prometheus client用法与原理
前一阵看k8s的时候接触了prometheus,当时感觉它的查询语法promql还是挺难理解的,所以时隔一个月的时间决定再回头找找思路。
另外呢,我觉得prometheus非常实用,结合grafana展示炫酷的大盘报表,这是一个非常实在的技能。
下面拿python client为例,讲讲我对Prometheus的理解。
项目
python的代码放在这个项目里:https://github.com/owenliang/prometheus-py,下面是所有代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# -*- coding: utf-8 -*- from prometheus_client import Counter, Gauge, Histogram, Summary, start_http_server, Histogram import time import random # 定义4种metrics例子 c = Counter('cc', 'A counter') g = Gauge('gg', 'A gauge') h = Histogram('hh', 'A histogram', buckets=(-5, 0, 5)) s = Summary('ss', 'A summary', ['label1', 'label2']) # metrics名字, metrics说明, metrics支持的label # 在线程中启动http服务, 供metrics抓取 start_http_server(8000) # while True: # counter: 只增不减 c.inc() # gauge: 任意值 g.set(random.random()) # histogram: 任意值, 会给符合条件的bucket增加1次计数 h.observe(random.randint(-10, 10)) # summary:任意值, python client不支持summary的百分位统计, 其他语言的client也许支持, 但一般不建议用, 性能和场景都有局限 s.labels('a', 'b').observe(17) time.sleep(1) |
其中start_http_server在8000端口监听HTTP服务,供prometheus抓取metrics。
下面我们围绕代码来讲一下prometheus使用的关键概念。
客户端用法与原理
|
1 2 3 4 5 |
# 定义4种metrics例子 c = Counter('cc', 'A counter') g = Gauge('gg', 'A gauge') h = Histogram('hh', 'A histogram', buckets=(-5, 0, 5)) s = Summary('ss', 'A summary', ['label1', 'label2']) # metrics名字, metrics说明, metrics支持的label |
客户端可以使用4种metrics类型,我们一个一个说。
counter
一直累加的计数器,不可以减少。
定义它需要2个参数,第一个是metrics的名字,第二个是metrics的描述信息:
|
1 |
c = Counter('cc', 'A counter') |
它的唯一方法就是inc,只允许增加不允许减少:
|
1 2 3 4 5 |
def inc(self, amount=1): '''Increment counter by the given amount.''' if amount < 0: raise ValueError('Counters can only be incremented by non-negative amounts.') self._value.inc(amount) |
counter适合用来记录访问总次数之类的,通过promql可以计算counter的增长速率,即可以得到类似的QPS诸多指标。
调用的时候这样即可:
|
1 2 |
# counter: 只增不减 c.inc() |
抓取到的metrics这样:
|
1 2 3 4 5 |
# HELP cc_total A counter # TYPE cc_total counter cc_total 46.0 # TYPE cc_created gauge cc_created 1.546424546634121e+09 |
#HELP是cc的注释说明,我们刚才定义的时候指定的,#TYPE说明cc是一个counter。
其实cc这个counter被输出为cc_total,对应的累加值是46.0。
cc_created这个输出的TYPE是gauge类型,记录了cc这个metrics的创建时间,下面我们就说gauge类型是啥。
gauge
和counter略有不同。
gauge可增可减,可以任意设置,就代表了某个指标当前的值而已。
比如可以设置当前的CPU温度,内存使用量等等,它们都是上下浮动的,不是只增不减的。
定义和counter基本一样:
|
1 |
g = Gauge('gg', 'A gauge') |
第一个是metrics的名字,第二个是描述。
它支持3个方法:
|
1 2 3 4 5 6 7 8 9 10 11 |
def inc(self, amount=1): '''Increment gauge by the given amount.''' self._value.inc(amount) def dec(self, amount=1): '''Decrement gauge by the given amount.''' self._value.inc(-amount) def set(self, value): '''Set gauge to the given value.''' self._value.set(float(value)) |
因为是任意的值,所以可以inc/dec,也可以set。
最后就是调用方法,我这里每次设置一个随机值,其值可以是任意浮点数:
|
1 2 |
