RabbitMQ3.7-高可用集群搭建
很早接触过RabbitMQ,对其了解仅限于功能和特性,对其搭建和高可用原理未曾了解。
但是RabbitMQ与Kafka相比,是一个更强调数据可靠性而不是吞吐的消息队列,存在很多需求场景。
下面是一个最小化的高可用集群搭建示例,以及对原理方面的初步理解,足够作为入门阶段的使用需求。
部署集群
部署2个实例
RabbitMQ是使用一门非常小众的函数式语言erlang开发的,虽然我以前学过该语言,但我现在没有一点兴趣去回忆其原理了。
所以打开链接http://www.rabbitmq.com/#getstarted,下载合适的standalone版本,其包含了完整的erlang环境和RabbitMQ二进制。
解压后,拷贝2份分别到rabbit1和rabbit2目录:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
liangdongs-MacBook-Pro:rabbitmq liangdong$ ll total 47144 -rw-r--r--@ 1 liangdong staff 23098504 3 8 07:42 rabbitmq-server-mac-standalone-3.7.4.tar.xz drwxr-xr-x 15 liangdong staff 480 4 27 14:28 rabbitmq1 drwxr-xr-x 15 liangdong staff 480 4 27 14:59 rabbitmq2 liangdongs-MacBook-Pro:rabbitmq liangdong$ ll rabbitmq1/ total 0 drwxr-xr-x 4 liangdong staff 128 4 27 14:09 bin drwxr-xr-x 135 liangdong staff 4320 4 27 14:09 ebin drwxr-xr-x 3 liangdong staff 96 4 27 14:09 erts-9.2.1 drwxr-xr-x 5 liangdong staff 160 4 27 14:09 escript drwxr-xr-x 3 liangdong staff 96 4 27 14:09 etc drwxr-xr-x 10 liangdong staff 320 4 27 14:09 include drwxr-xr-x 23 liangdong staff 736 4 27 14:09 lib drwxr-xr-x 48 liangdong staff 1536 4 27 14:09 plugins drwxr-xr-x 3 liangdong staff 96 4 27 14:09 priv drwxr-xr-x 4 liangdong staff 128 4 27 14:09 releases drwxr-xr-x 9 liangdong staff 288 4 27 14:09 sbin drwxr-xr-x 3 liangdong staff 96 4 27 14:09 share drwxr-xr-x 4 liangdong staff 128 4 27 14:55 var |
安装插件
插件可以在RabbitMQ未启动的时候安装,我们主要需要安装一个WEB管理界面,在2个目录下分别执行一次下述安装命令:
|
1 |
sbin/rabbitmq-plugins enable rabbitmq_management |
配置实例(官方参考:https://www.rabbitmq.com/configure.html)
RabbitMQ启动时会在当前目录下工作,并加载当前目录下的配置,所以这两个实例通过目录已经自然的隔离开来了。
