hive基础用法实践
继续阅读前请确保按照《理解与搭建hive》完成了搭建,本文将体验hive的基础用法,简单理解hive的执行原理。
官方文档
遇到问题,优先查询Hive官方文档,因为内容是最新的,而网上写的不一定。
注意事项
- hive的客户端还不是很完善,在显示注释Comment的时候会乱码,但是数据行的中文会正常显示,这个问题可以参考解决方案。
- 新版hive2.x支持Hive的delete,update等操作,需要配置Hive支持事务(transaction),需要修改的hive-site.xml如下(重启metastore和hiveserver2),但是本文不研究这种用法,因为一般没人这么用:
- hive.compactor.initiator.on:true
- hive.compactor.worker.threads:2
- hive.support.concurrency:true
- hive.exec.dynamic.partition.mode:nonstrict
基础操作
连接hive
|
1 2 3 |
bin/beeline -u jdbc:hive2://localhost:10000 -n root set hive.exec.reducers.max=1 |
进入beeline后,输入上述命令限制hive最多使用1个reducer,主要是因为我的hive环境只有1个cpu,而hive通过估算会启动较多的reducer,导致下面的试验半天等不到结果。
创建数据库
|
1 2 3 4 5 6 7 8 9 10 11 12 |
0: jdbc:hive2://localhost:10000> create database myhive; create database myhive; No rows affected (0.089 seconds) 0: jdbc:hive2://localhost:10000> show databases; show databases; +----------------+--+ | database_name | +----------------+--+ | default | | myhive | +----------------+--+ 2 rows selected (0.025 seconds) |
创建内部表
|
1 |
CREATE TABLE mytable (name string, login_times int, last_login timestamp) CLUSTERED BY(`name`) INTO 8 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; |
- CLUSTERED BY:数据按name做哈希分成8个桶。
- ROW FORMAT:DELIMITED是一个别名,当hive数据存储为textfile文本的时候,会自动替换为简单的分隔符序列化类,在下面会看到。
- FIELDS TERMINATED BY:当使用DELIMITED的时候可以使用,用来指示一行中的列分隔符是什么。
- STORE AS:指示hive数据按文本存储在hdfs,同时从hdfs加载数据时也将按文本解析加载。
可以看一下真实的建表语句:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
0: jdbc:hive2://localhost:10000> show create table mytable; +---------------------------------------------------------------------+--+ | createtab_stmt | +---------------------------------------------------------------------+--+ | CREATE TABLE `mytable`( | | `name` string, | | `login_times` int, | | `last_login` timestamp) | | CLUSTERED BY ( | | name) | | INTO 8 BUCKETS | | ROW FORMAT SERDE | | 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' | | WITH SERDEPROPERTIES ( | | 'field.delim'=',', | | 'serialization.format'=',') | | STORED AS INPUTFORMAT | | 'org.apache.hadoop.mapred.TextInputFormat' | | OUTPUTFORMAT | | 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' | | LOCATION | | 'hdfs://172.18.9.75:11000/user/hive/warehouse/myhive.db/mytable' | | TBLPROPERTIES ( | | 'COLUMN_STATS_ACCURATE'='{\"BASIC_STATS\":\"true\"}', | | 'numFiles'='0', | | 'numRows'='0', | | 'rawDataSize'='0', | | 'totalSize'='0', | | 'transient_lastDdlTime'='1487714396') | +---------------------------------------------------------------------+--+ 25 rows selected (0.108 seconds) |
观察一下各个字段:
- DELIMITED被转换成了正规语法,SERDE=org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe指定了数据行序列化/反序列化的类,它用于将一行的每一列进行一定的编码组成一个数据块。
- FIELDS TERMINATED BY这种与DELIMITED配合的简化语法,也被转换成了WITH SERDEPEROPERTIES这种正规语法,括号内为LazySimpleSerDe类提供了一些配置项,主要是列分隔符。