# gauge: 任意值 g.set(random.random()) |
输出也类似:
|
1 2 3 |
# HELP gg A gauge # TYPE gg gauge gg 0.935768437404028 |
名字就是gg,TYPE是gauge。
我认为gauge的大部分用法就是直接拿来画图就好了,不需要做promql处理。
histogram
这种主要用来统计百分位的,什么是百分位?英文叫做quantiles。
比如你有100条访问请求的耗时时间,把它们从小到大排序,第90个时间是200ms,那么我们可以说90%的请求都小于200ms,这也叫做”90分位是200ms”,能够反映出服务的基本质量。当然,也许第91个时间是2000ms,这就没法说了。
实际情况是,我们每天访问量至少几个亿,不可能把所有访问数据都存起来,然后排序找到90分位的时间是多少。因此,类似这种问题都采用了一些估算的算法来处理,不需要把所有数据都存下来,这里面数学原理比较高端,我们就直接看看prometheus的用法好了。
首先定义histogram:
|
1 |
h = Histogram('hh', 'A histogram', buckets=(-5, 0, 5)) |
第一个是metrics的名字,第二个是描述,第三个是分桶设置,重点说一下buckets。
这里(-5,0,5)实际划分成了几种桶:<=-5,<=0,<=5,<=无穷大。
如果我们喂给它一个-8:
|
1 |
h.observe(8) |
那么metrics会这样输出:
|
1 2 3 4 5 6 7 8 |
# HELP hh A histogram # TYPE hh histogram hh_bucket{le="-5.0"} 0.0 hh_bucket{le="0.0"} 0.0 hh_bucket{le="5.0"} 0.0 hh_bucket{le="+Inf"} 1.0 hh_count 1.0 hh_sum 8.0 |
hh_sum记录了observe的总和,count记录了observe的次数,bucket就是各种桶了,le表示<=某值。
可见,值8<=无穷大,所以只有最后一个桶计数了1次(注意,桶只是计数,bucket作用相当于统计样本在不同区间的出现次数)。
bucket的划分需要我们根据数据的分布拍脑袋指定,合理的划分可以让promql估算百分位的时候更准确,我们使用histogram的时候只需要知道先分好桶,再不断的打点即可,最终百分位的计算可以基于histogram的原始数据完成。
我们不停的随机产生-5到5之间的打点给histogram:
|
1 2 3 |
while True: # histogram: 任意值, 会给符合条件的bucket增加1次计数 h.observe(random.randint(-5, 5)) |
每次prometheus来scrape抓走当前的metrics长相如下:
|
1 2 3 4 5 6 7 8 9 10 |
# HELP hh A histogram # TYPE hh histogram hh_bucket{le="-5.0"} 12.0 hh_bucket{le="0.0"} 83.0 hh_bucket{le="5.0"} 153.0 hh_bucket{le="+Inf"} 153.0 hh_count 153.0 hh_sum -16.0 # TYPE hh_created gauge hh_created 1.546499508889123e+09 |
这些都叫做Instant-vector,瞬时向量。
到prometheus后台可以查出来最新的一组hh瞬时向量,只有标签不同(划分区间):

比无穷大小的有52次,说明一共就打点了52次。
比-5小的只有3次,比0小的29次,可以算出-5~0之间的是29-3=26次。
同样可以算出,0~5之间的是52-29=23次。
对这一组瞬时向量可以进行百分位的估算,比如我们要估算90分位的值是多少:

可见90分位的数值大概是3.9657534246575348,也就是90%的打点都比3.9小,感觉还是比较合理的哈,因为我们的随机数的上限就是5。
histogram这种metrics分桶计数的方式,在prometheus服务端做promql估算百分位,其估算准确度受限于分桶的合理性,如果桶分的不好,那估算的值就很不准了,这个大家慢慢摸索吧。
summary
因为histogram在客户端就是简单的分桶和分桶计数,在prometheus服务端基于这么有限的数据做百分位估算,所以的确不是很准确,summary就是解决百分位准确的问题而来的。
summary相当于把服务端的算法放在客户端实现,客户端打点的同时直接计算百分位。
这要求客户端提前定义好你想计算哪些百分位(就像histogram定义好每个桶的区间一样),这样客户端会直接算出精度很高的百分位值,直接给prometheus抓走使用即可。
python客户端没有完整实现summary算法,其实summary把算法搬到了客户端实现带来了很严重的性能问题,因为histogram仅仅是给每个桶做一个原子变量的计数就可以了,而summary要每次执行算法计算出最新的X分位value是多少,算法需要并发保护,所以对并发程序的性能影响就很大了,这可能也是python没实现它的原因之一吧。
另一个原因,可能是因为summary不灵活,因为百分位是提前在客户端里指定的,而histogram则可以通过promql随便指定,虽然计算的不如summary准确,但带来了灵活性。
所以summary就不展开说明了。
服务端用法与原理
接下来说说服务端,我觉得有几个理解意义重大。
关于instant-vector
这两种类型的vector什么时候用很容易乱,我说说我的理解。
最容易产生误解的地方就是:认为画graph需要用range-vector,这是第一次了解prometheus很大的误区。
我们以为画一条曲线需要很多很多的point才能串起来,所以理所当然认为画图应该是用range-vector来取N个point,所以很容易认为应该用cc[5m]这样的range-vector,这是完全错误的!
实际画曲线用的是instant-vector!
