PHP7扩展开发教程[9] – 如何使用哈希表?
确保你已阅读《PHP7扩展开发教程[8] – 如何访问超级全局变量?》。
哈希表即zend_array数据结构,它是zval的底层数据类型之一,也是最为复杂的一个结构。
在PHP中的array()即可以表达数组,又可以表达字典,这样的灵活性在zend_array中都有对应的代码实现。
理论先行
鉴于已经有很不错的博客介绍了PHP7的zend_array,所以本章开始前请先自己学习一下这篇文章:
这里盗用一张网上的图片,是一张比较清晰的PHP7 hashtable结构示意图:
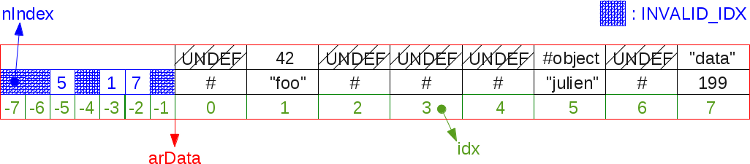
从图片来看,arData左侧部分是uint32的哈希桶,右侧是按插入顺序排列的Bucket元素列表,整体来看还是很清晰的。
下面,我将根据上述博客中的几个知识点,对相关的核心代码进行展开讲解,希望可以作为一个补充帮助你进一步理解zend_array的实现原理。
先看数据结构:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
typedef struct _Bucket { zval val; zend_ulong h; /* hash value (or numeric index) */ zend_string *key; /* string key or NULL for numerics */ } Bucket; typedef struct _zend_array HashTable; struct _zend_array { zend_refcounted_h gc; union { struct { ZEND_ENDIAN_LOHI_4( zend_uchar flags, zend_uchar nApplyCount, zend_uchar nIteratorsCount, zend_uchar consistency) } v; uint32_t flags; } u; uint32_t nTableMask; Bucket *arData; uint32_t nNumUsed; uint32_t nNumOfElements; uint32_t nTableSize; uint32_t nInternalPointer; zend_long nNextFreeElement; dtor_func_t pDestructor; }; |
分别讲解一下zend_array各个字段的含义,这对于理解它极为重要。
- gc:引用计数字段,和zend_string等都一样。
- u:各种标记位,主要关注flags,例如:是否分配持久化内存HASH_FLAG_PERSISTENT,是否完成初始化HASH_FLAG_INITIALIZED,是否为压缩数组HASH_FLAG_PACKED。
- nTableMask:哈希桶的个数。
- arData:顺序数据存储空间。
- nNumUsed:arData已使用的槽位数量,可能中间有空槽。
- nNumOfElements:arData实际存储的有效数据个数。
- nTableSize:arData的总槽位数量。
- nInternalPointer:遍历zend_array的迭代器指针,zend_array支持迭代器,我们不研究它了。
- nNextFreeElement:追加整形索引的数据时,它是下一个整形下标。
- pDestructor:一个回调函数,当覆盖/删除一个key或者释放zend_array时,用于释放Bucket中的val。
Bucket是arData顺序数组里的元素类型。
- val:存储的zval数据。
- h:当元素保存在整形下标时,下标保存在该字段,并且本身充当hash值,对其取模得到哈希表的槽位。
- key:当保存的key是字符串时,保存在该字段,通过某个哈希算法生成hash值保存到h字段,对h取模得到哈希表的槽位。
上面的罗列的信息主要是作为下面的参考,下面具体透过代码来看zend_array的几个核心设计。
zend_array采用了”懒惰”的初始化策略。举例来说,我们在PHP代码里的生成数组$arr = array(),在真正向其赋值内容之前,Zend并不知道我们要存储的内容是键值字典还是普通数组,或者是两者都有。
在zend_array的设计中,如果array是纯粹的整形下标数组,那么完全可以采用packed策略,免去哈希桶的存储空间和操作。下标h直接存储在arData[h]中,这种直接定位的性能非常高。
如果array是键值字典,那么就需要利用hash桶来索引键。下标h或者hashFunction(key)经过取模后定位到hash桶,通过遍历桶内的Bucket链表,最终找到要找的下标h或者键key对应的值,这种性能肯定慢于packed array。
“懒惰”初始化的原理,就是在用户首次操作zend_array的时候,根据其插入的是键值还是整形下标,决定zend_array的初始类型是hash array还是packed array。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC) { GC_REFCOUNT(ht) = 1; GC_TYPE_INFO(ht) = IS_ARRAY; ht->u.flags = (persistent ? HASH_FLAG_PERSISTENT : 0) | HASH_FLAG_APPLY_PROTECTION | HASH_FLAG_STATIC_KEYS; ht->nTableMask = HT_MIN_MASK; HT_SET_DATA_ADDR(ht, &uninitialized_bucket); ht->nNumUsed = 0; ht->nNumOfElements = 0; ht->nInternalPointer = HT_INVALID_IDX; ht->nNextFreeElement = 0; ht->pDestructor = pDestructor; ht->nTableSize = zend_hash_check_size(nSize); } |
