谈谈全局唯一ID生成方法
在分布式系统中,经常需要用到全局唯一ID发生器,其特点是分配效率高,永远不会重复。
我这里分享几个简单思路,供大家参考。
snowflake方案
这个方案只依赖时钟(可以关掉时钟同步NTP),不依赖存储,生成的数字也没有明显规律可寻,订单系统比较偏爱。
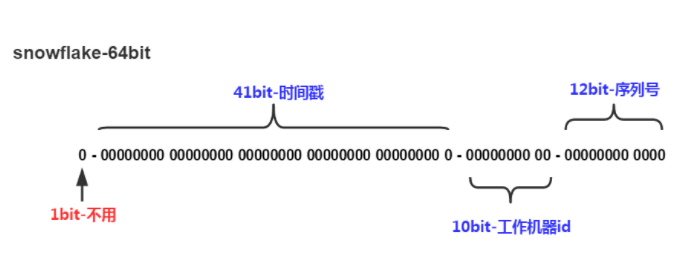
时间戳用当前时间的毫秒单位,工作机器id用于集群化部署用途,序列号在同一毫秒内递增,即一毫秒内最多生成4096个唯一ID。
一个简单的单线程异步网络程序就可以搞定了,集群化部署可以直接挂接在haproxy/lvs负载均衡下,ID生成整体趋势是递增的。
segment方案
这个方案的原型非常朴素:进程内存里维护一个”int id = 0″,每次请求”return id++”,即可返回顺序递增的ID。
缺点有2个:
- 进程宕机,下次重启不知道从哪个id继续自增。
- 平行扩展困难。
第1个问题容易解决,可以在return id++之前把当前id写到磁盘上备份一下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
int id; // 当前的id int gen_id() { // 1, 把id写到一个文件中 write(backup_file, id); // 2, 返回当前值, 并加1 return id++; } void recover_id() { // 1, 从文件中恢复id id = read(backup_file); // 2, 将下一个id作为起始 id++; } |
如果程序在任意位置宕机,下次重启后只需要从文件中恢复id,并从id=id+1开始继续工作即可。
第2个问题也可以巧妙解决,与snowflake算法中”工作机器id”目标相同。假设我评估5个进程可以满足业务请求量,那么可以给5个进程编号”A,B,C,D,E”,它们的起始ID分别是”0,1,2,3,4″,步长都是5,那么代码可以改成这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
int id; // 当前的id int gen_id() { // 1, 把id写到一个文件中 write(backup_file, id); // 2, id增加1个步长(步长5) int cur_id = id; id += 5; return cur_id; } void recover_id() { // 1, 从文件中恢复id id = read(backup_file); // 2, 将下一个id作为起始 id += 5; } |
A进程分配的ID序列将是:”0、5、10、15…”,B进程分配的ID序列将是:”1、6、11、16…”,规律一目了然。
当进程宕机重启后,从文件恢复得到id,并将id+=5作为起始ID,即可完全避免返回之前分配过的ID了。
优化
目前的做法还没有体现出segment的含义所在。回顾上述方案,为了容灾的目的,分配ID的第一步是把当前id备份到文件中,一旦涉及到磁盘IO必然会阻塞程序处理,降低QPS。
为了减少磁盘IO的频率,就需要提出segment段的概念。暂时不考虑集群化设计,单机版程序像这样工作:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
int id; // 当前分配的id int segment_max_id; // 段的最大id int gen_id() { // 1, 段耗尽,新生成段并备份到文件 if (id == segment_max_id) { segment_max_id += 10000; write(backup_file, segment_max_id); } // 2, 分配当前段中的id return id++; } void recover_id() { // 1, 从文件中恢复segment_max_id id = segment_max_id = read(backup_file); // 2, 指向段末尾 segment_max_id += 10000; } |
上述代码的segment长度是10000,也就是每分配10000个ID后才会写入一次磁盘,当然代价就是如果10000个ID没有分配完之前宕机,那么这一个段内的ID就跳过了,永远也没有机会分配到。
另外,上述代码在segment的长度为1的时候将蜕化为最初的i++版本,你可以分析一下。
最后一个疑问就是,如何把上述程序集群化?其实掌握了之前的步长设计后,基于segment的步长设计也是类似的。假设仍旧是A,B,C,D,E共5个进程组成集群,它们的起始ID分别是0、10000、20000、30000、40000,新的代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
int id; // 当前分配的id int segment_max_id; // 段的最大id int gen_id() { // 1, 段耗尽,新生成段并备份到文件 if (id == segment_max_id) { // 前进1个步长 id = segment_max_id = segment_max_id + (5 - 1) * 10000; // 更新段最大id segment_max_id += 10000; write(backup_file, segment_max_id); } // 2, 分配当前段中的id return id++; } void recover_id() { // 1, 从文件中恢复segment_max_id id = segment_max_id = read(backup_file); // 2, 指向段末尾 segment_max_id += 10000; } |
关注差异的代码部分,看一下例子就理解了:
A分配的段序列是:[0,10000)、[50000,60000),[100000,110000]….