prometheus画图的时候,会往过去的时间重复的后退N秒,取每一次的instant-vector出来,最后用这些不同时间点的instant-vector来画线。
这是最新的一条cc_total instant-vector:

保持该promql不变直接切换到graph可以画出曲线,下方可以看到ajax请求,请求告知prometheus,每间隔14秒计算一次promsql得到instant-vector,整个时间窗口是start到end:
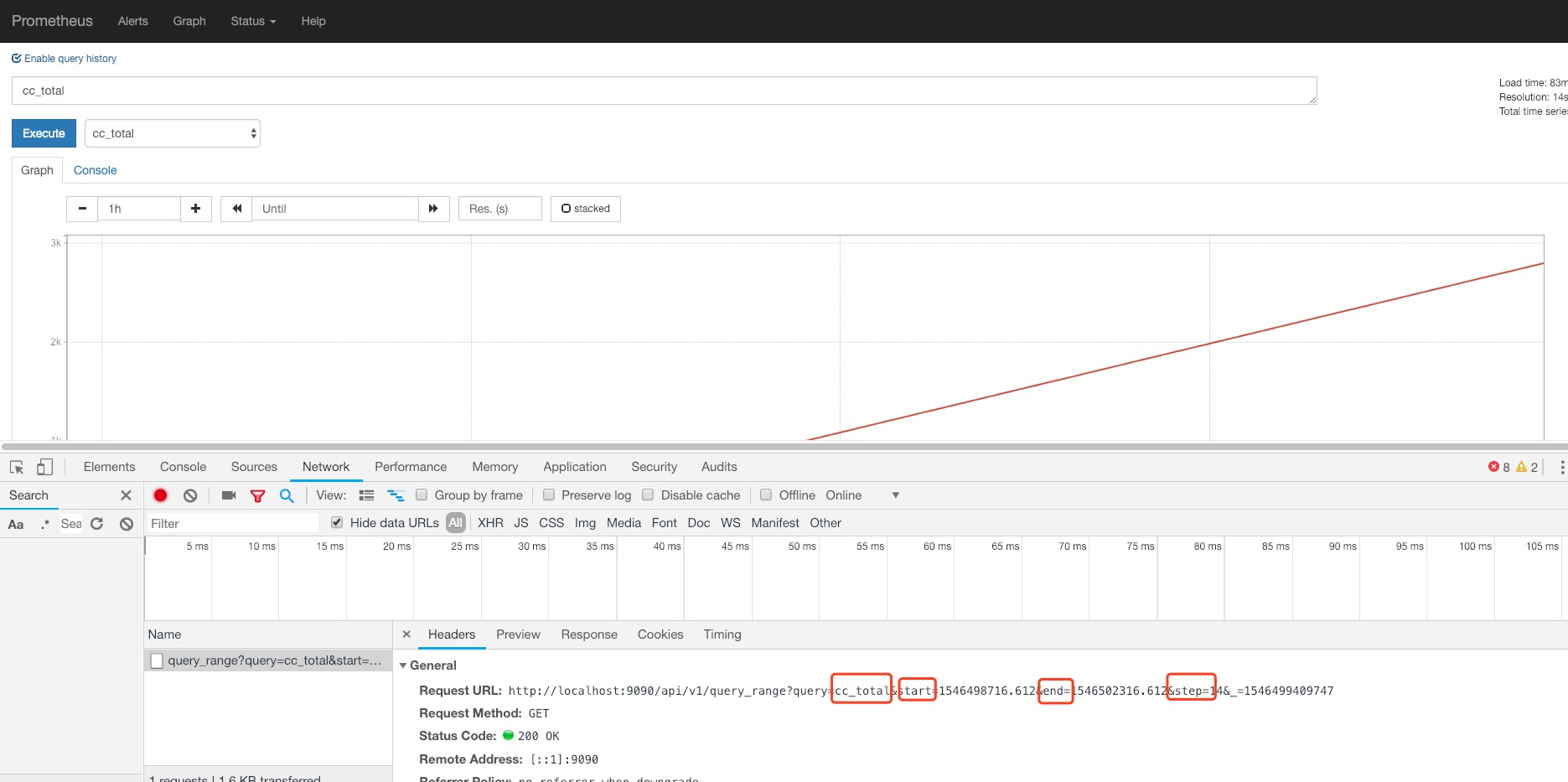
返回的数据长这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 |
{ "status": "success", "data": { "resultType": "matrix", "result": [{ "metric": { "__name__": "cc_total", "instance": "localhost:8000", "job": "prometheus-py" }, "values": [ [1546499402.612, "39"], [1546499416.612, "53"], [1546499430.612, "67"], [1546499444.612, "81"], [1546499458.612, "95"], [1546499472.612, "109"], [1546499486.612, "123"], [1546499500.612, "137"], [1546499514.612, "5"], [1546499528.612, "19"], [1546499542.612, "33"], [1546499556.612, "47"], [1546499570.612, "61"], [1546499584.612, "75"], [1546499598.612, "89"], [1546499612.612, "103"], [1546499626.612, "117"], [1546499640.612, "131"], [1546499654.612, "145"], [1546499668.612, "159"], [1546499682.612, "173"], [1546499696.612, "187"], [1546499710.612, "201"], [1546499724.612, "214"], [1546499738.612, "228"], [1546499752.612, "242"], [1546499766.612, "256"], [1546499780.612, "270"], [1546499794.612, "284"], [1546499808.612, "298"], [1546499822.612, "312"], [1546499836.612, "326"], [1546499850.612, "340"], [1546499864.612, "354"], [1546499878.612, "368"], [1546499892.612, "382"], [1546499906.612, "396"], [1546499920.612, "410"], [1546499934.612, "424"], [1546499948.612, "438"], [1546499962.612, "452"], [1546499976.612, "466"], [1546499990.612, "480"], [1546500004.612, "494"], [1546500018.612, "508"], [1546500032.612, "522"], [1546500046.612, "536"], [1546500060.612, "550"], [1546500074.612, "564"], [1546500088.612, "578"], [1546500102.612, "591"], [1546500116.612, "605"], [1546500130.612, "619"], [1546500144.612, "633"], [1546500158.612, "647"], [1546500172.612, "661"], [1546500186.612, "675"], [1546500200.612, "689"], [1546500214.612, "703"], [1546500228.612, "717"], [1546500242.612, "731"], [1546500256.612, "745"], [1546500270.612, "759"], [1546500284.612, "773"], [1546500298.612, "787"], [1546500312.612, "801"], [1546500326.612, "815"], [1546500340.612, "829"], [1546500354.612, "843"], [1546500368.612, "857"], [1546500382.612, "871"], [1546500396.612, "885"], [1546500410.612, "899"], [1546500424.612, "913"], [1546500438.612, "927"], [1546500452.612, "941"], [1546500466.612, "954"], [1546500480.612, "968"], [1546500494.612, "982"], [1546500508.612, "996"], [1546500522.612, "1010"], [1546500536.612, "1024"], [1546500550.612, "1038"], [1546500564.612, "1052"], [1546500578.612, "1066"], [1546500592.612, "1080"], [1546500606.612, "1094"], [1546500620.612, "1108"], [1546500634.612, "1122"], [1546500648.612, "1136"], [1546500662.612, "1150"], [1546500676.612, "1164"], [1546500690.612, "1178"], [1546500704.612, "1192"], [1546500718.612, "1206"], [1546500732.612, "1220"], [1546500746.612, "1234"], [1546500760.612, "1248"], [1546500774.612, "1262"], [1546500788.612, "1276"], [1546500802.612, "1290"], [1546500816.612, "1304"], [1546500830.612, "1317"], [1546500844.612, "1331"], [1546500858.612, "1345"], [1546500872.612, "1359"], [1546500886.612, "1373"], [1546500900.612, "1387"], [1546500914.612, "1401"], [1546500928.612, "1415"], [1546500942.612, "1429"], [1546500956.612, "1443"], [1546500970