上面的方法完成”懒惰”初始化,arData并没有分配实际内存,并且这个zend_array的类型也没有确定。
接下来,当我们调用任意插入/更新zend_array的函数时,它们的函数头部都会检查zend_array是否已经”真正”初始化,如果没有则立即初始化。这个检查方法是这样的:
|
1 2 3 4 5 6 7 8 9 10 |
static zend_always_inline void zend_hash_check_init(HashTable *ht, int packed) { HT_ASSERT(GC_REFCOUNT(ht) == 1); if (UNEXPECTED(!((ht)->u.flags & HASH_FLAG_INITIALIZED))) { zend_hash_real_init_ex(ht, packed); } } #define CHECK_INIT(ht, packed) \ zend_hash_check_init(ht, packed) |
它是通过判断zend_array的flags里是否有HASH_FLAG_INITIALIZED来判定的,最终通过zend_hash_real_init_ex完成”真正”的初始化:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
static zend_always_inline void zend_hash_real_init_ex(HashTable *ht, int packed) { HT_ASSERT(GC_REFCOUNT(ht) == 1); ZEND_ASSERT(!((ht)->u.flags & HASH_FLAG_INITIALIZED)); if (packed) { HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_PERSISTENT)); (ht)->u.flags |= HASH_FLAG_INITIALIZED | HASH_FLAG_PACKED; HT_HASH_RESET_PACKED(ht); } else { (ht)->nTableMask = -(ht)->nTableSize; HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_PERSISTENT)); (ht)->u.flags |= HASH_FLAG_INITIALIZED; if (EXPECTED(ht->nTableMask == (uint32_t)-8)) { Bucket *arData = ht->arData; HT_HASH_EX(arData, -8) = -1; HT_HASH_EX(arData, -7) = -1; HT_HASH_EX(arData, -6) = -1; HT_HASH_EX(arData, -5) = -1; HT_HASH_EX(arData, -4) = -1; HT_HASH_EX(arData, -3) = -1; HT_HASH_EX(arData, -2) = -1; HT_HASH_EX(arData, -1) = -1; } else { HT_HASH_RESET(ht); } } } |
第一个if分支是初始化为packed array,首先通过pemalloc分配一大段内存,它包含左侧2个uint32的hash桶(这2个hash桶对packed array实际上没有任何用处),以及右侧的nTableSize个Bucket槽位。
再通过宏HT_SET_DATA_ADDR把Bucket起始的内存地址赋值给arData,而arData左侧的内存就是2个uint32的hash桶。
第二个If分支初始化为hash array,首先令hash桶个数nTableMask等于Bucket数据槽位个数nTableSize。然后通过pemalloc分配一个包含nTableSize个uint32的hash桶 + nTableSize个Bucket的数据槽位的内存段。
最终,通过宏HT_SET_DATA_ADDR把Bucket的起始内存地址赋值给arData,并将所有hash桶的链表next初始化为-1。
zend_array的各种插入与更新方法,最终都依靠如下2个函数实现。
第1个函数用于向zend_array插入/更新”键-值”,它接受zend_string的key:
|
1 |
static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag ZEND_FILE_LINE_DC) |
第2个函数用于向zend_array插入/更新”下标-值”,它接受zend_ulong的key:
|
1 |
static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag ZEND_FILE_LINE_DC) |
以第2个函数为例,它非常能说明zend_array的背后原理:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag ZEND_FILE_LINE_DC) { uint32_t nIndex; uint32_t idx; Bucket *p; IS_CONSISTENT(ht); HT_ASSERT(GC_REFCOUNT(ht) == 1); if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { CHECK_INIT(ht, h < ht->nTableSize); if (h < ht->nTableSize) { p = ht->arData + h; goto add_to_packed; } goto add_to_hash; } else if (ht->u.flags & HASH_FLAG_PACKED) { if (h < ht->nNumUsed) { p = ht->arData + h; if (Z_TYPE(p->val) != IS_UNDEF) { if (flag & HASH_ADD) { return NULL; } if (ht->pDestructor) { ht->pDestructor(&p->val); } ZVAL_COPY_VALUE(&p->val, pData); if ((zend_long)h >= (zend_long)ht->nNextFreeElement) { ht->nNextFreeElement = h < ZEND_LONG_MAX ? h + 1 : ZEND_LONG_MAX; } return &p->val; } else { /* we have to keep the order :( */ goto convert_to_hash; } } else if (EXPECTED(h < ht->nTableSize)) { |