因为在同一台机器上部署2个实例,所以在配置方面主要是让两个进程使用不同的网络端口。
RabbitMQ默认读取当前目录下etc/rabbitmq/下的配置文件:
- rabbitmq.conf:程序配置
- rabbitmq-env.conf:环境变量
在3.7.0之前的版本中,RabbitMQ会读取rabbitmq.config文件(注意不是rabbitmq.conf),其配置格式是erlang的语法,非常难读。
所以在3.7.0之后,rabbitmq改为读取rabbitmq.conf,其风格就是简单的key=value风格,降低了使用门槛。
rabbitmq-env.conf要在rabbitmq.conf之前被加载,它其实就是通过linux环境变量来影响程序的行为,比如可以通过rabbitmq-env.conf指定接下来要加载的rabbitmq.conf文件的位置。
rabbitmq-env.conf
对于rabbit1来说,令其服务端口为7000(客户端访问的端口),实例的名字为rabbit1(因为2个实例在同一个HOST上部署,所以需要节点名不同,才能在集群里唯一标识):
|
1 2 3 |
liangdongs-MacBook-Pro:rabbitmq1 liangdong$ cat etc/rabbitmq/rabbitmq-env.conf NODE_PORT=7000 NODENAME=rabbit1 |
同样的修改rabbit2配置:
|
1 2 3 |
liangdongs-MacBook-Pro:rabbitmq2 liangdong$ cat etc/rabbitmq/rabbitmq-env.conf NODE_PORT=7001 NODENAME=rabbit2 |
这样2个RabbitMQ实例分别在7000和70001端口上对外服务。
rabbitmq.conf
该配置我们只需要把插件rabbitmq_managment的端口配置一下即可,我们可以通过浏览器查看与管理2个rabbitmq:
|
1 2 |
liangdongs-MacBook-Pro:rabbitmq1 liangdong$ cat etc/rabbitmq/rabbitmq.conf management.listener.port = 9000 |
|
1 2 |
liangdongs-MacBook-Pro:rabbitmq2 liangdong$ cat etc/rabbitmq/rabbitmq.conf management.listener.port = 9001 |
启动2个实例
现在2个实例之间并没有关联关系,我们简单的将它们分别启动起来:
|
1 |
liangdongs-MacBook-Pro:rabbitmq1 liangdong$ sbin/rabbitmq-server -detached |
|
1 |
liangdongs-MacBook-Pro:rabbitmq2 liangdong$ sbin/rabbitmq-server -detached |
现在你可以打开浏览器访问:localhost:7000和localhost:7001,分别管理rabbit1和rabbit2。
组成集群
类似于redis-cluster,我们需要手动的让2个单点实例组成一个集群(cluster),这样2个节点就会共享集群信息,比如rabbitmq1有一个queue1,那么rabbitmq2也会知道这个事情(注意,仅仅是知道而已)。
进入rabbitmq2目录,首先暂停rabbitmq2:
|
1 |
sbin/rabbitmqctl stop_app |
然后指定rabbitmq1的节点名字,这样rabbitmq2就会记录下这个关系:
|
1 |