.612, "1457"], [1546500984.612, "1471"], [1546500998.612, "1485"], [1546501012.612, "1499"], [1546501026.612, "1513"], [1546501040.612, "1527"], [1546501054.612, "1541"], [1546501068.612, "1555"], [1546501082.612, "1569"], [1546501096.612, "1583"], [1546501110.612, "1597"], [1546501124.612, "1611"], [1546501138.612, "1624"], [1546501152.612, "1638"], [1546501166.612, "1652"], [1546501180.612, "1666"], [1546501194.612, "1680"], [1546501208.612, "1694"], [1546501222.612, "1708"], [1546501236.612, "1722"], [1546501250.612, "1736"], [1546501264.612, "1750"], [1546501278.612, "1764"], [1546501292.612, "1778"], [1546501306.612, "1792"], [1546501320.612, "1806"], [1546501334.612, "1820"], [1546501348.612, "1834"], [1546501362.612, "1848"], [1546501376.612, "1862"], [1546501390.612, "1876"], [1546501404.612, "1890"], [1546501418.612, "1904"], [1546501432.612, "1918"], [1546501446.612, "1932"], [1546501460.612, "1946"], [1546501474.612, "1959"], [1546501488.612, "1973"], [1546501502.612, "1987"], [1546501516.612, "2001"], [1546501530.612, "2015"], [1546501544.612, "2029"], [1546501558.612, "2043"], [1546501572.612, "2057"], [1546501586.612, "2071"], [1546501600.612, "2085"], [1546501614.612, "2099"], [1546501628.612, "2113"], [1546501642.612, "2127"], [1546501656.612, "2141"], [1546501670.612, "2155"], [1546501684.612, "2169"], [1546501698.612, "2183"], [1546501712.612, "2197"], [1546501726.612, "2211"], [1546501740.612, "2225"], [1546501754.612, "2239"], [1546501768.612, "2253"], [1546501782.612, "2267"], [1546501796.612, "2281"], [1546501810.612, "2295"], [1546501824.612, "2309"], [1546501838.612, "2323"], [1546501852.612, "2336"], [1546501866.612, "2350"], [1546501880.612, "2364"], [1546501894.612, "2378"], [1546501908.612, "2392"], [1546501922.612, "2406"], [1546501936.612, "2420"], [1546501950.612, "2434"], [1546501964.612, "2448"], [1546501978.612, "2462"], [1546501992.612, "2476"], [1546502006.612, "2490"], [1546502020.612, "2504"], [1546502034.612, "2518"], [1546502048.612, "2532"], [1546502062.612, "2546"], [1546502076.612, "2560"], [1546502090.612, "2574"], [1546502104.612, "2588"], [1546502118.612, "2602"], [1546502132.612, "2616"], [1546502146.612, "2630"], [1546502160.612, "2644"], [1546502174.612, "2658"], [1546502188.612, "2672"], [1546502202.612, "2686"], [1546502216.612, "2699"], [1546502230.612, "2713"], [1546502244.612, "2727"], [1546502258.612, "2741"], [1546502272.612, "2755"], [1546502286.612, "2769"], [1546502300.612, "2783"], [1546502314.612, "2797"] ] }] } } |
所以,prometheus的API可以按照一定的分辨率(也叫做resolution,这里是14秒),在某个时间区间内,多次执行你传入的promql,计算出一组instant-vector,画成graph。
关于range-vector
那么range-vector有啥用?根据我的了解,它存在的意义就是为了计算输出instant-vector,没有直接使用range-vector的场景。
我们打开https://prometheus.io/docs/prometheus/latest/querying/functions/, 然后搜索range-vector,你会发现只有极少数的promql函数支持range-vector。
比如rate的输入就是range-vector,它基于某个时间之前的N分钟的数据,基于这些数据计算出平均增长速率instant-vector:
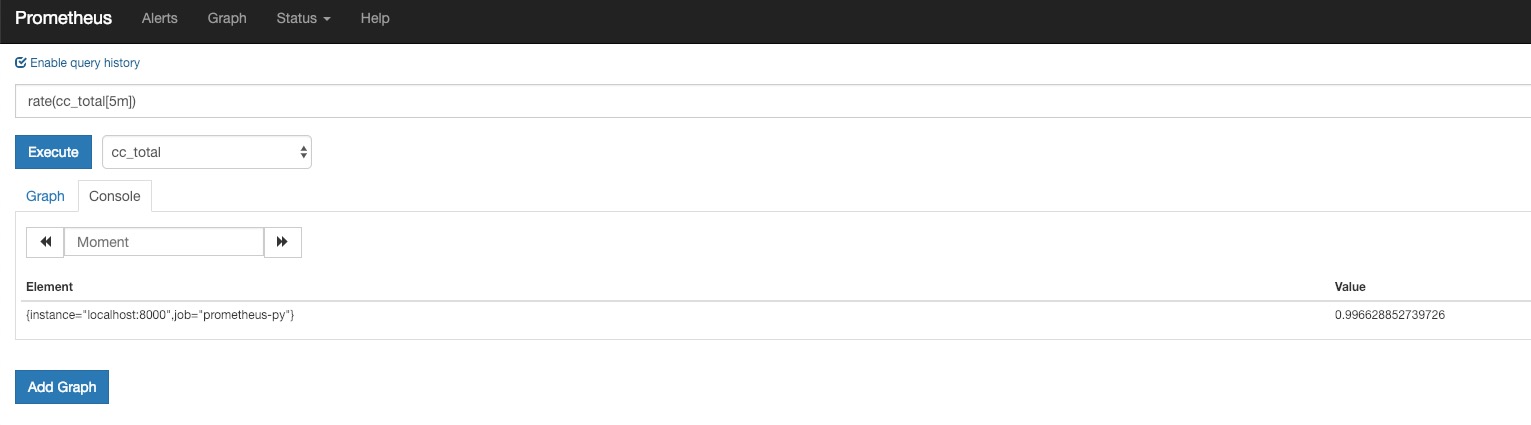
既然rate输出的是Instant-vector,那么就可以基于不同的时间点多次执行该promql,得到多个时间点的平均速率,画出graph:
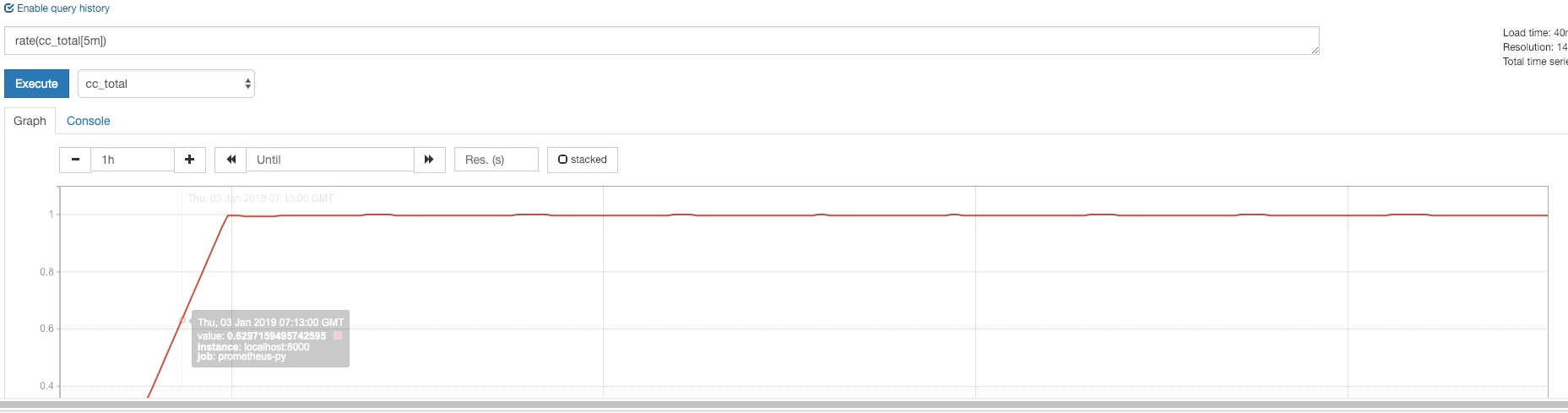
对应的ajax应答如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 |
