zipkin原理与对接PHP
之前写过一篇博客介绍分布式调用链trace的设计,今天拿开源项目zipkin为例实践一次,加深对相关概念理解。
理论
zipkin遵从谷歌dapper的设计论文,在这里阅读中文版《Dapper,大规模分布式系统的跟踪系统》。
接着,可以看一下这篇博客,它帮助你快速将dapper中的理论映射到zipkin的实践中去:《分布式跟踪系统(一):Zipkin的背景和设计》。
最后,官方主页其实面面俱到并且简明扼要的说明了zipkin的方方面面,之前阅读的知识点在里面都有正式说明,一定要仔细读完,反复体会:http://zipkin.io/。
我在这里就不复述zipkin是怎么维护调用链的了,但是下面几个关键概念是我认为很影响理解的,如果你不能理解,那么最好再回头读读文章:
- span代表一次RPC调用,关联2个节点,是调用链的一条边。
- 1个完整的span,是由client调用方、server被调用方分别提供信息共同拼凑而成的。
- 1个完整的span应该包含4个annotation:cs/sr/ss/cr,但是不完整也是可以接受的,例如:
- 浏览器发起的span,没有cs与cr。
- 向mysql发起的span,没有ss和sr。
- span代表一个RPC,那么span的parent span代表上一级RPC,所有span都是RPC而不是节点。
PHP对接zipkin
zipkin服务端无状态,只需要下载一个jar包即可启动,启动多个实例负载均衡也是可以的。
这里用作演示,按照官方指导下载启动一个服务端实例即可,它默认将上报的日志数据保存在内存里:http://zipkin.io/pages/quickstart.html。
启动zipkin后,浏览器打开http://localhost:9411访问web UI。
zipkin支持HTTP协议上报span,在这个文档中详细描述了各个关键数据结构,以及client和server在上报Span时的字段和注意事项:http://zipkin.io/zipkin-api/#/。
我在github上传了一份测试代码,它的目的并不是封装zipkin客户端,而是基于zipkin的原理以及上报协议来模拟一个调用链场景,从而可以在zipkin的web UI上可以看到可视化的效果,并且更重要的是可以看到zipkin是如何保存我们上报的span数据来满足各种trace查询需求的。
代码讲解
我模拟的场景是这样的:浏览器访问了a.service.com/method_of_a,在这个方法里先RPC调用b.service.com/method_of_b接口,然后再调用mysql.service.com执行一次mysql查询。
在命令行执行client.php,可以在web UI上看到如下效果。
在这个页面中,可以搜索到所有annotation中endpoint出现过a.service.com的span,也就是说:
- 可能span是a.service.com被调用
- 可能span是a.service.com发起调用他人
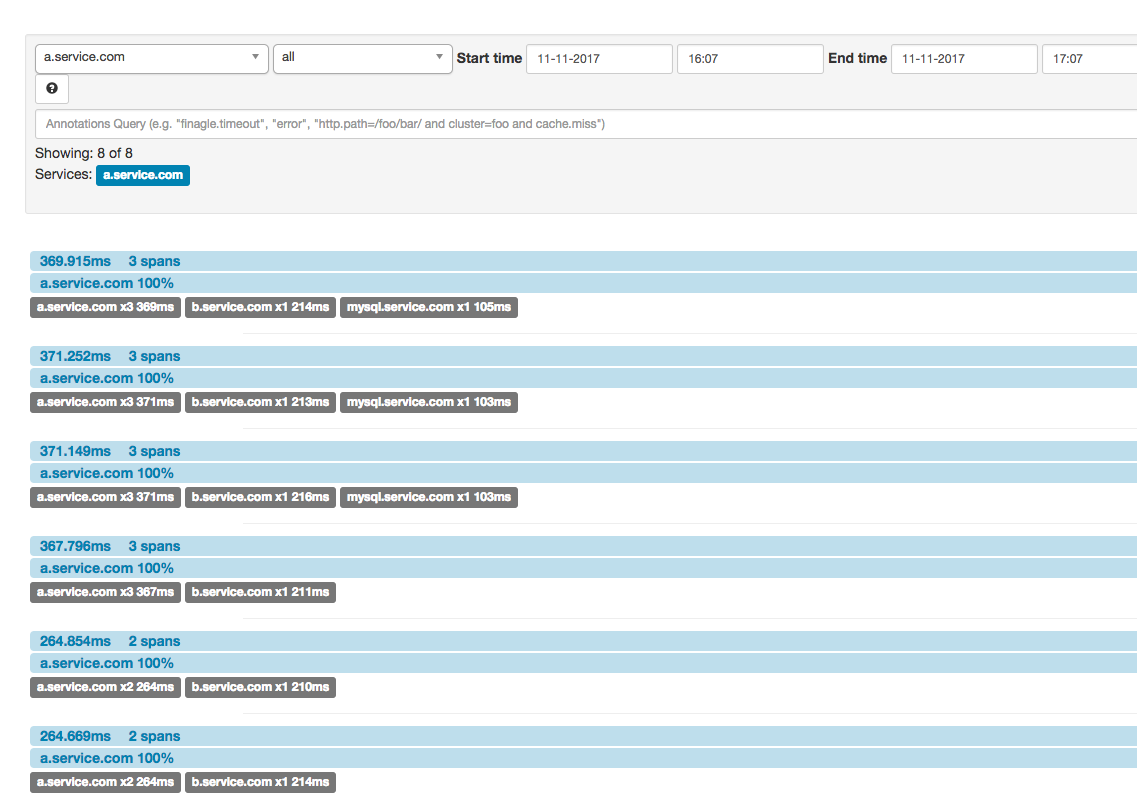
当点击第一个项时,会根据span所属的traceid得到整个调用链的完整时间轴和调用关系,也就是traceid下所有span。

从这张图可以看出,a.service.com先后调用了b.service.com和mysql.service.com,分别花费了一些时间,最后返回给浏览器之间自己处理又花费了一段时间。
接下来说说这里面有几个span。
span1
浏览器调用a.service.com是一个RPC,应该对应一个span。client是浏览器,server是a.service.com,但是浏览器并没有调用链上报的功能,所以无法收集到cs和cr两个关键信息。
但是为了描述出a.service.com处理这个RPC的server端状态,a.service.com可以生成一个traceid,并且为这个RPC生成一个spanid与span对象,这样这条来自系统外部的RPC就有了span记录了。
当a.service.com收到请求时,可以给这个server-side span打上sr,再处理完请求后可以打上ss,上报给zipkin。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
// 该rpc上游是浏览器,没有trace信息,所以生成server-side span记录本服务的处理时间 $srTimestamp = timestamp(); $span1 = [ "traceId" => idAlloc(), "name" => "/method_of_a", "id" => idAlloc(), "kind" => "SERVER", "timestamp" => timestamp(), "duration" => 0, "debug" => true, "shared" => false, "localEndpoint" => [ "serviceName" => "a.service.com", "ipv4" => "192.168.1.100", "port" => 80, ], "annotations" => [ [ "timestamp" => timestamp(), // 收到浏览器调用的时间 "value" => "sr" ], ], "tags" => [ "queryParams" => "a=1&b=2&c=3", ] ]; |
