微服务-API熔断原理
伴随微服务,出现了很多新鲜的名词,其实剥去外衣并没有那么高大上。
今天要谈到的,叫做”熔断”,一个典型的开源实现是Hystrix(JAVA实现)。
背景
一个分布式系统中,服务间互相调用错综复杂,假设某个基础服务宕机,那么就会导致若干上游调用方出现访问超时,进而引起上游重试,导致宕机的基础服务遭受到数倍的流量放大,更加无法恢复服务。
这种恶劣的情况并不会就此结束,上游因为调用基础服务超时而变慢,导致上游的上游超时…异常向上蔓延,最终导致整个分布式系统”雪崩”。
“熔断”就是为了避免”雪崩”而生的,它的思路是在调用方增加一种”避让”机制,当下游出现异常时能够停止(熔断)对下游的继续请求,当等待一段时间后缓慢放行部分的调用流量,并当这部分流量依旧正常的情况下,彻底解除”熔断”状态。
听起来,流程不算复杂吧?整个流程图如下,看不懂没关系,继续往下阅读吧。
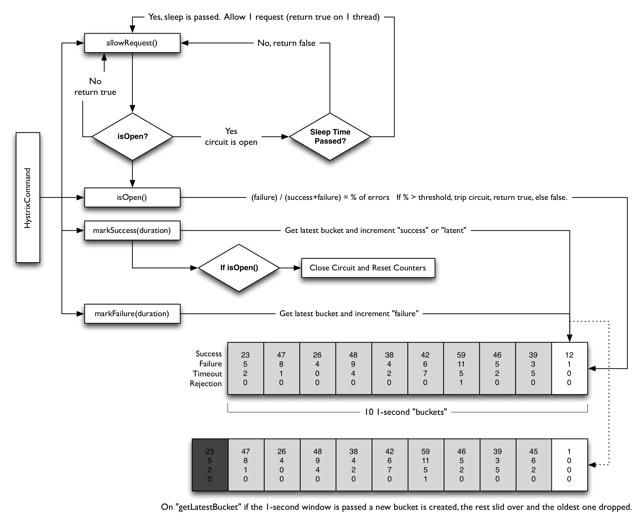
健康统计
判断下游正常的前提是统计最近一段时间内,下游的调用成功率,因此需要一个健康统计模块,记录最近N秒内的总请求数,成功请求数,失败请求数,是由业务调用后将结果打点到健康统计模块中。
下游健康的标志,是最近N秒的成功率大于某个阀值,那么代表下游健康。
因为时间不停的前进,要统计最近N秒内的成功率,显然仅仅维护3个数字是不足以表达的,因此这里一般会使用”时间窗口”来实现。
如最上面的图片所示,整个时间窗口由10个槽位(bucket)构成,每个槽位代表1秒钟,整个时间窗口表达了最近10秒的健康统计,最右侧的bucket记录了最近1秒的成功/失败请求数量,仅此而已。
随着时间每过去1秒,整个窗口会向右滑动1格,最左侧的1个槽位被淘汰,最右侧加入当前1秒的新槽位,这就是时间窗口的实现原理。
当然,我们在实现的时候不会写一个定时器每秒去更新时间窗口,而是当打点接口被调用的时候进行计算和窗口滑动。为了更清晰的帮助你理解,我写了一个简短的PHP实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
<?php // 时间窗口10个桶 define("BUCKET_NUM", 10); // 成功率大于该值为健康 define("HEALTHY_RATE", 0.8); // 健康统计 class HealthStats { private $service = ''; private $buckets = []; private $curTime = 0; public function __construct($service) { $this->service = $service; $this->buckets = array_fill(0, BUCKET_NUM, ['success' => 0, 'fail' => 0,]); } private function shiftBuckets() { $now = time(); $timeDiff = $now - $this->curTime; if (!$timeDiff) { return; } if ($timeDiff >= BUCKET_NUM) { $this->buckets = array_fill(0, BUCKET_NUM, ['success' => 0, 'fail' => 0]); } else { $this->buckets = array_merge( array_slice($this->buckets, $timeDiff, BUCKET_NUM - $timeDiff), array_fill(0, $timeDiff, ['success' => 0, 'fail' => 0]) ); } $this->curTime = $now; } public function success() { $this->shiftBuckets(); $this->buckets[count($this->buckets) - 1]['success']++; } public function fail() { $this->shiftBuckets(); $this->buckets[count($this->buckets) - 1]['fail']++; } public function isHealthy() { $this->shiftBuckets(); $success = 0; $fail = 0; foreach ($this->buckets as $bucket) { $success += $bucket['success']; $fail += + $bucket['fail']; } $total = $success + $fail; if (!$total) { return true; } return ($success * 1.0 / $total) >= HEALTHY_RATE; } } |
- 一个HealthStats对象维护某个下游服务的健康统计信息。
- 默认10个桶,每个桶1秒。
- RPC成功调用success,失败调用fail,检查服务健康调用isHealthy。
- 时间窗口滑动是”懒惰”的,所以在success,fail,isHealthy中都需要先进行窗口滑动的计算。
- 计算当前时间和窗口上次滑动的时间之间的时间差为timeDiff秒,那么就需要将窗口向右滑动timeDiff个槽位。
在每次RPC结束后,将结果打点到HealthStats中:
|
1 2 3 4 |
function rpc() { $resp = rand(0, 1); // 模拟调用成功/失败 $resp ? $healthStats->success() : $healthStats->fail(); } |
熔断控制
依靠健康统计,我们随时可以获知某个下游服务是否健康,当我们发现下游不健康的时候需要及时进行”熔断”操作。
所谓”熔断”,是指下游不健康的情况下,停止继续请求下游,避免因为请求超时导致自身处理时间增加,进而将坏的影响继续向上游传播。
那么到底要”熔断”多久?如何知道下游已经恢复了呢?这里涉及到”策略”问题,我们完全可以按照自己的设想来实现多种不同的策略,下面我举一种比较通用的策略作为演示。
- 初始化状态,熔断未启动,可以正常调用。
- 在每次RPC调用前,如果健康统计返回不健康,那么立即启动熔断。
