如何处理发布系统的异常情况
我司使用ansible playbook完成VM主机集群的代码部署,其实无论你使用什么开源工具,本质上就是连到每台机器上把代码切换到对应的版本。
发布系统的难点在于异常处理,比较典型的异常包括:
- 发布任务在某些机器上hung住了,导致发布超时,状态未知
- 同一个项目的新/旧发布任务并行,无法获知最终部署了哪个版本的代码
如果我们去看本质,发布平台和集群之间的关系是分布式调用关系,在这种系统中异常是再正常不过的事情,类似于请求重放、请求延迟送达、请求超时、请求丢失,都非常正常。
再次分析上面的异常case,其本质总结如下3点:
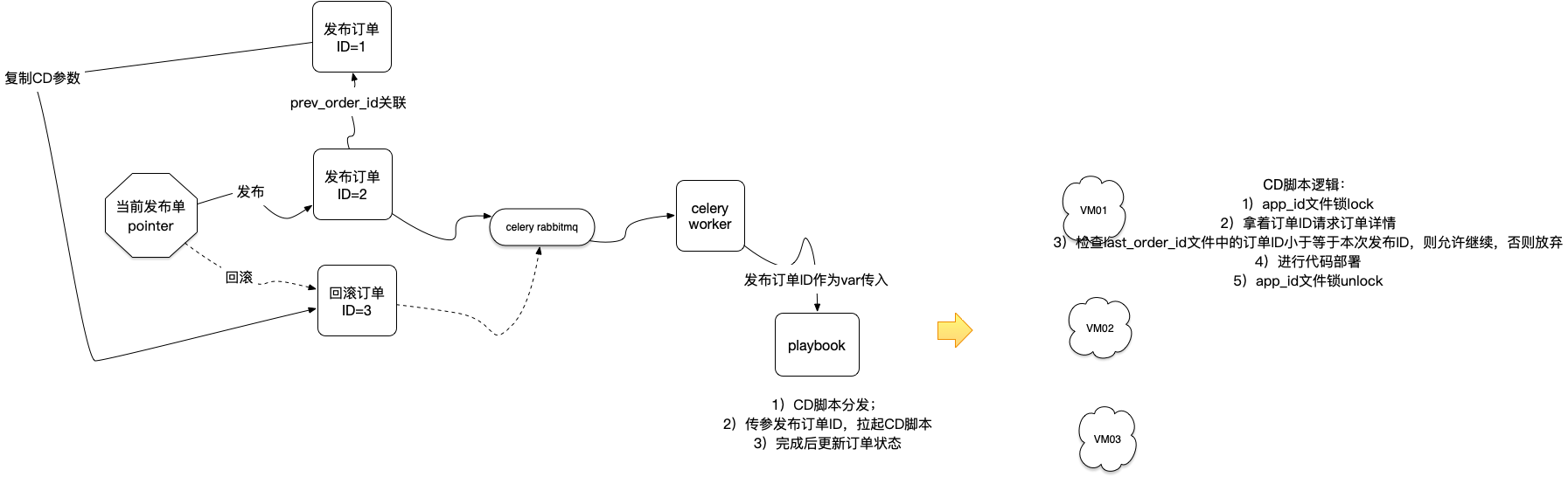
- 最终一致:异常是必然的,强一致是不可能的,异常过程中一定会不一致,发布系统不可能知道主机的状态,因此我们应该追求最终一致。
- 防止并发:同一个项目在同一台主机上,发布任务不允许并发,否则一切都可能错乱。
- 防止回退:同一个项目在同一台主机上,一个被延迟到达的旧发布任务应该被禁止覆盖已经生效的新发布任务。
对应的解决方法是:
- 防止并发:同一个项目在同一台主机上的发布脚本,需要先上本机文件锁🔒,再进行部署流程。
- 防止回退:同一个项目在同一台主机需要维护一个last term id的文件,记录最近一次部署的发布单ID;同时,发布平台无论是发布还是回滚,都应该对应一个新建的发布单,其ID自增作为term id带给目标主机;目标主机的原则是:拒绝term更小的任务,执行term更大的任务。(别忘记有锁保护)
- 人工介入:上述2个机制结合起来可以确保底层不会出错,但没法确保任务一定成功,出于系统实现的简洁性考虑,我们在发布遇到任何异常时直接告警给操作人或者运维介入,介入者要做的事情就是新建一个term id更大的发布单,再次推送给集群并等待全部成功,一旦有任何异常那么继续人工介入重发,如果连续发布失败,那么运维介入对故障机器进行人工摘除即可。
解决此类问题,关键是认识分布式环境中异常的必然性,然后分析当前问题的本质是什么,才能给出正确的对策,并允许一定的人工介入环节,避免架构设计过度复杂化。
在和群友的讨论过程中,很常见的观点就是认为在发布平台这一端做好并发保护即可,这是因为没有意识到发布平台和集群主机之间的分布式调用关系导致的,实际上只有在主机端做好健壮性实现才是问题解决的关键。
最后附上设计图:
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
1
1