在第1个if分支中,判断zend_array没有”真正”初始化,那么就调用CHECK_INIT宏完成”真正”初始化。
到底是初始化为packed or hash array,是根据插入的下标zend_ulong h和zend_array的arData空间总大小决定的。
这个判定道理很简单,假设传入的zend_ulong h = 10000,那么packed array就要分配10000个Bucket并把这个数据存储到arData[9999],显然packed array并不适合这种存储场景,所以在这种场景下代码会将array初始化为hash array。
在第2个分支中,判断zend_array本身就是一个packed array。紧接着,代码判断h位置是此前已经使用过的槽位(nNumUsed之前)还是尚未使用的槽位(nNumUsed之后)。对于后者的处理非常简单,只需要将值填充到尚未使用的槽位中并令nNumUsed后移即可。对于前者,我们需要特别的来看一看。
它首先判断这个旧槽位是否有值占用,如果有旧值占用,那么先释放旧值,再填充新值。如果没有值占用,说明这个槽位之前填充过数据后来又被删除了,此时代码并没有直接将新值填充进去,这是为什么呢?
代码中注释: we have to keep the order ,其实这涉及到zend_array的一个语义保证。zend_array要求自身,新插入的新值,总是可以在遍历数组时最后一个遇到,我们的PHP数组就是这样工作的,你可以自己试试。
我们知道,遍历zend_array的方法就是顺序扫描arData,如果我们直接将新值填充到一个旧槽位arData[h]中,那么假设arData[h + 1]中本来也已经填充了数据,那么遍历zend_array时最后一个元素就是arData[h+1]而不是我们的arData[h],这显然违背了语义。
正因为这个问题,代码中立即跳转到convert_to_hash位置,调用了zend_hash_packed_to_hash方法将这个packed array转换成了等效的hash array。我们知道,hash array总是在arData + nNumUsed位置追加新值,并在hash桶中建立索引,所以保障了后插入后遍历的语义。
packed array向hash array的转换原理很简单:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
ZEND_API void ZEND_FASTCALL zend_hash_packed_to_hash(HashTable *ht) { void *new_data, *old_data = HT_GET_DATA_ADDR(ht); Bucket *old_buckets = ht->arData; HT_ASSERT(GC_REFCOUNT(ht) == 1); ht->u.flags &= ~HASH_FLAG_PACKED; new_data = pemalloc(HT_SIZE_EX(ht->nTableSize, -ht->nTableSize), (ht)->u.flags & HASH_FLAG_PERSISTENT); ht->nTableMask = -ht->nTableSize; HT_SET_DATA_ADDR(ht, new_data); memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed); pefree(old_data, (ht)->u.flags & HASH_FLAG_PERSISTENT); zend_hash_rehash(ht); } |
通过pemalloc重新分配一个内存段,它包含左侧nTableSize个uint32组成的hash桶,以及右侧nTableSize个Bucket组成的arData,最后调用zend_hash_rehash根据当前的Bucket元素,重建左侧的hash索引。
另外,通过上面的代码也能够看出另外一件事实:packed array只适合连续的向末尾追加整形下标数据,向前赋值或者插入非整形下标数据都将导致packed array蜕化为性能更差的hash array。
实践环节
zend_array的API实在太多了(Zend/zend_hash.h),因此在本章我着重的介绍了zend_array的原理,而不是罗列大篇幅的API。
现在请打开代码:https://github.com/owenliang/php7-extension-explore/tree/master/course9-how-to-work-with-zend-array。
为了帮助大家快速上手zend_array,我还是准备了几个简短的例子给大家。
我注册了一个全局函数:zif_myext_test_array,下面拆解开来,简单的讲一下常用的一些zend_array API。
|
1 2 3 |
// init arr zval arr_zval; assert(array_init(&arr_zval) == SUCCESS); |
这样初始化数组(懒惰初始化),其底层实现我们已经见过:
|
1 2 3 4 5 6 |