{ "status": "success", "data": { "resultType": "matrix", "result": [{ "metric": { "instance": "localhost:8000", "job": "prometheus-py" }, "values": [ [1546499398.215, "0.026396267733028656"], [1546499412.215, "0.07305640195518313"], [1546499426.215, "0.11972317449434353"], [1546499440.215, "0.166386525184505"], [1546499454.215, "0.2130632889961165"], [1546499468.215, "0.25971655888285766"], [1546499482.215, "0.30638659048037653"], [1546499496.215, "0.35305326730473147"], [1546499510.215, "0.396371639525178"], [1546499524.215, "0.44303290027667513"], [1546499538.215, "0.48970388031408923"], [1546499552.215, "0.5363713689466918"], [1546499566.215, "0.5830453701322819"], [1546499580.215, "0.6297159495742595"], [1546499594.215, "0.6763665075604202"], [1546499608.215, "0.7230336145812694"], [1546499622.215, "0.7697039929353097"], [1546499636.215, "0.8163743280804222"], [1546499650.215, "0.8630446270227975"], [1546499664.215, "0.9097015910342392"], [1546499678.215, "0.9563751580971893"], [1546499692.215, "0.9966321858685584"], [1546499706.215, "0.9966355190196854"], [1546499720.215, "0.9966388521931071"], [1546499734.215, "0.9932944265146069"], [1546499748.215, "0.9932711730632883"], [1546499762.215, "0.9932844606164385"], [1546499776.215, "0.9932944265146069"], [1546499790.215, "0.9932944265146069"], [1546499804.215, "0.9932977485251032"], [1546499818.215, "0.9966221865489449"], [1546499832.215, "0.9966321858685584"], [1546499846.215, "0.9966255196331881"], [1546499860.215, "0.9966355190196853"], [1546499874.215, "0.9966321858685584"], [1546499888.215, "0.9966788520132578"], [1546499902.215, "0.9966288527397262"], [1546499916.215, "0.9966255196331881"], [1546499930.215, "0.9966321858685584"], [1546499944.215, "0.9966355190196853"], [1546499958.215, "0.9966388521931071"], [1546499972.215, "0.9966321858685584"], [1546499986.215, "0.9966321858685584"], [1546500000.215, "0.9966388521931071"], [1546500014.215, "0.9966255196331881"], [1546500028.215, "0.9999732448630139"], [1546500042.215, "0.9999832778716072"], [1546500056.215, "0.9999832778716075"], [1546500070.215, "0.9999665563024648"], [1546500084.215, "0.9999732448630139"], [1546500098.215, "0.9966288527397262"], [1546500112.215, "0.9966221865489449"], [1546500126.215, "0.9966388521931071"], [1546500140.215, "0.9966321858685584"], [1546500154.215, "0.9966355190196854"], [1546500168.215, "0.9966221865489446"], [1546500182.215, "0.9966221865489449"], [1546500196.215, "0.996628852739726"], [1546500210.215, "0.9966388521931071"], [1546500224.215, "0.9966388521931071"], [1546500238.215, "0.9966255196331881"], [1546500252.215, "0.9966321858685584"], [1546500266.215, "0.9966288527397262"], [1546500280.215, "0.9966255196331881"], [1546500294.215, "0.996642185388824"], [1546500308.215, "0.9966388521931071"], [1546500322.215, "0.996628852739726"], [1546500336.215, "0.996628852739726"], [1546500350.215, "0.9966355190196853"], [1546500364.215, "0.9966288527397262"], [1546500378.215, "0.9966388521931071"], [1546500392.215, "0.9999732448630139"], [1546500406.215, "0.9999832778716075"], [1546500420.215, "0.9999765891768421"], [1546500434.215, "0.9999732448630139"], [1546500448.215, "0.99997993351304"], [1546500462.215, "0.9999765891768421"], [1546500476.215, "0.9966255196331881"], [1546500490.215, "0.9966188534869955"], [1546500504.215, "0.996642185388824"], [1546500518.215, "0.9966355190196853"], [1546500532.215, "0.996638852193107"], [1546500546.215, "0.9966355190196853"], [1546500560.215, "0.9966221865489449"], [1546500574.215, "0.9966321