mysql分库分表方案
最近遇到了mysql扩展性方面的需求,记录如下。
问题
项目发展至今只有一个库,单表记录的规模是几千万级别,主要带来两类问题。
问题1:增加一个字段会阻塞好几分钟,影响线上业务。
问题2:专门用于存储日志的表,增长速度快而且单行记录比较大,单个mysql实例的磁盘接近于瓶颈。
解决方案
问题1
把记录打散到多个表里,按照某个业务维度取模即可,称为”拆表”。
1000万的表拆成10份,那么每个表就100万记录,增加字段耗时就很少了。
问题2
对于存储空间瓶颈,一般需要增加mysql实例,也称为”拆库”。
可以把拆开的表分摊到多个库里,实现容量的扩展性。
定位库是不需要取模之类的固定计算规则的,表在哪个库是可以代码或者mysql代理中间件配置的,客户端仍旧只需要取模定位到表即可。
整体架构
在你决定由单库单表 向 多库多表做迁移的时候,你首先应该根据公司倒闭之前的最大数据规模确认需要多少个分表,并一次性建立出来。
也许你只是未雨绸缪,但是表规模一定要一次性确立。
网上传的比较多的就是说表一定要分成2^N个,扩容时候直接翻倍到2^(N+1)个,迁移起来会方便很多。其实呢,这种方案大多是事后诸葛,因为他们最早没分够或者估算少了,导致后面扩容复杂,还需要清洗掉无用的冗余数据,一点也不方便。
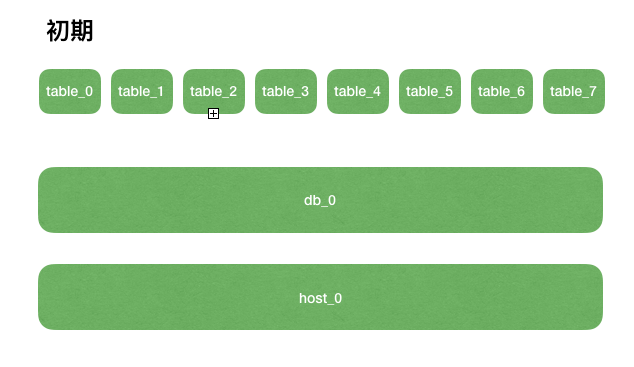 上图举例,将原本的单表数据按某业务维度(比如uid)按8取模归属到对应的table_x中。
上图举例,将原本的单表数据按某业务维度(比如uid)按8取模归属到对应的table_x中。
然后table_0~7全部放在db0里,db0存储在host_0实例。
初期数据库性能还没有明显的读写压力,但是单表记录还是很大的,所以出于长远考虑一次性拆分成足够多的table是必须要做的工作。
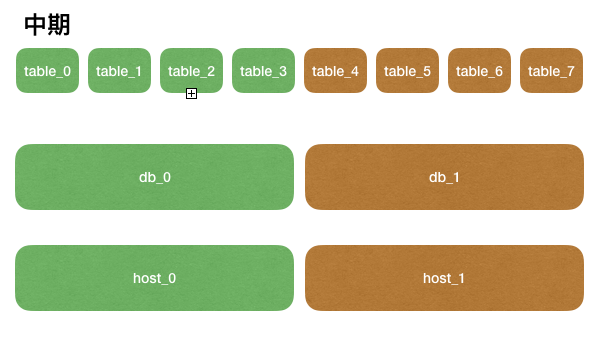
随着发展,db_0库的读写压力到达瓶颈,于是希望可以把部分表挪到新的实例上,利用更多的物理机分担压力。
这一步我们只需要找一台新的mysql服务器,创建一个新的db_1数据库,并做主从同步将db_0上的table4~7迁移过来。
一旦数据同步完成,客户端可以修改配置,让table_4~table_7的请求访问到db1库,物理服务器是host_1。
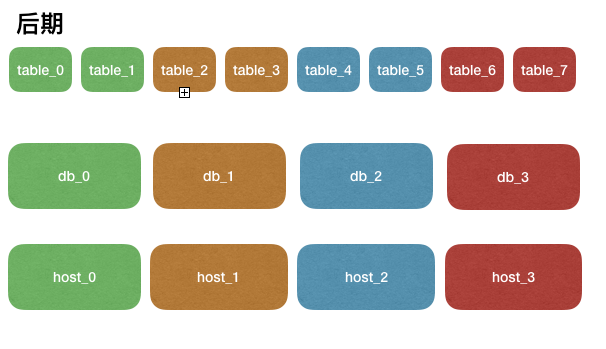
集群压力继续增大,我们可以继续增加更多的实例,将表均摊到各个实例即可,这里并不要求哪张表必须在哪个库,是完全可以自定义的,映射关系存储在客户端或者中间件。
其他
分库分表的透明化
分库分表给客户端带来了开发的变化,比如客户端需要与多个数据库建立连接,需要在查询的时候自己计算表的下标,查看表在哪个数据库与实例。
这个问题一般可以借助mysql代理中间件来屏蔽变化,比如Mycat。
Mycat会虚拟出一个逻辑大表,并根据业务维度(例如uid)自动的在MYSQL集群间路由请求。
分库分表的限制
分库分表后,很多查询SQL将不能继续工作,因为数据已经按照业务维度被打散到多张表,一般都会影响到已有业务。
中间件并不能有效解决这个问题,一般需要一个分布式存储来解决跨分表的查询操作,比如可以将所有分表的数据同步存储到Elasticsearch中,满足业务查询需求。
日志类存储
日志一般使用频率很低,但是量级和存储空间都很大,可以考虑使用mongodb等分布式存储来替代mysql集群方案,达到轻松扩容的目的。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

请问一般会对表分区么?拆成单个表,如果数据量还是比较大,那么对表进行分区,提高查询速度,这个是否可行?
我之前看过一篇文章,文章里不推荐采用分区的方案
没必要使用mysql自己的partition特性。
请教一下,如果都是在一个机器一个库里,使用mysql数据库,分表对比单表会有性能提升么?分表数据量比较小,主键B+树的层级较小,查询时的磁盘I/O次数会少一些,性能是不是就会提升?
1
1
1