ZEND_API int _array_init(zval *arg, uint32_t size ZEND_FILE_LINE_DC) /* {{{ */ { ZVAL_NEW_ARR(arg); _zend_hash_init(Z_ARRVAL_P(arg), size, ZVAL_PTR_DTOR, 0 ZEND_FILE_LINE_RELAY_CC); return SUCCESS; } |
其中资源销毁函数传递了ZVAL_PTR_DTOR,其实就是zval_ptr_dtor,在之前的章节也提到过。
|
1 2 3 |
// add k-v add_assoc_long(&arr_zval, "date", 20170811); assert(zend_hash_str_exists(arr_zval.value.arr, "date", sizeof("date") - 1)); |
向array添加键值类型的数据,可以通过add_assoc_xxx系列便捷函数实现,它们底层最终调用了:
|
1 2 3 4 5 6 7 8 |
ZEND_API int add_assoc_long_ex(zval *arg, const char *key, size_t key_len, zend_long n) /* {{{ */ { zval *ret, tmp; ZVAL_LONG(&tmp, n); ret = zend_symtable_str_update(Z_ARRVAL_P(arg), key, key_len, &tmp); return ret ? SUCCESS : FAILURE; } |
zend_hash_str_exists用于判断一个key是否存在,对应的zend_hash_index_exists用于判断整形下标是否存在。
向下一个整形下标添加一条数据:
|
1 2 |
// add v assert(add_next_index_string(&arr_zval, "hahaha") == SUCCESS); |
zend_array内部维护了我们最后一个整形下标的大小,键值类型不会影响整形下标的自增,所以”hahaha”被保存在了整形下标0。
像这样获取数组的元素个数,就和PHP的count一样:
|
1 2 |
// arr count assert(zend_hash_num_elements(arr_zval.value.arr) == 2); |
接下来遍历zend_array,根据我们对zend_array数据结构的了解,只需要遍历Bucket *arData数组即可。需要注意的是,删除的元素会留下空白的槽位,其类型是IS_UNDEF,我们需要跳过:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// traversal arr zend_array *arr = arr_zval.value.arr; int i; for (i = 0; i < arr->nNumUsed; ++i) { zval *val = &(arr->arData[i].val); // handle indirect zval if (Z_TYPE_P(val) == IS_INDIRECT) { val = Z_INDIRECT_P(val); } // empty slots if (Z_TYPE_P(val) == IS_UNDEF) { continue; } if (arr->arData[i].key) { // must be array["date"] TRACE("arr['%.*s']=%ld", arr->arData[i].key->len, arr->arData[i].key->val, val->value.lval); } else { // must be array[0] TRACE("arr[%ld]=%.*s", arr->arData[i].h, val->value.str->len, val->value.str->val); } } |
在遍历的过程中,我们判断Bucket.key=NULL说明是整形下标关联的数据(下标保存在h字段),否则说明是字符串索引的数据,我们将其内容分别输出。
那么,IS_INDIRECT又是什么呢?这是一个特殊类型的zval,叫做”间接zval”。据鸟哥说明,这种zval主要用在Zend引擎内部,zval.value.zv中保存了另外一个zval的地址,其实我也知道什么情况下会碰到这种zval,你大可先不实现这段代码,等到遇到了再加上也不迟。
查找一个key:
|
1 2 3 |
// find key zval *zv_in_arr = zend_hash_str_find_ind(arr_zval.value.arr, "date", sizeof("date") - 1); assert(zv_in_arr->value.lval == 20170811); |
删除一个key:
|
1 2 |
// del string key assert(zend_hash_str_del(arr_zval.value.arr, "date", sizeof("date") - 1) == SUCCESS); |
删除一个下标:
|
1 2 |
// del index key assert(zend_hash_index_del(arr_zval.value.arr, 0) == SUCCESS); |
最后,记得释放arr自身,它会对每个保存的value调用pDestructor回调方法释放资源,默认行为就是释放一个引用计数,所以你就不必事必躬亲了。
|
1 2 |
// release arr zval_ptr_dtor(&arr_zval); |
你会发现,packed array这个优化对于开发者来说是完全透明的,我们并不需要在意它的存在。
结语
本章你应该掌握:
- zend_array的数据结构与原理。
- zend_array常见的API用法。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1