traceid和id(span id)被分配出来,前者标识整个调用链,后者标识浏览器到a.service.com之间的RPC。
name是当前的接口名或者说RPC方法名。
kind设置SERVER表示这是一个server-side span,上报span时需要在annotaions中包含sr和ss。
timestamp是创建span的时间,它的意义没有sr重要,但是可以作为一些参考(比如创建span对象和生成sr的annotation之间差了很多时间,是不是程序卡在什么地方?)。
localEndPoint标明这个span的来源,也就是a.service.com上报的,它是SERVER,是被调用方的地址。
tags也就是binary annotations,是一种k-v模型的业务自定义信息,它用来额外的描述这条span的信息,这里我将这次调用的GET参数放在了queryParams里,方便追查问题时候可以看到请求参数。
注意,现在server-side span1只是刚刚建立(只有sr),等所有逻辑处理完成后才能标记ss,然后上报zipkin。
span2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
// 模拟调用b.service.com function rpcToB($traceId, $parentSpanId) { // 生成rpc的spanId $spanId = idAlloc(); // 假设a.service.com发起了一个rpc调用b.service.com // 那么它将生成client-side span $csTimestamp = timestamp(); $span2 = [ "traceId" => $traceId, 'id' => $spanId, 'parentId' => $parentSpanId, "name" => "/method_of_b", "kind" => "CLIENT", "timestamp" => timestamp(), "duration" => 0, "debug" => true, "shared" => false, "localEndpoint" => [ "serviceName" => "a.service.com", "ipv4" => "192.168.1.100", "port" => 80, ], "annotations" => [ [ "timestamp" => $csTimestamp, // 发起b.service.com调用的时间 "value" => "cs" ], ], "tags" => [ "queryParams" => "e=1&f=2&g=3", ] ]; // 在rpc请求中将traceId,parentSpanId,spanId都带给了b.service.com // http.call("b.service.com/method_of_b?e=1&f=2&g=3", [$traceId, $parentSpanId, $spanId]) // 假设b.service.com收到请求后这样处理 { $b_srTimestamp = timestamp(); $span3 = [ "traceId" => $traceId, 'id' => $spanId, 'parentId' => $parentSpanId, "name" => "/method_of_b", "kind" => "SERVER", "timestamp" => $b_srTimestamp, "duration" => 0, "debug" => true, "shared" => true, "localEndpoint" => [ "serviceName" => "b.service.com", "ipv4" => "192.168.1.200", "port" => 80, ], "annotations" => [ [ "timestamp" => $b_srTimestamp, // 收到a.service.com请求的时间 "value" => "sr" ], ], ]; // 经过200毫秒处理 usleep(200 * 1000); $b_ssTimestamp = timestamp(); $span3['annotations'][] = [ "timestamp" => $b_ssTimestamp, // 应答a.service.com的时间 "value" => "ss" ]; $span3['duration'] = $b_ssTimestamp - $b_srTimestamp; postSpans([$span3]); } // a.service.com收到应答, 记录cr时间点, duration $crTimestamp = timestamp(); $span2['annotations'][] = [ "timestamp" => $crTimestamp, // 收到b.service.com应答的时间 'value' => "cr" ]; $span2['duration'] = $crTimestamp - $csTimestamp; global $spans; $spans[] = $span2; } rpcToB($span1['traceId'], $span1['id']); |