858685584"], [1546500588.215, "0.9966388521931071"], [1546500602.215, "0.9966221865489449"], [1546500616.215, "0.9966355190196853"], [1546500630.215, "0.9966388521931071"], [1546500644.215, "0.9966355190196853"], [1546500658.215, "0.9966355190196854"], [1546500672.215, "0.9966321858685584"], [1546500686.215, "0.9966355190196854"], [1546500700.215, "0.9966255196331881"], [1546500714.215, "0.9966255196331881"], [1546500728.215, "0.9966288527397262"], [1546500742.215, "0.9966321858685584"], [1546500756.215, "0.9966421853888243"], [1546500770.215, "0.9999765891768421"], [1546500784.215, "0.9999665563024648"], [1546500798.215, "0.9999665563024648"], [1546500812.215, "0.9999699005715545"], [1546500826.215, "0.9966288527397262"], [1546500840.215, "0.9966221865489449"], [1546500854.215, "0.9966321858685584"], [1546500868.215, "0.9966255196331881"], [1546500882.215, "0.9966188534869955"], [1546500896.215, "0.9966355190196854"], [1546500910.215, "0.9966288527397262"], [1546500924.215, "0.9966288527397262"], [1546500938.215, "0.9966355190196854"], [1546500952.215, "0.9966255196331881"], [1546500966.215, "0.9966188534869955"], [1546500980.215, "0.9966188534869955"], [1546500994.215, "0.9966221865489446"], [1546501008.215, "0.9966188534869955"], [1546501022.215, "0.9966255196331881"], [1546501036.215, "0.9966255196331881"], [1546501050.215, "0.9966121874299779"], [1546501064.215, "0.9966288527397262"], [1546501078.215, "0.9966188534869955"], [1546501092.215, "0.9966221865489449"], [1546501106.215, "0.9966255196331881"], [1546501120.215, "0.9999799335130399"], [1546501134.215, "0.9999765891768421"], [1546501148.215, "0.996628852739726"], [1546501162.215, "0.9966388521931071"], [1546501176.215, "0.9966355190196854"], [1546501190.215, "0.996628852739726"], [1546501204.215, "0.9966321858685584"], [1546501218.215, "0.9966321858685584"], [1546501232.215, "0.9966221865489449"], [1546501246.215, "0.9966321858685584"], [1546501260.215, "0.9966221865489449"], [1546501274.215, "0.9966321858685584"], [1546501288.215, "0.9966321858685584"], [1546501302.215, "0.9966388521931071"], [1546501316.215, "0.9966321858685584"], [1546501330.215, "0.9966355190196853"], [1546501344.215, "0.9966321858685584"], [1546501358.215, "0.9966355190196854"], [1546501372.215, "0.9966355190196854"], [1546501386.215, "0.9966355190196854"], [1546501400.215, "0.9966355190196853"], [1546501414.215, "0.9966321858685584"], [1546501428.215, "0.9966355190196853"], [1546501442.215, "0.9999732448630139"], [1546501456.215, "0.9999732448630139"], [1546501470.215, "0.9966255196331884"], [1546501484.215, "0.9966321858685584"], [1546501498.215, "0.9966321858685584"], [1546501512.215, "0.9966321858685584"], [1546501526.215, "0.9966321858685584"], [1546501540.215, "0.9966355190196853"], [1546501554.215, "0.9966355190196853"], [1546501568.215, "0.9966321858685584"], [1546501582.215, "0.9966321858685584"], [1546501596.215, "0.9966355190196854"], [1546501610.215, "0.9966355190196854"], [1546501624.215, "0.9966321858685584"], [1546501638.215, "0.9966355190196854"], [1546501652.215, "0.996642185388824"], [1546501666.215, "0.996628852739726"], [1546501680.215, "0.9966388521931071"], [1546501694.215, "0.9966455186068367"], [1546501708.215, "0.9966355190196854"], [1546501722.215, "0.9966288527397262"], [1546501736.215, "0.9966321858685584"], [1546