- STORE AS被转化了正规语法,textfile被替换为INPUTFORMAT和OUTPUTFORMAT,它们俩配对用于从hdfs/local文件系统读取文件,或者将数据行写回到hdfs/local时候的文件序列化工作。
- LOCATION指定了该表的数据存储的hdfs路径。
- TBLPROPERTIES为该表指定了一些属性,暂时用不到。
总结整个流程:
- hive读取数据的流程是从hdfs/local fs上利用INPUTFORMAT对文件进行反序列化为一行一行的数据块,然后利用ROW FORMAT指定的SerDe将数据块反序列化为若干列;
- hive写入数据的流程是将若干列利用SerDe序列化为数据块,然后按照OUTPUTFORMAT写入到hdfs/local fs。
创建外部表
外部表可以加载已经存在于Hdfs上的数据,只要这些数据按照外部表的定义格式存储即可。当删除外部表时,数据会保留,因此外部表常用来管理其他系统存储在hdfs上的数据,对其直接进行SQL挖掘计算。
创建并上传文件
我们假设其他系统向hdfs的目录下存储了一些原始数据,其格式符合textfile,内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
[root@localhost hive]# cat stats.txt ming,2016-02-01 10:10:00 ming,2016-02-02 10:10:00 ming,2016-02-03 10:10:00 ming,2016-02-04 10:10:00 wen,2016-02-01 10:10:00 wen,2016-02-02 10:10:00 wen,2016-02-03 10:10:00 xin,2016-02-01 10:10:00 xin,2016-02-02 10:10:00 zhao,2016-02-01 10:10:00 |
我们将其上传到hdfs上的mytable_ext目录下:
|
1 2 3 4 5 |
[root@localhost hive]# ~/hadoop/bin/hadoop fs -mkdir /mytable_ext [root@localhost hive]# ~/hadoop/bin/hadoop fs -put ./stats.txt /mytable_ext [root@localhost hive]# ~/hadoop/bin/hadoop fs -ls /mytable_ext Found 1 items -rw-r--r-- 1 root supergroup 245 2017-02-22 06:41 /mytable_ext/stats.txt |
建立hive外部表
建立一个hive的外部表,指向这个目录:
|
1 |
CREATE EXTERNAL TABLE mytable_ext (name string, login_time timestamp) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/mytable_ext'; |
现在可以直接访问mytable_ext,通过SQL查询其中的数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
0: jdbc:hive2://localhost:10000> select * from mytable_ext; +-------------------+-------------------------+--+ | mytable_ext.name | mytable_ext.login_time | +-------------------+-------------------------+--+ | ming | 2016-02-01 10:10:00.0 | | ming | 2016-02-02 10:10:00.0 | | ming | 2016-02-03 10:10:00.0 | | ming | 2016-02-04 10:10:00.0 | | wen | 2016-02-01 10:10:00.0 | | wen | 2016-02-02 10:10:00.0 | | wen | 2016-02-03 10:10:00.0 | | xin | 2016-02-01 10:10:00.0 | | xin | 2016-02-02 10:10:00.0 | | zhao | 2016-02-01 10:10:00.0 | +-------------------+-------------------------+--+ 10 rows selected (0.128 seconds) |
从外部表导入内部表
一般都是在外部表数据上执行SQL,将统计结果写入到一个已经建立好的内部表上。
下面我将基于mytable_ext统计出每个用户的总登录次数,以及最后登录时间,将统计结果写入到mytable中。
首先,对mytable_ext执行统计:
|
1 |
SELECT `name`,COUNT(*) as login_times,max(login_time) as last_login from mytable_ext group by name; |
之后,将这个结果插入到mytable中去:
|
1 |
INSERT OVERWRITE TABLE mytable SELECT `name`,COUNT(*) as login_times,max(login_time) as last_login from mytable_ext group by name; |
这里OVERWRITE的含义是:原表数据全部删除,由新数据完整取代,现在查询一下mytable:
|
1 2 3 4 5 6 7 8 9 10 11 |
