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{shard}/db2/product', '{replica}', version) ORDER BY (id); |
ON CLUSTER mycluster是说把这张表广播到所有节点上建立出来。
再说一下列:
- id:商品ID
- name:商品名
上述是业务字段,商品id是业务侧的主键。
sign和version是我们设计出来的控制字段,用来模拟update和delete操作,方案如下:
- sign:1表示upsert,也就是插入或者更新;-1表示delete,表示删除。
- version:版本号,要保证靠后发生的操作比先前发生的操作version更大。
ReplicatedReplacingMergeTree(‘/clickhouse/tables/{shard}/db2/product’, ‘{replica}’, version)最后的version是什么意思呢?
这里ReplacingMergeTree是一种compaction阶段能够对相同主键进行去重的引擎,当一个主键有多条记录时,version大的被留下,其他被compaction丢掉。
我们就是想要这样的效果,我们只关心同1个id最新version的数据内容~~~
光说还是不懂,下面我们就会进入演练,在此之前我们按常规流程创建出分布式表,后续只读写分布式表即可:
|
1 2 |
CREATE TABLE db2.dis_product ON CLUSTER mycluster AS db2.product ENGINE = Distributed(mycluster, db2, product, rand()); |
ON CLUSTER mycluster在所有node上创建了dis_product分布式表,对它的读取和写入都将是对集群中所有product本地表的分布式处理。
模拟UPDATE/DELETE的思路分析
假定我们是同步mysql的binlog,然后写入到clickhouse的dis_product表。
解析来的binlog主要包含3个信息:
1,操作类型(INSERT/UPDATE/DELETE)
2,本次事务ID,永远递增。
3,变化后的整行数据。
对于操作类型来说,INSERT/UPDATE我们都用sign=1统一为upsert操作,DELETE则用sign=-1表示删除。
事务ID恰好就可以用来作为version,表示数据变更的发生先后关系,对于同一个商品id我们只关心最新version的数据长什么样。
总结一下,
在clickhouse中模拟UPDATE和DELETE的核心思路就是:将UPDATE和DELETE操作都转化为clickhouse表的插入操作,无非是sign和version在变化,最后查询的时候对同一个商品id保留最新的version行即可。
为什么要用replcaingMergeTree呢?因为要让存储引擎自动淘汰掉旧版本的数据,免得存储空间无限上涨。
实践INSERT/UPDATE
我们实践模拟出整个INSERT/UPDATE过程,我们假定数据源是来自mysql的binlog同步产生,mysql每行记录变更都在独立的事务中完成,所以version总是递增(你可以利用canal+kafka自动向clickhouse生成这样的数据,下面均手动模拟):
首先INSERT两行记录:
INSERT INTO db2.dis_product values(1,’尿不湿’,1,1);
INSERT INTO db2.dis_product values(2,’纸巾’,1,2);
它们的sign=1表示INSERT,然后各自的version是1和2。
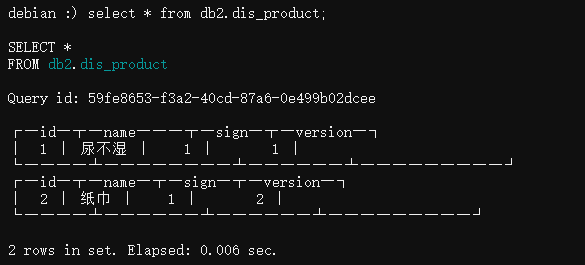
然后我们模拟UPDATE了id=1的记录:
INSERT INTO db2.dis_product values(1,’尿不湿2.0′,1,3);
这次sign=1表示update,版本号来到了3,再看一下数据:
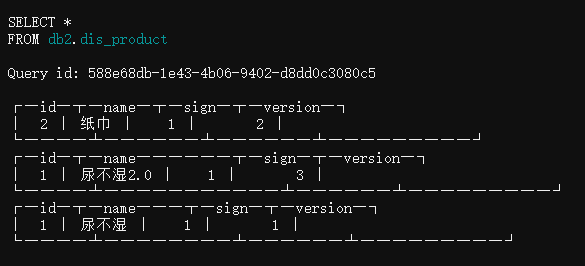
现在出现问题了,id=1主键同时存在新旧2条记录,我们期望只看到version=3的这个新版本数据,因此如果我们希望准确获得表的实际情况,查询时应该这样做:
|
1 2 3 4 5 6 7 |
SELECT id, argMax(name,version) name, argMax(sign,version) sign, max(version) max_version FROM db2.dis_product GROUP BY id; |
按主键ID分组,在组内利用argMax方法选出version最大的那行数据的各个列值。