- 在熔断开始的N秒内,不允许继续调用下游,此时没有新的请求继续发送出去。
- 在N秒过后,并且健康统计返回健康(时间窗口滚动,丢弃了那些历史数据),那么进入”恢复期”。
- “恢复期”开始的M秒内,随机允许部分调用发送给下游。
- “恢复期”内,如果健康检查返回不健康,那么重新启动”熔断”。
- “恢复期”开始的M秒之后,如果健康检查返回健康,那么关闭”熔断”,全部流量恢复调用。
- “恢复期”开始的M秒之内,如果健康检查返回健康,那么随着时间的推移,逐渐增加放量的比例,也就是慢慢恢复流量。
下面的代码演示了如何基于健康统计,实现一个熔断控制器:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
// 熔断后停止所有流量5秒 define("BREAK_PERIOD", 5); // 完全恢复需要再花费3秒 define("RECOVER_PERIOD", 3); // 熔断器 class CircuitBreaker { private $healthStats; private $status = 1; // 1:正常 2:熔断 3:恢复 private $breakTime = 0; // 熔断的时间点 public function __construct(HealthStats $healthStats) { $this->healthStats = $healthStats; } public function isBreak() { $now = time(); $isHealthy = $this->healthStats->isHealthy(); $breakLastTime = $now - $this->breakTime; $isBreak = false; switch ($this->status) { case 1: if (!$isHealthy) { $this->status = 2; $this->breakTime = time(); $isBreak = true; echo '触发熔断' . PHP_EOL ; } break; case 2: if ($breakLastTime < BREAK_PERIOD || !$isHealthy) { $isBreak = true; } else { $this->status = 3; echo '进入恢复' . PHP_EOL; } break; case 3: if (!$isHealthy) { $this->status = 2; $this->breakTime = time(); $isBreak = true; echo '恢复期间再次熔断' . PHP_EOL; } else { if ($breakLastTime >= BREAK_PERIOD + RECOVER_PERIOD) { $this->status = 1; echo '恢复正常' . PHP_EOL; } else { $passRate = $breakLastTime * 1.0 / (BREAK_PERIOD + RECOVER_PERIOD); if (mt_rand() / mt_getrandmax() > $passRate) { $isBreak = true; } } } break; } return $isBreak; } } |
在恢复期间每次计算熔断后健康状态持续的时间与最大恢复时间之间的比率(随着时间推移,逐渐增加为100%),随机数小于比率即可以发起调用,从而实现逐步放大流量。当然,如果恢复期间再次出现了不健康的状态,那么立即重置为熔断状态。
整个测试代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
// 健康检查 $healthStats = new HealthStats("a.service.com"); // 熔断器 $circuitBreaker = new CircuitBreaker($healthStats); function rpc() { global $healthStats, $circuitBreaker; if (!$circuitBreaker->isBreak()) { $resp = rand(0, 1); // 模拟调用成功/失败 $resp ? $healthStats->success() : $healthStats->fail(); } } for ($i = 0; $i < 100; ++$i) { rpc(); sleep(1); } |
将HealthStats传递给熔断器,每次RPC前先判断熔断器状态:如果熔断器正常,那么发起RPC调用,将结果成功/失败反馈到健康检查。
当熔断器处于恢复中时会逐步随机放量到下游,从而采集到最新的healthStats数据,进而促进熔断器从恢复中变为正常状态。
改进
健康检查的实现存在一个问题,就是如果只有很少的请求打点到HealthStats中,那么此时获取isHealthy其实不太准确,比如:目前只有1个成功和1个失败,成功率就是50%,显然基于这样的样本计算成功率是不准确的。
所以,在健康检查部分,我们设计一个阀值,只有总请求量超过阀值才真正计算成功率,否则总是返回健康,例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
public function isHealthy() { $this->shiftBuckets(); $success = 0; $fail = 0; foreach ($this->buckets as $bucket) { $success += $bucket['success']; $fail += + $bucket['fail']; } $total = $success + $fail; if ($total < 10) { // 少于10个请求的样本太少,不计算成功率 return true; } return ($success * 1.0 / $total) >= HEALTHY_RATE; } |
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

是否考虑新的机会哈,我们在组建基于 K8S 的 PaaS 平台,服务治理这一块需要很多大牛加入
1
1