0: jdbc:hive2://localhost:10000> select * from mytable; +---------------+----------------------+------------------------+--+ | mytable.name | mytable.login_times | mytable.last_login | +---------------+----------------------+------------------------+--+ | wen | 3 | 2016-02-03 10:10:00.0 | | sha | 1 | 2016-02-01 10:00:00.0 | | zhao | 1 | 2016-02-01 10:10:00.0 | | ming | 4 | 2016-02-04 10:10:00.0 | | xin | 2 | 2016-02-02 10:10:00.0 | +---------------+----------------------+------------------------+--+ 5 rows selected (0.342 seconds) |
通过Hive,我们用简单的SQL就完成了一次很基础但并不简单的数据挖掘,如果我们直接写mapreduce去搞定这个事情就变得很麻烦了,是Hive简化了这一切。
bucket分桶
现在我们去hdfs上,观察一下mytable这个内部表的数据是如何存储的:
|
1 2 3 4 5 6 7 8 9 10 |
[root@localhost hadoop]# ~/hadoop/bin/hadoop fs -ls /user/hive/warehouse/myhive.db/mytable Found 8 items -rwxrwxr-x 1 root supergroup 26 2017-02-22 07:09 /user/hive/warehouse/myhive.db/mytable/000000_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 07:09 /user/hive/warehouse/myhive.db/mytable/000001_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 07:09 /user/hive/warehouse/myhive.db/mytable/000002_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 07:09 /user/hive/warehouse/myhive.db/mytable/000003_0 -rwxrwxr-x 1 root supergroup 53 2017-02-22 07:09 /user/hive/warehouse/myhive.db/mytable/000004_0 -rwxrwxr-x 1 root supergroup 53 2017-02-22 07:10 /user/hive/warehouse/myhive.db/mytable/000005_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 07:10 /user/hive/warehouse/myhive.db/mytable/000006_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 07:10 /user/hive/warehouse/myhive.db/mytable/000007_0 |
没错,我们之前在建表时指定了8个桶,在hdfs上得到了对应的体现,查看第一个桶的内容可以看到我们的数据行被逗号分割序列化存储:
|
1 2 |
[root@localhost hadoop]# ~/hadoop/bin/hadoop fs -cat /user/hive/warehouse/myhive.db/mytable/000000_0 wen,3,2016-02-03 10:10:00 |
数据是按name字段哈希 mod 8进入具体一个bucket文件的,在建表时已指定,至于分桶的用途会在文章最后说明。
partition分区
在建表的时候可以指定,这样可以将1个表的数据存储到多个子目录下,常用于按日期分库的需求。
我们建一个mytable_partition表,让它基于日期分区,这样我们每天执行一次SQL将统计数据写入到当天的分区中,这样就不会覆盖往日的历史数据了(还记得OVERWRITE的效果吗?)。
|
1 |
CREATE TABLE mytable_partition (name string, login_times int, last_login timestamp) PARTITIONED BY(`date` timestamp) CLUSTERED BY(`name`) INTO 8 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; |
分区字段date和表本身的字段没有关系,仅仅用于分区标识,也不会存储到table的数据文件里。
接下来,我希望将2017-02-23之前的数据统计出来,并存入mytable_partition的date=2017-02-23分区下,那么做法如下:
|
1 |
INSERT OVERWRITE TABLE mytable_partition PARTITION(`date`="2017-02-23") SELECT `name`,COUNT(*) as login_times,max(login_time) as last_login from mytable_ext where login_time<"2017-02-23 00:00:00" group by name; |
查询结果:
|
1 2 3 4 5 6 7 8 9 10 11 |