B分配的段序列是:[10000,20000)、[60000,70000)、[110000,120000)…
C分配的段序列是:[20000,30000)、[70000,80000)、[120000,130000)…
关于segment的原理就这么多,但是基于segment方法的集群和基于snowflake方法的集群是有使用场景差异的:
- segment集群直接对接haproxy/lvs负载均衡的话,可能导致不同进程的ID分配进度不同(比如都请求到进程C),从而导致集群整体ID无法呈现整体自增趋势,因此一般需要自己研发一个proxy来控制A,B,C,D,E之间的ID分配进度,目标是大家已分配的segment段数量接近相同,那么集群整体ID趋势就是自增的。
- segment集群分配的ID容易暴露业务量,因为它是整形区间的顺序增加,很容易根据同一天早晚的ID差值估算业务量。
- segment方案需要持久化存储,磁盘文件也存在可靠性问题,可以考虑双重保险的方案,也就是定期异步的把当前segment序号保存到数据库或者某处,这样即便磁盘故障,也可以基本估算出故障前的segment序号,从而在恢复进程时选择一个较大的segment号继续分配。
优惠券批量生成
电商系统通常需要用到优惠券或者兑换码之类的东西,例如:京东E卡的卡密长这样,
DJZ3-0PLF-C0E8-L0UF
京东E卡是实物卡,如果卡密有规律可循将带来惨重的损失,因此其生成算法必须是完全随机的。
我们知道,生成随机整数的方法大多数语言都是支持的,它们没法保障100%的不重复,因此只能接受这个事实。
假设我们可以随机生成不重复的整数,那么又该如何转换成上述”字母+数字”的混合字符串形势呢?答案是:36进制。36进制数的表达区间是0-9,A-Z(a-z),恰好满足要求。
因此,我的方法是用随机函数生成长整形并转换成36进制,但是一个长整形的36进制位数长度不够,所以就产生2个36进制随机数拼接起来,取前面的部分即可。
一段PHP代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<?php function gen_coupon() { do { $m = mt_rand(0, PHP_INT_MAX); $n = mt_rand(0, PHP_INT_MAX); $m = base_convert($m, 10, 36); // 主随机 $n = base_convert($n, 10, 36); // 辅随机 $r = substr($m . $n, 0, 16); } while(strlen($r) != 16); $r = strtoupper($r); $r = str_split($r, 4); $r = implode('-', $r); return $r; } |
这样做冲突率能有多高呢?我生成了5000万个券码,重复了20个,问题不大。
接下来的问题是,如何把这批券码保存到数据库呢?因为重复难以避免,但冲突率又低的可怜,总不能为了20条冲突的数据去数据库进行5000万次查询判重吧?
如果粗暴的批量insert,那么碰到重复的券码就会由于唯一索引报错终止,怎么办呢?解决办法也足够暴力,insert语句使用on duplicate key update 语法,当遇到唯一索引冲突时做一个无意义的update更新即可:
|
1 |
insert into coupon(`code`) values('xxxx-xxxx-xxxx-xxxx') on duplicate key update `code`='xxxx-xxxx-xxxx-xxxx'; |
这样就可以直接利用mysql客户端批量导入,或者用脚本程序分批的导入数据库了。
领取优惠券
从数据库里随机取一个优惠券并不容易,当多个程序并发的查询数据库获取优惠券时,大家会拿到同一个优惠券,显然对数据库上锁是不合理的做法。
我分享一个低成本的方案:可以把优惠券保存到redis的set结构中,它可以保证key的唯一性,并且支持spop这个命令随机返回并删除一个key。最终的领券程序,应该是从redis set中获取一个券码,然后去mysql中将其据为己有的一个执行流程。
可是问题并没有结束,redis中的优惠券是一次性取走的模式,因此在向redis灌入优惠券的时候并不知道是否与历史上的某个优惠券有冲突,这该怎么办呢?我们知道,此前灌数据库的时候借助mysql的唯一索引实现了去重,那么基于数据库的新增记录去灌redis就不会与历史数据冲突了。
接下来的问题变成:如何在mysql中发现新增的优惠券呢?可以在mysql中设置一列,唯一性表示本次操作,这样就可以写一个脚本扫出所有属于本次的记录灌入到redis中去了。
另外一个值得考虑的问题是异常:
- 灌mysql异常没有关系,重新执行即可,因为mysql有券码唯一性,并且此时redis里没有数据,不可能有用户可以取到其中的优惠券。
- 灌redis异常需要注意,如果在灌redis期间有用户访问这个redis set取走了一些优惠券,那么灌redis异常终止后就不能重新全量回灌了,否则会导致后续用户取到已经使用的券码。我建议每次批量生成优惠券的时候,都在redis里新建set,当成功灌完这个set后再生效到线上。因此,需要取券程序做一些设计,比如配置几个备用的券码池(redis set),当老的池子取空后再来新池子。
上面的整个流程,完全可以自动化,即将创建券码动作做一个计划任务保存在mysql中,利用定时任务来完成券码的批量生成 -> 灌入mysql -> 灌入redis -> 生效到线上券码池。
本文纯属意淫,欢迎留言交流。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

炮哥666
不错,很受教。
1
1