服务拆分的4个阶段
这两天ucloud的一位技术负责人来公司做技术交流,提到了在腾讯比较推崇的”按set做服务拆分”理念,下面简单记录一下。
服务拆分
最初我们做SOA服务化拆分,也叫做垂直拆分,不同的业务和功能被拆分到不同的服务中。
当业务规模继续上升,个别服务出现了存储的瓶颈,于是需要进行存储的横向拆分设计,这就是本博客要讲的横向拆分的4个阶段。
服务横向拆分的4个阶段
下面的图片代表了服务拆分的4个阶段,存在一定的演进关系。
计算就是指我们的业务代码,存储指数据库或者缓存。
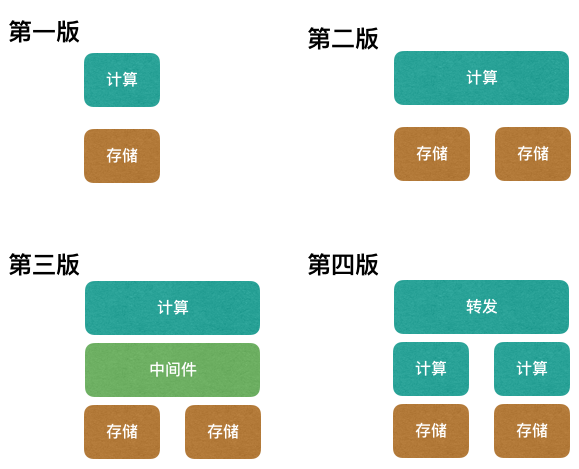
第一版
存储没有达到存储容量以及性能的瓶颈,仍旧是单实例。
我们通过增加计算节点可以得到QPS的线性提升。
第二版
这个阶段,可能是存储容量到达了瓶颈,比如单库的磁盘已经接近极限。
也可能单库的TPS超过了极限,增加更多的计算节点并无法解决存储的性能瓶颈。(此时可以考虑增加一层缓存,但缓存最终也会达到性能极限)
当存储单体达到性能瓶颈后,我们必须做存储层的横向扩容。
对于数据库来说,可以按照某个业务维度拆库拆表,扩容数据库实例来承载更多的TPS。
对于缓存来说,可以像数据库一样扩容更多的实例,并通过业务维度实现数据打散。
无论如何,这个阶段计算层需要根据业务维度路由,找到数据所在的存储节点。
分叉路口
到了这个时间点,大多数公司已经基本解决了服务扩展的问题,但是慢慢的也暴露了一些其他问题。
对于我们PHP技术栈的公司,计算层与多个存储分区建立连接获取数据,给数据库带来了连接数的压力,也带来了额外的请求延迟。
对于任何一门语言/框架,都需要一套基于客户端本地的数据库路由组件,JAVA的同学可能很熟悉jdbc-sharding这类工具。
再者,当某个存储分区故障时,因为计算层是共享的,往往导致整个计算服务被拖垮。
因此我们需要进一步做架构的升级,此时出现了2类升级路线。
第三版
该路线希望通过一个大中间件来解决所有的存储层扩展性问题。
比如数据库增加一层db proxy作为代理,帮计算层透明的完成数据路由,同时也实现数据库连接的复用。
比如缓存层抛弃多实例部署方式,而是选择一款分布式缓存,比如redis cluter/codis。
有了中间件,计算层不再需要客户端本地的数据路由组件,业务开发不再需要关心存储层的分片细节,回归到最初的简单。
但是弊端也很明显,中间件的稳定性和功能是否强大就变得非常重要。
如果中间件不支持分片故障的隔离,那么仍旧不是一个可靠的架构。
如果中间件有很多BUG和功能缺失,那么公司必须投入人力来研发。
第四版
该路线是抛弃中间件的,通过给每个存储分片分配独立的计算层,实现故障隔离。
腾讯给这个架构方式起名叫做:set化,用业界专业术语叫做:bulkheads隔舱模式。
首先我们因为存储的瓶颈做了存储层横向分片,然后因为单个分片故障会影响整个计算层,所以最朴素的想法就是把计算层也拆分开。
这样每个小单元称为一个set,它们只负责一部分数据的存储与计算,是一个完整的服务单元,与其他set隔离。
使用set拆分后,需要实现请求路由层(注意不是存储路由),把请求路由到数据所在的set单元。
这个路由层可以用openresty实现,通过识别请求中的业务标识完成到set的请求转发,它自身是不包业务逻辑的。
思考set方案发现存在一定的成本问题,因为最初我们因为存储瓶颈做了存储拆分,然而set方案要求给每个存储分片配备计算资源,造成了的资源占用不对称的问题。
最后
虽然说set方案隔离性最好,但是实施成本和改造成本都比较高。
看似大多数公司还是选择了中间件方案,或者仅仅对核心业务做了set隔离,来尽量减小故障损失的影响面。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1