0: jdbc:hive2://localhost:10000> select * from mytable_partition; +-------------------------+--------------------------------+-------------------------------+-------------------------+--+ | mytable_partition.name | mytable_partition.login_times | mytable_partition.last_login | mytable_partition.date | +-------------------------+--------------------------------+-------------------------------+-------------------------+--+ | wen | 3 | 2016-02-03 10:10:00.0 | 2017-02-23 | | sha | 1 | 2016-02-01 10:00:00.0 | 2017-02-23 | | zhao | 1 | 2016-02-01 10:10:00.0 | 2017-02-23 | | ming | 4 | 2016-02-04 10:10:00.0 | 2017-02-23 | | xin | 2 | 2016-02-02 10:10:00.0 | 2017-02-23 | +-------------------------+--------------------------------+-------------------------------+-------------------------+--+ 5 rows selected (0.461 seconds) |
与之前相比,一方面我增加了where条件限制了时间,另一方面我指定将数据写入到date=2017-02-23分区下。下面,我们看一下partition对hdfs存储结构的影响是什么:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[root@localhost hadoop]# ~/hadoop/bin/hadoop fs -ls /user/hive/warehouse/myhive.db/mytable_partition Found 1 items drwxrwxr-x - root supergroup 0 2017-02-22 09:08 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23 [root@localhost hadoop]# ~/hadoop/bin/hadoop fs -ls /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23 Found 8 items -rwxrwxr-x 1 root supergroup 26 2017-02-22 09:07 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23/000000_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 09:07 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23/000001_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 09:07 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23/000002_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 09:07 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23/000003_0 -rwxrwxr-x 1 root supergroup 53 2017-02-22 09:07 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23/000004_0 -rwxrwxr-x 1 root supergroup 53 2017-02-22 09:07 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23/000005_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 09:08 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23/000006_0 -rwxrwxr-x 1 root supergroup 0 2017-02-22 09:08 /user/hive/warehouse/myhive.db/mytable_partition/date=2017-02-23/000007_0 |
发现多了一级目录,可见hive在partition级直接分离成了不同的目录,因此我们可以指定只查询特定的分区:
|
1 2 3 4 5 6 7 8 9 10 11 |
0: jdbc:hive2://localhost:10000> select * from mytable_partition where `date`='2017-02-23'; +-------------------------+--------------------------------+-------------------------------+-------------------------+--+ | mytable_partition.name | mytable_partition.login_times | mytable_partition.last_login | mytable_partition.date | +-------------------------+--------------------------------+-------------------------------+-------------------------+--+ | wen | 3 | 2016-02-03 10:10:00.0 | 2017-02-23 | | sha | 1 | 2016-02-01 10:00:00.0 | 2017-02-23 | | zhao | 1 | 2016-02-01 10:10:00.0 | 2017-02-23 | | ming | 4 | 2016-02-04 10:10:00.0 | 2017-02-23 | | xin | 2 | 2016-02-02 10:10:00.0 | 2017-02-23 | +-------------------------+--------------------------------+-------------------------------+-------------------------+--+ 5 rows selected (0.249 seconds) |