接下来要调用b.service.com,这是一个新的RPC,所以需要一个新的span,所以分配了新的spanid代表这次RPC,它的父亲RPC是span1,也就是浏览器->a.service.com这个调用。
在a.service.com中需要为这个span生成client-side信息(保存在变量$span2中),主要是指cs和cr。而在b.service.com收到请求后会为这个span生成server-side信息(保存在变量$span3中),$span2和$span3分别上报到zipkin后会被聚合到一起完整的描述这次的span。(注:这里$span2和$span3只是变量名,它们属于同一个span)
对于a.service.com来说,timestamp=cs,duration=cr-cs。
对于b.service.com来说,timestamp=sr,duration=ss-sr。
而cr与ss之间,cs与sr之间的差值,能描述出网络上的传输时间。
b.service.com收到请求后并没有发起对其他系统的调用,所以最后只postSpans上传了这一个server-side span信息。
a.service.com收到应答后还会继续向下执行其他调用,所以client-side span信息只是保存到数组里,等待最后批量发给zipkin。
特别注意,因为client-side和server-side都是在为同一个span贡献信息,所以两端上报的traceId,spanId,parentSpanId都是一样的,描述的都是这个span(RPC)的信息,尤其是parentSpanId,它代表这个RPC的上一级RPC,所以client-side和server-side都是一样的值,对dapper理论理解不深很容易产生误解。
实际上在zipkin最新V2版本的API(也就是我用的API)中,不再要求在annotations中上传cs,cr,sr,ss。而是通过kind标记是server-side span还是client-side span,两端记录自己的timestap来取代cs和sr,记录duration来取代cr和ss,可以实现完全一样的效果,好处是kind,timestamp,duration比annotation打点的方法更容易检索和筛选。
当kind=SERVER并且RPC携带了spanid而来,那么shared应该为true,表明被调用方和调用方共同贡献代表这个RPC的span信息,如果最终zipkin汇聚时发现shared=true的server-side span没有对应的client-side span,说明有上报丢失。
当kind=SERVER的情况下,RPC没有携带spanid而来,那么shared应该为false,表明RPC上游没有生成server-side span,这样zipkin不会认为上报存在丢失。
span4
接下来,a.service.com又调用了mysql执行SQL,但是mysql并不会处理span,所以会缺失server-side的span信息sr和ss。
但是a.service.com是可以生成cs和cr信息的,如果还是像之前一样只上报自己的locaEndpoint的话,在zipkin中其实是不知道本次调用了什么服务(因为server-side没有生成sr和ss,所以没有server-side的serviceName服务和address地址信息)。
好在zipkin其实是考虑到了这种情况,可以通过在client-side填写remoteEndPoint记录被调用方的服务名和地址,这样就不会因为server-side不记录localEndPoint而不知道被调用方的服务名称了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