501750.215, "0.9966321858685584"], [1546501764.215, "0.9966388521931071"], [1546501778.215, "0.9999799335130399"], [1546501792.215, "0.9999832778716072"], [1546501806.215, "0.9999799335130399"], [1546501820.215, "0.999989966655853"], [1546501834.215, "0.9999765891768421"], [1546501848.215, "0.9966388521931071"], [1546501862.215, "0.9966355190196854"], [1546501876.215, "0.9966355190196853"], [1546501890.215, "0.9966321858685584"], [1546501904.215, "0.9966388521931071"], [1546501918.215, "0.9966388521931071"], [1546501932.215, "0.9966288527397262"], [1546501946.215, "0.9966355190196854"], [1546501960.215, "0.996628852739726"], [1546501974.215, "0.996628852739726"], [1546501988.215, "0.9966355190196853"], [1546502002.215, "0.9966321858685584"], [1546502016.215, "0.9966255196331881"], [1546502030.215, "0.9966388521931071"], [1546502044.215, "0.9966321858685584"], [1546502058.215, "0.996628852739726"], [1546502072.215, "0.9966221865489449"], [1546502086.215, "0.9966388521931071"], [1546502100.215, "0.9966321858685584"], [1546502114.215, "0.9966321858685584"], [1546502128.215, "0.9966355190196854"], [1546502142.215, "0.9999832778716075"], [1546502156.215, "0.9999732448630135"], [1546502170.215, "0.9999765891768421"], [1546502184.215, "0.9999665563024648"], [1546502198.215, "0.9999699005715545"], [1546502212.215, "0.9966288527397262"], [1546502226.215, "0.9966188534869955"], [1546502240.215, "0.996628852739726"], [1546502254.215, "0.996628852739726"], [1546502268.215, "0.9966321858685584"], [1546502282.215, "0.9966255196331884"], [1546502296.215, "0.9966355190196853"], [1546502310.215, "0.9966188534869955"], [1546502324.215, "0.9966188534869957"], [1546502338.215, "0.9966188534869957"], [1546502352.215, "0.9966255196331881"], [1546502366.215, "0.996628852739726"], [1546502380.215, "0.9966255196331884"], [1546502394.215, "0.9966455186068367"], [1546502408.215, "0.996642185388824"], [1546502422.215, "0.9966288527397262"], [1546502436.215, "0.996628852739726"], [1546502450.215, "0.9966388521931071"], [1546502464.215, "0.9966455186068367"], [1546502478.215, "0.9966355190196854"], [1546502492.215, "0.9966388521931071"], [1546502506.215, "0.999989966655853"], [1546502520.215, "0.9999765891768421"], [1546502534.215, "0.9999832778716075"], [1546502548.215, "0.999989966655853"], [1546502562.215, "0.999989966655853"], [1546502576.215, "0.9999933110815313"], [1546502590.215, "0.999989966655853"], [1546502604.215, "0.9966321858685584"], [1546502618.215, "0.9966355190196853"], [1546502632.215, "0.996642185388824"], [1546502646.215, "0.9966221865489449"], [1546502660.215, "0.9966355190196853"], [1546502674.215, "0.9966488518471448"], [1546502688.215, "0.9966288527397262"], [1546502702.215, "0.9966455186068367"], [1546502716.215, "0.9966221865489449"], [1546502730.215, "0.9966355190196854"], [1546502744.215, "0.9966388521931071"], [1546502758.215, "0.9966221865489449"], [1546502772.215, "0.9966288527397262"], [1546502786.215, "0.9966355190196853"], [1546502800.215, "0.9966421853888243"], [1546502814.215, "0.9966355190196853"], [1546502828.215, "0.9966321858685584"], [1546502842.215, "0.9966188534869955"], [1546502856.215, "0.9966355190196854"], [1546502870.215, "0.9966221865489449"], [1546502884.215, "0.9966255196331884"] ] }] } } |
再说一个容易陷入误区的理解,就是想当然的认为avg,sum等函数是对range-vector作用的,这是完全错误的!