date就好像mytable_partition中的一列一样,可以直接使用where条件过滤,所以!=,<,>等都可以用在这里,分区让我们在一个更小的集合上进行mapreduce计算,因此更快。
SQL执行原理
主要是理解Hive如何将SQL语句转化成map-reduce进行计算,这方面的知识可以在《Hive SQL的编译过程》了解一下,主要包含3方面:
-
Join的实现原理
-
Group By的实现原理
-
Distinct的实现原理
其实无论是哪种SQL语法,最终都是在借助map-reduce的模型实现。所以思路都有一个共性:就是map给我们机会来拼接各种key,而reduce帮我们把长相相近的key排列在一起并且有序,基于这两个能力可以实现各种SQL功能。
谈到reduce,我认为必须强化一个对排序原理的认识:字符串排序是按前缀比较的。
3_1_1,3_23_1,3_22_1,3_12_1,这几个key应该怎么排序?
我们来理解排序过程:
- 这些key的前2个字符都一样,无法决定排列顺序;
- 第三个字符是1的:3_1_1,3_12_1聚集在一起,3_23_1,3_22_1聚集在一起,前2个排在后2个前面,因为1<2
- 3_1_1和3_12_1相比_和2不同,那么两者按字符顺序排列即可。
- 3_23_1和3_22_1相比3>2,所以3_22_1排在3_23_1前面。
前缀是排序的关键,想要让若干记录聚集在一起相邻存储,就一定要保证它们有相同的前缀。
JOIN原理
JOIN操作是将多个表的数据联合起来生成结果,对一个表的数据执行mapreduce并不难理解,对多个表怎么处理呢?
map-reduce支持多路输入,也就是指定多个数据源并且可以为每个数据源指定mapper函数,但reducer函数只能指定1个公共的,这是实现多表JOIN的基础。
在实际应用hive时,数据规模一般比较大,那么大量的数据从mapper处传输到reducer进行计算的过程对带宽和磁盘的资源利用率都是很高的,耗时必然很长,因此hive对JOIN操作做了比较多的优化设计,目的都是为了减少从mapper传给reducer的数据量,实现途径各种各样,下面一一说明。
建另外一张表用于JOIN
建一个mytable_other,它存储用户的年龄:
|
1 |
CREATE TABLE mytable_other (name string, age int ) CLUSTERED BY(`name`) INTO 8 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; |
并插入一条数据:
|
1 2 3 4 5 6 7 8 9 |
0: jdbc:hive2://localhost:10000> insert into mytable_other values("wen", 23); 0: jdbc:hive2://localhost:10000> select * from mytable_other; +---------------------+--------------------+--+ | mytable_other.name | mytable_other.age | +---------------------+--------------------+--+ | wen | 23 | +---------------------+--------------------+--+ 1 row selected (0.17 seconds) |
map-side join
我要JOIN的表是mytable和mytable_other,语句如下:
|
1 |
0: jdbc:hive2://localhost:10000> select * from mytable JOIN mytable_other on (mytable.name=mytable_other.name); |
执行语句,会发现打印出下面这些说明:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hive/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] 2017-02-22 19:27:08 Starting to launch local task to process map join; maximum memory = 518979584 2017-02-22 19:27:13 Dump the side-table for tag: 1 with group count: 1 into file: file:/root/hive/tmpdir/scratchdir/1fd8d922-624d-452d-a9eb-2d46fd1a7371/hive_2017-02-22_19-27-00_805_3492655435726062843-3/-local-10004/HashTable-Stage-3/MapJoin-mapfile01--.hashtable 2017-02-22 19:27:13 Uploaded 1 File to: file:/root/hive/tmpdir/scratchdir/1fd8d922-624d-452d-a9eb-2d46fd1a7371/hive_2017-02-22_19-27-00_805_3492655435726062843-3/-local-10004/HashTable-Stage-3/MapJoin-mapfile01--.hashtable (283 bytes) 2017-02-22 19:27:13 End of local task; Time Taken: 5.304 sec. +---------------+----------------------+------------------------+---------------------+--------------------+--+ | mytable.name | mytable.login_times | mytable.last_login | mytable_other.name | mytable_other.age | +---------------+----------------------+------------------------+---------------------+--------------------+--+ | wen | 3 | 2016-02-03 10:10:00.0 | wen | 23 | +---------------+----------------------+------------------------+---------------------+--------------------+--+ 1 row selected (40.684 seconds) |