// 模拟访问数据库 function queryDB($traceId, $parentSpanId) { // 生成数据库访问用的spanId $spanId = idAlloc(); // 假设a.service.com查询数据库, 因为数据库无法埋点,所以只能生成client-side span $csTimestamp = timestamp(); $span4 = [ "traceId" => $traceId, 'id' => $spanId, 'parentId' => $parentSpanId, "name" => "mysql.user", "kind" => "CLIENT", "timestamp" => timestamp(), "duration" => 0, "debug" => true, "shared" => false, "localEndpoint" => [ "serviceName" => "a.service.com", "ipv4" => "192.168.1.100", "port" => 80, ], "remoteEndpoint" => [ "serviceName" => "mysql.service.com", ], "annotations" => [ [ "timestamp" => $csTimestamp, // 发起数据库查询的时间 "value" => "cs" ], ], "tags" => [ "sql" => "select * from user;", ] ]; usleep(100 * 1000); // 模拟花费了100毫秒查询数据库 // 得到数据库查询结果 $crTimestamp = timestamp(); $span4['annotations'][] = [ "timestamp" => $crTimestamp, // 收到数据库结果的时间 'value' => "cr" ]; $span4['duration'] = $crTimestamp - $csTimestamp; global $spans; $spans[] = $span4; } queryDB($span1['traceId'], $span1['id']); |
最后
当mysql查询完成后,可以将a.service.com中生成的所有span(3个)上报给zipkin。
在zipkin中可以查看这个调用链的底层数据(JSON格式),其内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 |
[ { "traceId": "00055db10082961f", "id": "00055db100829627", "name": "/method_of_a", "timestamp": 1510389682705960, "duration": 369915, "annotations": [ { "timestamp": 1510389682705960, "value": "sr", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } }, { "timestamp": 1510389683075875, "value": "ss", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } } ], "binaryAnnotations": [ { "key": "queryParams", "value": "a=1&b=2&c=3", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } } ], "debug": true }, { "traceId": "00055db10082961f", "id": "00055db10082962d", "name": "/method_of_b", "parentId": "00055db100829627", "timestamp": 1510389682705966, "duration": 214131, "annotations": [ { "timestamp": 1510389682705966, "value": "cs", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } }, { "timestamp": 1510389682710925, "value": "sr", "endpoint": { "serviceName": "b.service.com", "ipv4": "192.168.1.200", "port": 80 } }, { "timestamp": 1510389682915137, "value": "ss", "endpoint": { "serviceName": "b.service.com", "ipv4": "192.168.1.200", "port": 80 } }, { "timestamp": 1510389682920097, "value": "cr", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } } ], "binaryAnnotations": [ { "key": "queryParams", "value": "e=1&f=2&g=3", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } } ], "debug": true }, { "traceId": "00055db10082961f", "id": "00055db10085dab8", "name": "mysql.user", "parentId": "00055db100829627", "timestamp": 1510389682920125, "duration": 105068, "annotations": [ { "timestamp": 1510389682920125, "value": "cs", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } }, { "timestamp": 1510389683025193, "value": "cr", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } } ], "binaryAnnotations": [ { "key": "sa", "value": true, "endpoint": { "serviceName": "mysql.service.com" } }, { "key": "sql", "value": "select * from user;", "endpoint": { "serviceName": "a.service.com", "ipv4": "192.168.1.100", "port": 80 } } ], "debug": true } ] |
一共有3个span记录,分别是:
- id=00055db100829627:a.service.com被调用了method_of_a方法,因为调用方是浏览器,所以只有ss和sr。
- id=00055db10082962d:b.service.com被调用了method_of_b方法,调用方是a.service.com,它贡献了cs和cr;被调用方贡献了sr和ss,每个annotation里的endpoint都是由我们上报时的localEndpoint标识的。
- id=00055db10085dab8:a.service.com调用了mysql.user接口(类似于RPC方法名,这里是指Mysql的user数据库),因为数据库没有调用链能力,所以这里只有cs和cr,同时因为上报时提供了remoteEndpoint信息,所以zipkin在binaryAnnotation里保存了一个key=sa,其endpoint是对端地址mysql.service.com而不是a.service.com地址,从而在WEB UI中展示被调用方的名字。
结束
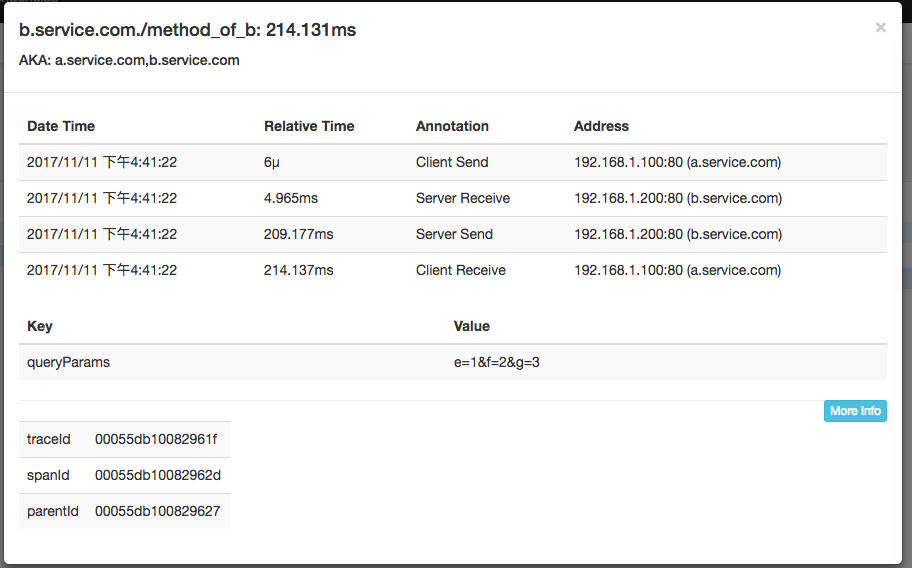
最后,点击第二行这个Span,可以看到a.service.com调用b.service.com的所有annotation描述信息:
补充
后续我让zipkin对接了ES,在ES中一个调用链的数据保存格式如下,可见其数据结构就是我们HTTP提交的原始模样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 |
[ { "_index" : "zipkin:span-2017-11-12", "_type" : "span", "_id" : "AV-wXowio-47v8n2AYke", "_score" : 2.5389738, "_source" : { "traceId" : "00055dc8f14d83e5", "duration" : 220529, "localEndpoint" : { "serviceName" : "a.service.com", "ipv4" : "192.168.1.100", "port" : 80 }, "debug" : true, "timestamp_millis" : 1510492506784, "kind" : "CLIENT", "name" : "/method_of_b", "annotations" : [ { "timestamp" : 1510492506784914, "value" : "cs" }, { "timestamp" : 1510492507005443, "value" : "cr" } ], "id" : "00055dc8f14d8492", "parentId" : "00055dc8f14d848e", "timestamp" : 1510492506784916, "tags" : { "queryParams" : "e=1&f=2&g=3" } } }, { "_index" : "zipkin:span-2017-11-12", "_type" : "span", "_id" : "AV-wXowio-47v8n2AYkf", "_score" : 1.6739764, "_source" : { "traceId" : "00055dc8f14d83e5", "debug" : true, "timestamp_millis" : 1510492507005, "kind" : "CLIENT", "annotations" : [ { "timestamp" : 1510492507005467, "value" : "cs" }, { "timestamp" : 1510492507109695, "value" : "cr" } ], "parentId" : "00055dc8f14d848e", "tags" : { "sql" : "select * from user;" }, "duration" : 104228, "remoteEndpoint" : { "serviceName" : "mysql.service.com" }, "localEndpoint" : { "serviceName" : "a.service.com", "ipv4" : "192.168.1.100", "port" : 80 }, "name" : "mysql.user", "id" : "00055dc8f150e217", "timestamp" : 1510492507005467 } }, { "_index" : "zipkin:span-2017-11-12", "_type" : "span", "_id" : "AV-wXot9o-47v8n2AYkd", "_score" : 1.2809339, "_source" : { "traceId" : "00055dc8f14d83e5", "duration" : 205077, "shared" : true, "localEndpoint" : { "serviceName" : "b.service.com", "ipv4" : "192.168.1.200", "port" : 80 }, "debug" : true, "timestamp_millis" : 1510492506784, "kind" : "SERVER", "name" : "/method_of_b", "annotations" : [ { "timestamp" : 1510492506784916, "value" : "sr" }, { "timestamp" : 1510492506989993, "value" : "ss" } ], "id" : "00055dc8f14d8492", "parentId" : "00055dc8f14d848e", "timestamp" : 1510492506784916 } }, { "_index" : "zipkin:span-2017-11-12", "_type" : "span", "_id" : "AV-wXowio-47v8n2AYkg", "_score" : 1.2809339, "_source" : { "traceId" : "00055dc8f14d83e5", "duration" : 378788, "localEndpoint" : { "serviceName" : "a.service.com", "ipv4" : "192.168.1.100", "port" : 80 }, "debug" : true, "timestamp_millis" : 1510492506784, "kind" : "SERVER", "name" : "/method_of_a", "annotations" : [ { "timestamp" : 1510492506784911, "value" : "sr" }, { "timestamp" : 1510492507163522, "value" : "ss" } ], "id" : "00055dc8f14d848e", "timestamp" : 1510492506784911, "tags" : { "queryParams" : "a=1&b=2&c=3" } } } ] |
zipkin使用B3协议在RPC两端传递span上下文,具体参考:https://github.com/openzipkin/b3-propagation。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

唯一ID生成建议使用openssl_random_pseudo_bytes,在官方PHP SDK实现中均采用了这个函数。
请问一下您用的PHP RPC 框架是什么?针对已在生产环境的项目和框架是否还能够集成rpc框架?
木有RPC框架, 就是封装一下curl库,把trace埋点进去。
1
您好 我按照您的流程走了一遍过后 在web UI 上只有服务名那一项有数据
span名和下面的调用链部分都是空白
请问这是什么原因呢
HI,信息提供的比较少,在理解原理的情况下,可以自行伪造数据尝试。
如果原理没问题,也许是zipkin新版本的数据schema有调整,根据原理翻看官方数据结构即可。
哇真的有回复欸:0
昨天试过了,也问过开发者,现在大概推测一个原因是zipkin的data model有了改变(因为我将您提供的json传送给api,返回无法解析的错误),还有一个原因是我这里的php是32位的,导致转换timestamp时数值出现问题
666
1