argMax(name,version)的意思是在Group组内version最大的那行的name列。
说白了,每个id保留最新version的那行数据,结果也显而易见:
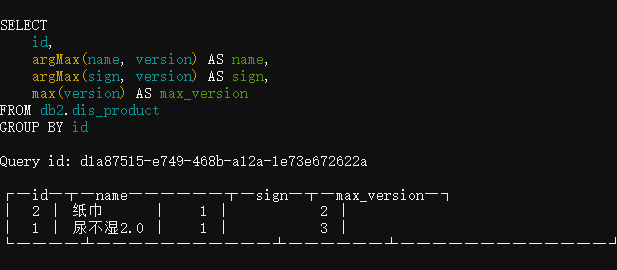
对于id=1来说,version=3的尿不湿2.0被留下了,它的sign=1表示version=3这次变更是一个INSERT/UPDATE操作,数据是有效的。
(注,replacingMergTree虽然compaction时会自动删除同主键旧version数据,但是compaction何时发生是不可知的,所以我们总是应该用SQL来自行去重)
模拟DELETE操作
delete操作我们应该插入一个sign=-1的行,version继续跟随事务ID递增即可。
INSERT INTO db2.dis_product values(2,’纸巾’,-1,4);
我们插入上述语句实现对id=2记录的删除,version是4,sign=-1表示删除。
当我们重新执行上面的查询语句时:
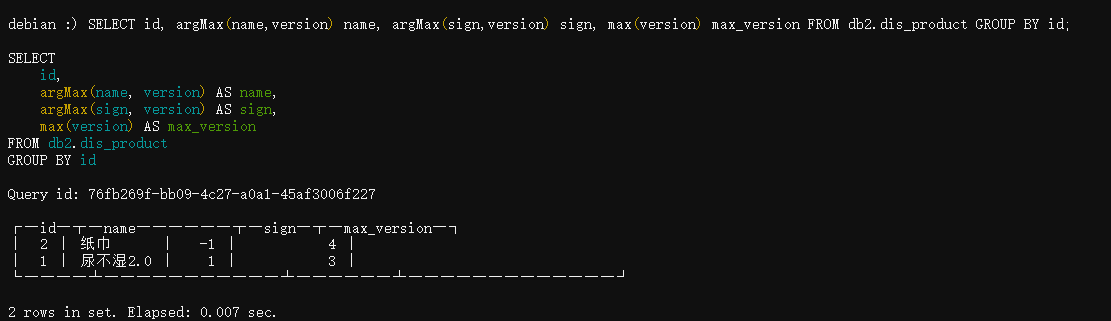
你会发现id=2记录的version=4记录被保留了下来,但实际上因为version=4是sign=-1的删除操作,我们其实不应该看得到这行被删掉的记录,所以我们得完善一下查询SQL让它能够适应这种删除记录的操作:
|
1 2 3 4 5 6 7 8 |
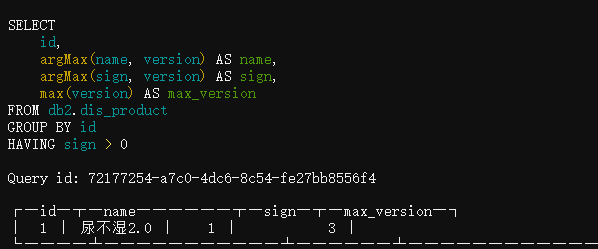
SELECT id, argMax(name,version) name, argMax(sign,version) sign, max(version) max_version FROM db2.dis_product GROUP BY id HAVING sign > 0; |
只需要将sign=-1的那些分组删除掉即可,比如id=2的分组最新版本的sign就是-1,最终被过滤掉:
用视图简化
后续我们做数据分析的话,肯定不希望写每个SQL时都考虑上述sign和version的问题,所以把上述SQL作为一个视图,后续数据分析SQL直接基于视图即可,不必再重复处理sign和version问题。
|
1 2 3 4 5 6 7 8 9 10 |
CREATE VIEW db2.dis_product_view ON CLUSTER mycluster AS SELECT id, argMax(name,version) name, argMax(sign,version) sign, max(version) max_version FROM db2.dis_product GROUP BY id HAVING sign > 0; |
ON CLUSTER mycluster是在所有node上创建这个view,所以后续客户端无论访问任何节点都可以访问到view。
视图就是一个子查询,当我们select * from db2.dis_product_view的时候相当于
select * from (SELECT id, argMax(name,version) name, argMax(sign,version) sign, max(version) max_version FROM db2.dis_product GROUP BY id HAVING sign > 0) as tmp
这就达到了简化后续数据分析SQL复杂度的目的,现在我们直接select这个视图看一下效果:
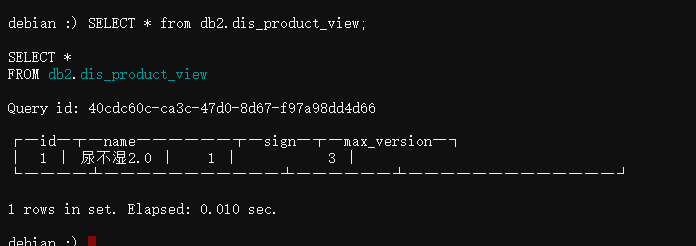
可见,我们没有再关注过sign和version,但数据已经是规整的了,底层伪UPDATE/DELETE的实现细节已经被屏蔽了。
总结
本篇博客教给大家如何在clickhouse中模拟出update和delete操作,这也是mysql实时同步clickhouse的基本原理。
我们用到了关键的replacingMergeTree引擎,它可以在compaction时保留相同主键最新的数据,确保数据库不会无限膨胀。
同时,我们定义了sign和version控制字段实现了数据行的多版本设计,通过SQL为每个主键保留最新一份数据并过滤掉被删除的记录,通过视图屏蔽SQL负责性,为后续使用提供了便捷性。
你也许也看过clickhouse的折叠表等概念,但目前从官方和网上的做法来看replacingMergeTree+sign+version的方案是最为普遍、简单、可靠的,没有明显缺点。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
感谢分享 赞一个
1
鱼儿大佬牛逼 plus
怎么断更了,鱼儿老师,继续啊,11月份了
1
你写得非常清晰明了,让我很容易理解你的观点。
Escorts in Gurgaon
nice