关注到这句话:
|
1 |
Starting to launch local task to process map join; |
说明hive采用了map join,由于我的2个表数据都很少,所以hive认为可以把其中较小的一张表完全放入内存中,将其建立成key=name,value=row的hash表,并上传到hdfs某处。
之后,hive会对另外一张较大的表执行map-reduce计算,这个MR任务仅启动mapper而不启动reducer,这是因为在mapper里可以把之前保存有所有小表数据的Hashtable直接加载到mapper进程的内存里,这样大表的每行数据直接查hash表就可以完成name的匹配,产生JOIN的所有结果数据行了。
为了验证,我在浏览器访问hadoop的jobhistory server,查看这个MR任务的执行情况,发现只有1个mapper,没有reducer,这是因为map-side只需要对大表执行mapper,小表已经在内存,因此也不需要reducer阶段:
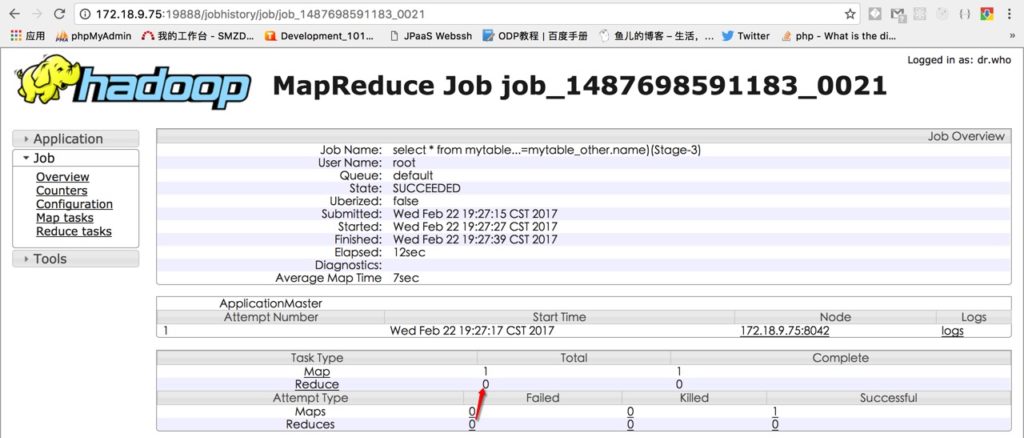
common join
map-side join只能在某张表很小,足以装进mapper内存里的情况下才能使用,而hive2.x版本默认已经开启了这个特性,所以刚才的SQL被默认优化。
如果2个表都很大,那么hive将使用最通用的common join,它需要使用mapper和reducer配合完成JOIN任务。为了演示,需要禁掉map-side join的优化选项:
|
1 |
0: jdbc:hive2://localhost:10000> set hive.auto.convert.join=false; |
再次执行查询,发现之前的那段提示不见了:
|
1 2 3 4 5 6 7 8 |
0: jdbc:hive2://localhost:10000> select mytable.name,login_times,last_login,age from mytable JOIN mytable_other on (mytable.name=mytable_other.name); WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. +---------------+--------------+------------------------+------+--+ | mytable.name | login_times | last_login | age | +---------------+--------------+------------------------+------+--+ | wen | 3 | 2016-02-03 10:10:00.0 | 23 | +---------------+--------------+------------------------+------+--+ 1 row selected (40.386 seconds) |
查看jobhistory,发现使用了2个mapper和1个reducer,这是因为1个mapper处理的是mytable,另一个处理的是mytable_other,而1个reducer则是对两2个mapper的结果进行JOIN:
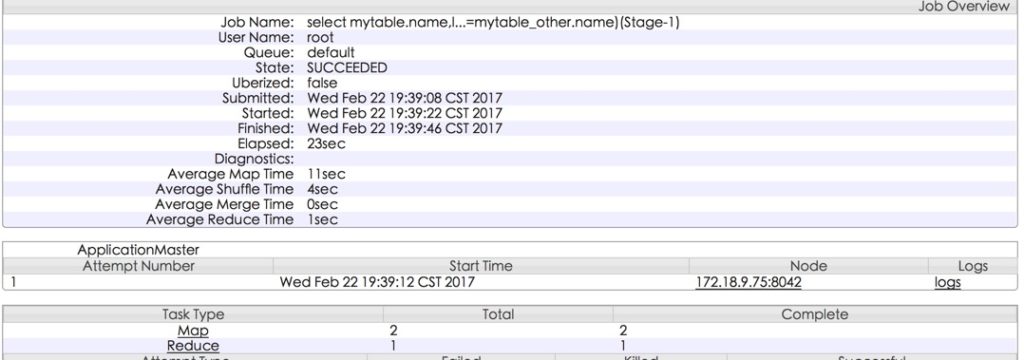
我们可以看一下2个mapper的输入数据:


详细分析一下:
- mytable的mapper的输出会以name为key,value为login_times,last_login,以及tag=mytable标识数据归属。
- mytable_other的mapper的输出会以name为key,value为age,以及tag=mytable_other标识数据归属。
- reducer在处理key=wen的时候,会遇到来自mytable和mytable_other的2行数据,将它们merge在一起输出即可。
如果同一个key在2张表里出现多次,那么JOIN的时候2张表同key的所有数据行都必须放在内存里进行m:n的交叉JOIN(笛卡尔乘积),通常来说没有那么多同key数据,因此reducer不太会因为这个原因OOM。
bucketd map-side join
这是map-side join的一个特殊版本,它将得益于bucket分桶。
在之前的map-side join例子中,位于JOIN左侧的mytable被视为大表,右侧的mytable_other是小表,hive将小表存储为一个哈希表序列化在hdfs上,然后大表的mapper会加载哈希表直接在内存中与大表的数据行进行JOIN。
假设mytable_other表刚好大到无法全部放进内存,那么map-side join就无法执行,但是如果我们把mytable和mytable_other这2个表都分成了8个桶的话,那么mytable_other的1个桶是原来的1/8大小,就可以完全放进内存了。
在这个前提下,我们可以为mytable_other的8个桶分别生成8个hash表,然后启动8个mapper分别处理mytable的8个桶,这8个mapper分别将mytable_other的8个hash表中对应自己的那一个加载到内存里,就可以继续执行map-side join。
能够这样做的原因是:2个表都按name哈希分成了8个桶,因此相同name的行一定在2个表的相同桶中,并且小表的1/8份数据又足以放入mapper内存,因此大表可以对每个桶启动一批mapper并且只加载小表对应桶的hash表,从而实现map-side join。
我们只需要修改hive-site.xml中的这项配置,hive就会试图优化为bucketd map-side join了(记得重启hive):
- hive.optimize.bucketmapjoin:true