avg/sum等聚合函数,都是作用在instant-vector上的,它们在一组不同label的instant-vector之间求它们的sum或者求avg,而不是对同一个metrics的range-vector做avg/sum。
instant-vector向量之间运算
不同的instant-vector之间可以做加减乘除运算,比如:rate(cc_total[5m]) / rate(cc_total[6m]) 这样毫无意义的计算,这只是举个栗子。
向量之间运算分为2个过程,先匹配、后计算。
匹配只指通过on/ignoring/group_left/group_right语法,令左侧instant-vector的label和右侧instant-vector的可以基于同样的label以及label value而匹配。比如,左侧vector有一个label叫做port=8080,而右侧vector没有这个label或者label=9999,那么此时可以通过ignoring(port)来忽略掉port,从而实现左右两侧label的匹配。(仅仅语法是这样工作的,实际怎么匹配需要根据需求来定,不是为了匹配而匹配)
匹配的vector之间可以进行后续加减乘除计算,就和mysql的跨表join一样,如果一个左侧vector可以匹配多个右侧vector就用group_right,这叫做one-to-many;如果一个右侧vector可以匹配多个左侧vector就用group_right,这叫做many-to-one。如果一个左侧匹配一个右侧就不用group指令,直接加减乘除运算即可,这就是one-to-one。
prometheus不支持笛卡尔乘积的计算,即不支持many-to-many:
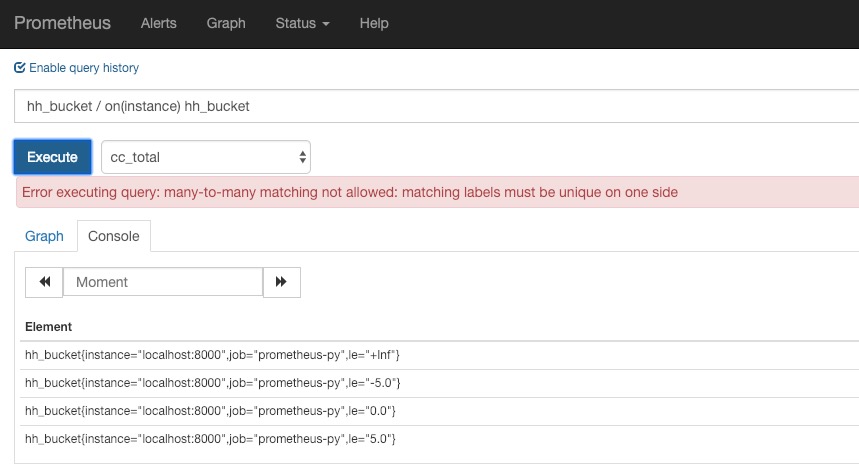
左侧hh_bucket有4个instant-vector,右侧是同样的hh_bucket的4个instant-vector。
如果按instantce标签匹配的话,左侧的4个vector和右侧的4个vector是many-to-many的匹配,所以无法计算。
但如果我让右侧通过avg把4个vector计算成1个vector,然后再用左侧的4个vector做many-to-one到右侧的1个vector,这样就不报错了:
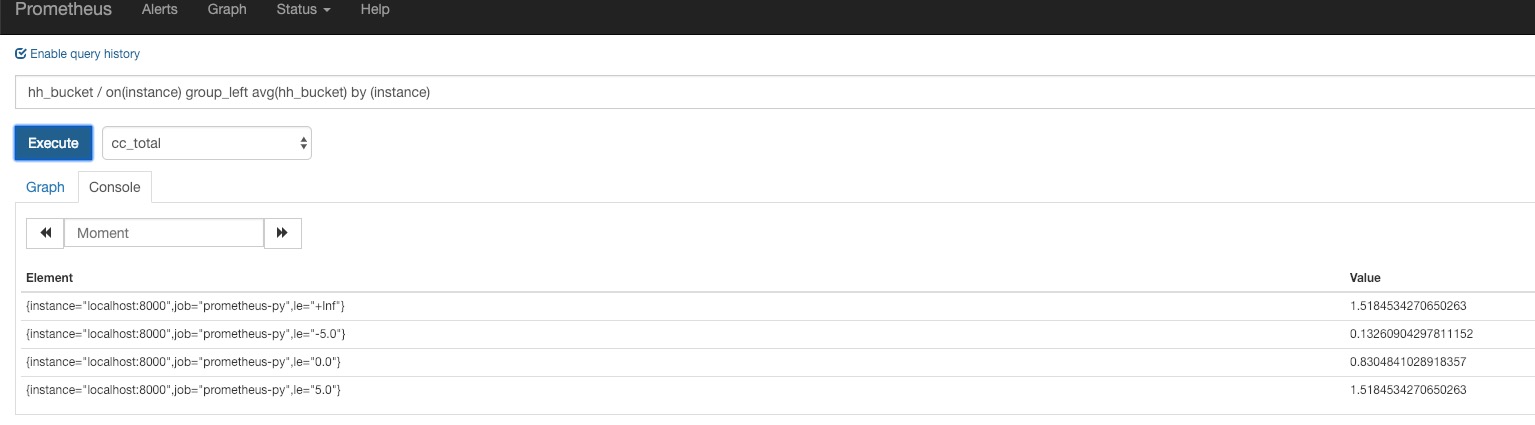
当然,上面的例子没有任何意义,仅仅是语法正确。
最后
关于prometheus先总结这些,后续grafana通过调用prometheus API执行promql得到数据点,可以直接画出漂亮的图表,有了prometheus认识基础就会容易很多。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

老师可否转发你的文章
可否转发你的文章
可以呀,注明出处~
没搞懂 puthon的这个prometheus-client到底是干啥的?
没搞懂 puthon的这个prometheus-client到底是干啥的?
理解的很到位,学习了
1