sbin/rabbitmqctl join_cluster rabbit1@liangdongs-MacBook-Pro |
@后面的是主机名,前面是我们在rabbitmq-env中配置的node name。
现在重新唤醒rabbitmq2,它会尝试连接rabbitmq1并与之组成一个集群:
|
1 |
sbin/rabbitmqctl start_app |
现在再去观察rabbitmq1和rabbitmq2的web UI,会发现它们已经进去到了一个集群,并且共享了自己的存储信息:

镜像队列
集群模式仅仅是2个实例共享了信息,但是并没有实现queue队列存储的高可用,也就是没有产生副本。
接下来的操作我们均通过web UI实现。
创建queue
首先在rabbitmq1创建一个queue,选择持久化机制:
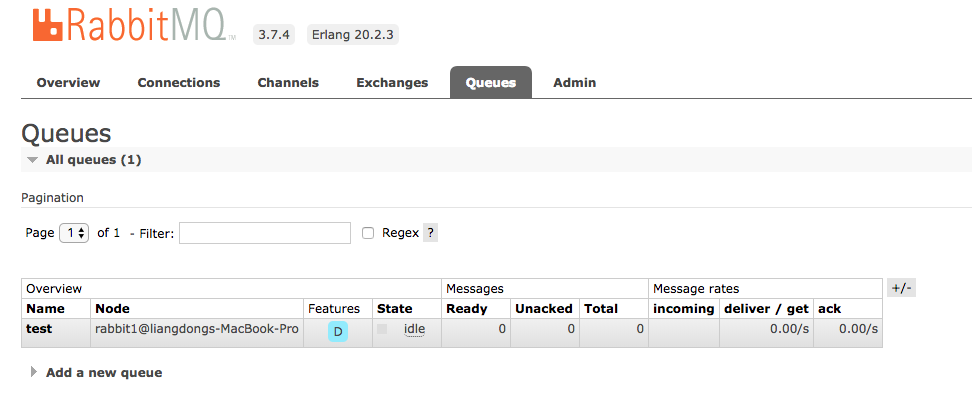
队列名test,Features中的D表示持久化,目前它位于rabbit1上,存在单点故障隐患。
创建policy
为了让test队列实现高可用,需要启动镜像,也就是让test的数据复制到集群中的其他实例,这样单点宕机后其他实例可以继续对外服务。
通过配置cluster的policy策略即可实现:

Name是策略名(随便起),Pattern是指队列的名字符合该正则表达式,则应用该策略。
ha-mode是镜像模式,设置ha-mode=all,则所有符合该pattern的queue将被复制到集群所有实例上去。
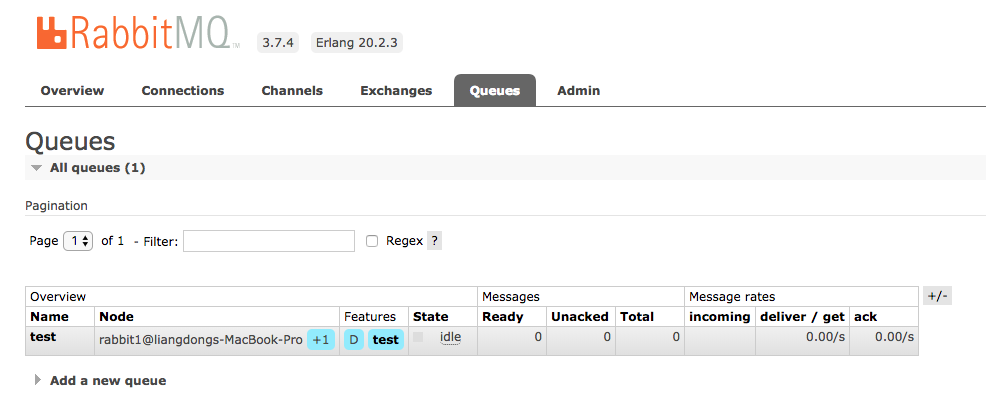
被镜像的queue
再次查看queue信息(从任何一个rabbitmq实例都可以),你会发现Features中多了一个test标签,它就是我们刚才添加的policy。
这说明,镜像策略已经生效到该queue,它在rabbitmq1和rabbitmq2上实现了副本存储,任何单点故障均不会导致数据丢失。
在任意实例页面上,发布几条消息到该队列:
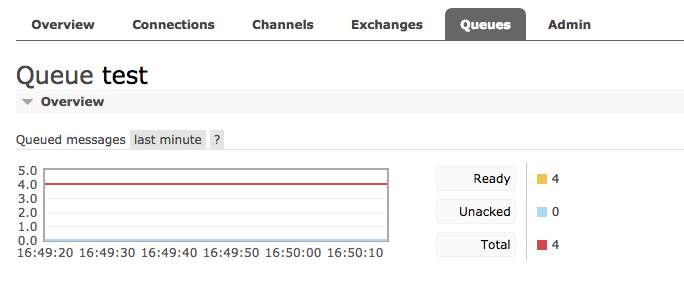
可以看到发布了4次消息。
现在通过kill -9杀死rabbitmq1进程:
|
1 |
liangdongs-MacBook-Pro:rabbitmq1 liangdong$ kill -9 85112 |
访问rabbitmq2的web UI,发现rabbitmq1掉线:

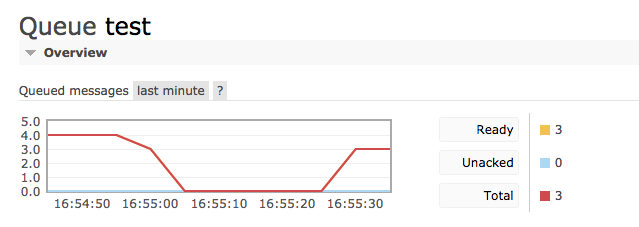
消费掉之前的4条hello数据,然后再添加3条bye:
现在启动rabbitmq1,看看会发生什么?
|
1 |
liangdongs-MacBook-Pro:rabbitmq1 liangdong$ sbin/rabbitmq-server -detached |
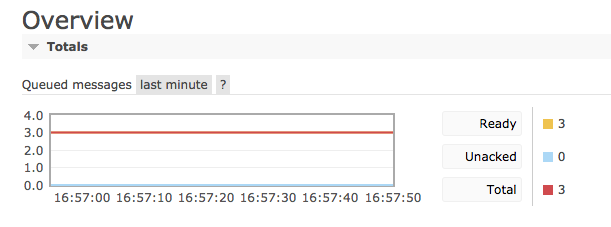
打开rabbitmq1的web UI,发现集群恢复正常,rabbitmq1同步了rabbitmq2的状态,同样剩余3条bye消息在队列中:

总结
最新版的rabbitmq有点开箱即用的感觉,关于集群运维感觉也没有网上博客说的那样需要很多注意点,目前感觉还不错,大家用用看吧。
另外,rabbitmq倾向于消息的可靠性,吞吐就比较差了。
对于一个被镜像到集群中多个实例的queue来说,其吞吐并不会有明显提升,因为消费请求都是由queue的主节点(master)来处理的,镜像仅仅是为了高可用而已。
如果追求很高的吞吐,我相信Kafka是一个更好的选择,但同时也无法享受AMQP提供的类似ACK的可靠性保障。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
1