在我的例子中,mytable_other只有1个桶中有数据,因此只需要启动1个mapper去处理mytable中对应的桶,而不需要为其他7个桶启动mapper,可见分桶还是很有意义的。
Sort Merge Bucket Map Join
无论是普通的map-side join还是bucketd map-side join,它们都要求小表的数据可以完全装入大表的mapper内存中。
如果希望实现2个大表的map-side join(只有mapper没有reducer),那么就可以使用Sort Merge Bucket Map Join这个优化技术。
实现Sort Merge Bucket Map Join的前提是:
- 2个表都需要分桶,并且2个表的桶数量成倍数关系:
- 比如A表3个桶,B表6个桶,那么A0与B0,B3对应,A1与B1,B4对应,A2与B2,B5对应,桶数量成倍可以让”hash(name)%桶个数”呈现出这样的对应关系,即B0里的name一定在A0里,而A0里的可能在B0或者B3桶内。
- 其次需要让每个桶内的数据有序,这是在建表时指定SORTED BY来实现的:
- 我们知道,要让一个桶内所有数据行有序,那么只能通过1个reducer进程才能实现,最终一个桶在hdfs上只对应一个有序的文件。
- 2个表分桶的字段,排序的字段,连接的字段,必须是同一个字段,这个在后面理解原理就很容易理解了。
在验证之前,我们首先让mytable和mytable_other的桶按name排序:
|
1 2 3 4 5 |
0: jdbc:hive2://localhost:10000> alter table mytable CLUSTERED BY(`name`) SORTED BY (`name`) INTO 8 buckets; No rows affected (1.956 seconds) 0: jdbc:hive2://localhost:10000> alter table mytable_other CLUSTERED BY(`name`) SORTED BY (`name`) INTO 8 buckets; No rows affected (0.334 seconds) |
现在,两个表的每个桶在hdfs中对应一个文件,并且桶内的行已经按照name有序排列。
当我们再次JOIN这两个表的时候,Hive不会以任何一个表(不再区分大小表)作为mapper的输入数据源而是直接启动8个没有输入源的mapper,每个mapper会直接访问hdfs打开mytable和mytable_other中相同下标的桶文件,因为每个桶文件只有1个并且数据行按name有序排列,所以mapper程序可以直接将2个hdfs文件顺序逐行读取到内存进行比较,如果name相同则JOIN为一行并输出,否则继续向后移动落后的文件指针,是很常见的归并排序原理。
默认Hive并不会自动优化SQL为Sort Merge Bucket Map Join(SMB),因此现在执行explain会看到执行计划为3步,仍旧只是普通的map-side join:
|
1 |
explain select mytable.name,login_times,last_login,age from mytable JOIN mytable_other on (mytable.name=mytable_other.name); |
|
1 2 3 4 5 6 7 8 9 |
... | STAGE DEPENDENCIES: | | Stage-4 is a root stage | | Stage-3 depends on stages: Stage-4 | | Stage-0 depends on stages: Stage-3 ... | Map Join Operator | | condition map: | | Inner Join 0 to 1 |
为了让Hive能够自动优化SQL为Sort Merge Bucket Map Join,需要修改hive-site.xml中的如下配置(记得重启hive):
- hive.optimize.bucketmapjoin.sortedmerge:true
- hive.auto.convert.sortmerge.join:true
前者含义是让hive支持SMB JOIN,后者是让Hive自动判断是否应该使用SMB,再次explain发现JOIN变为了SMB类型:
|
1 2 3 4 5 6 7 8 |
... | STAGE DEPENDENCIES: | | Stage-1 is a root stage | | Stage-0 depends on stages: Stage-1 ... | Sorted Merge Bucket Map Join Operator | | condition map: | | Inner Join 0 to 1 |
Skew Join
用于处理数据倾斜的场景,由于hadoop的map->reduce是按hash去分组的,难免会有造成不同reduce处理的数据量有所差异,这不仅是hive要面对的问题,也是编写map-reduce程序常见的问题,我们一般称为”长尾”。
hive除了正常的mapper散列不均匀外,在group by时由于业务数据本身特点极有可能造成”长尾”,举例来说:某些用户的登录可能极为活跃,造成这批用户的数据集中在某些reduce上,这些reduce的执行时间将会很长。
hive为了避免”长尾”问题,针对group by进行了优化,也就是将原本一次的map-reduce过程拆成2次,举例来说:第一次mr将属于同一个用户的记录随机散列到reducer,进行一次初步的合并,之后再发起第二次mr合并出最后结果。
当然,hive”倾斜”问题触发原因很多,具体场景需要具体分析,真正的Hive SQL之路还有很多很多技巧和经验问题,慢慢积累吧。
关于HS2
Hive2.x的HiveServer2提供thrift API进行SQL执行,有意思的是它提供background SQL能力,也就是任务可以提交给HS2进程,然后客户端立即返回,可以定期的通过thrift API去查询HS2任务的进度,这对于围绕Hive开发内部的Web平台很有帮助,可以参考官方文档。
祝玩的愉快
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1