基于leveldb谈谈MVCC多版本控制
最近接触存储的原理比较多,MVCC也是存储系统常用的技术手段。
MVCC多版本是一个解决并发问题的模型,或者说是一种设计思路。
why
如果有一份数据,无论它是存储在内存里还是磁盘上,当我们读取数据时可能有写操作正在修改它。传统思路就是将数据用一把互斥锁保护起来:
- 读之前锁住,这样就不会有写操作。
- 写之前锁住,这样就不会有读操作。
如果数据是内存里的一个哈希表,那么锁的代价还可以忍受,几乎总是瞬间可以完成。
然而存储系统一般都要和磁盘打交道,读请求是从磁盘上读取一个文件的某个偏移量,写请求可能需要删除旧的文件并创建一个修改过的新文件(一般存储不会覆盖修改数据,因为异常时可能写坏数据)。
如果仍旧为了保护数据而上锁,那么磁盘的缓慢操作将导致锁占用时间很长,从而直接降低了系统吞吐。如果不上锁,那么极有可能正在读某个文件的同时,文件被删除了,导致严重错误。这就是MVCC多版本技术出现的背景环境。
how
这里以leveldb为例,简明扼要的说明其MVCC的实现原理,相关技术文档在这里阅读:《leveldb实现解析.pdf》。
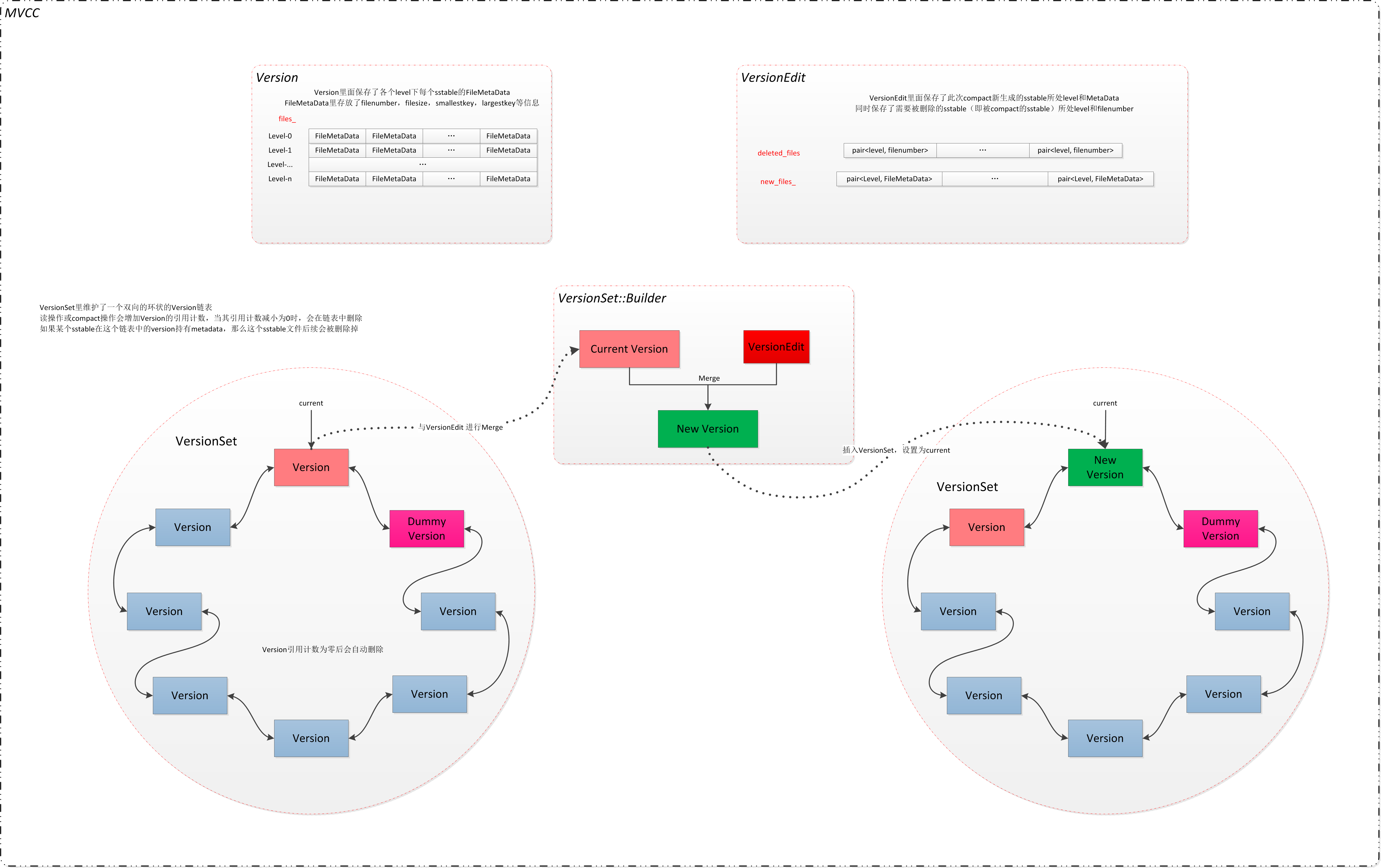
这里盗图一张,它描述了leveldb的多版本设计原理。这里可能很多同学没接触过leveldb,我会简单讲一下其原理。
leveldb是一个K-V存储引擎,具有很高的读写性能,我们不谈其存储细节,只介绍几个与MVCC相关的核心概念来帮助理解。
- 写请求首先保存在内存中,当达到一定体积后写到磁盘上的sst文件中。
- 读请求首先在内存中查找,没找到则去磁盘上的若干sst文件中查找。
- 磁盘上的sst文件不断增加,会有策略job定时的将N个sst文件合并为1个更大的sst文件。
假设一个场景:读操作会去磁盘扫描sst文件查找对应的数据,而策略job可能恰好正在合并遍历中的某sst文件,同时向合并后的sst文件输出中,最后还会删除掉旧的sst文件。这意味着,正在读的sst文件可能被删除,或者正在输出中(不完整)。
按照我们悲观锁的思路,直接加一把大锁,那么读请求期间写请求无法进行,漫长的写期间读请求不能进行,基本这个leveldb就没法用了。
leveldb采用MVCC避免大锁,这里引入了几个概念:
- version edit:记录sst文件集合的变化。当合并N个sst生成1个大sst,被合并的sst不再有意义,合并生成的新sst包含了它们的数据,version edit记录的就是:合并了哪些sst,新增了哪个sst。
- version:代表一个版本,记录了数据库由哪些sst文件组成。当磁盘合并发生后,对应的version edit施加到最新的version上,从而产生新的version,它记录了当前最新的数据库sst集合。
- version set:指向最新的version。
大概了解上述抽象概念后,我们直接说明MVCC的设计原理。
version set全局唯一,其中current_指针指向最新的version:
|
1 2 3 4 5 6 7 8 9 10 |
VersionSet { // 实际的 Env Env* const env_; // db 的数据路径 const std::string dbname_; // 正在服务的 Version 链表 Version dummy_versions_; // 当前最新的的 Version Version* current_; |
这是version版本,files_保存了该版本数据库的所有sst文件。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
class Version { ...... // 属于的 VersionSet VersionSet* vset_; // 链表指针 Version* next_; Version* prev_; // 引用计数 int refs_; // 每个 level 的所有 sstable 元信息。 // files_[i]中的 FileMetaData 按照 FileMetaData::smallest 排序, // 这是在每次更新都保证的。(参见 VersionSet::Builder::Save()) std::vector<FileMetaData*> files_[config::kNumLevels]; |
next_,prev_是链表,说明多个version是串在一起的。这里就容易产生几个好奇:
- 为什么会有多个version?
- version是怎么产生的?
回想合并的过程,N个sst文件merge到1个sst文件后,虽然N个sst文件已经没有意义,但是leveldb并不会立即删除它们,这是为什么呢?这就涉及到读请求了。
某个时刻,读请求会根据version set里的current_找到最新version,并在这个version里保存的sst文件集合中寻找目标数据。此后假设发生了合并并产生了新的version,新version将更新到version set的current_字段成为新的链表头。如果此时立即删除被合并的sst文件,那么正在进行中的读请求就会出错,所以删除sst文件的动作并不是立即发生的。同时,因为读请求依据的是旧版本的version(sst文件集合),所以新合并生成的sst并不会被该读请求扫描到。
是不是已经有点多版本控制的感觉了?
在实现上来说,读请求引用了旧版本的version,而写请求需要设置新版本的version,那么旧版本的version何时释放内存呢?这里就采用了引用计数机制,最新的version默认是1个引用计数并保存在version set的链表头部(current_),当读请求到来后会对version set的current_增加1个引用计数。此后发生合并生成新version替换current_时,先释放旧version的1个引用计数(还剩余1个由读请求持有),然后替换current_为新的version对象。
当读请求结束后,会释放旧version的最后1个引用计数,此时引用计数降低为0,旧版本version进入析构函数。这里涉及另外一个重要设计,我们知道之前写请求(合并sst)完成时并没有删除被合并的sst文件,其目的是因为之前的读请求可能正在访问旧sst文件,特意延迟了删除操作。
那么,删除应该延迟到什么时候呢?其实只要涉及到这种资源持有问题一般都是采用引用计数,在version中的files中保存的FileMetaData也是基于引用计数的共享内存。
当合并旧version+version edit生成新version时,旧version中没有被合并的sst文件对应的FileMetaData的引用计数将+1并保存到新version中,而被合并的sst文件的FileMetaData的引用计数保持不变并且也不保存到新version中。当替换current_为新version时候会首先释放旧version的1个引用计数从而进入旧version析构。在version析构中,会释放每个FileMetaData的1个引用计数,对于那些在新version中已经被合并的sst文件来说,引用计数减少为0将完成最终删除。
可见,leveldb的MVCC实际上由几个重要部分组成:
- sst文件的不变性:只合并生成新sst而不覆盖旧的,保障多版本都可以读到属于自己的数据。
- version引用计数:保证某版本所有sst文件的资源有效性。
- FileMetaData引用计数:保证单个sst文件在多version下的资源有效性。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

在Compact完成之后会直接删除sstable文件 怎么确保迭代器遍历时文件还在??对于1-7层leveldb采取的是延迟打开策略,即使是对于level0层刚开始也仅仅读了index_block
1
1