apache flink 入门
现在非常流行流式计算,尤其在推荐领域特别需要实时的用户行为特征,以便满足用户短期的偏好。
流式计算存在已久,早期的有storm和spark streaming,而flink作为后起之秀已经成为主流选择,这很大成都上得益于flink的特性之强大,也就是提供了基于窗口的计算能力,从而可以实现诸如:统计5分钟内访问最多的N个商品等复杂计算场景。
无论你现在是否需要流式计算,我都建议你先来体验一下flink,它的确是一个非常强大的工具。
这篇博客的目的是:
- 从纯小白的角度,安装idea+java+flink开发环境。
- 搭建完整的流式计算pipeline示例,包括:输入、计算、输出。
搭建过程完全参照flink官方手册,代码示例经过我的一定扩展延伸。
安装环境
在mac或者linux都可以,我个人是在mac。
我们需要安装这些东西:
- JDK 1.8:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- maven:brew install maven
- flink:brew install apache-flink
- idea社区版:https://www.jetbrains.com/idea/download/#section=mac
然后需要给maven换源,否则后续flink项目的一些jar包是无法下载成功的。
maven默认会去当前用户HOME目录下,寻找.m2/settings.xml文件,所以我在mac上创建了这个文件:
|
1 |
vim /Users/smzdm/.m2/settings.xml |
这里只需要写2个涉及到的镜像地址(世界上有很多maven仓库,如果你碰到下载失败,可以根据aliyun提供的镜像仓库添加对应的mirror即可):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
cat /Users/smzdm/.m2/settings.xml <settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"> <mirrors> <mirror> <id>apache snapshots</id> <name>apache snapshots</name> <url>https://maven.aliyun.com/repository/apache-snapshots</url> <mirrorOf>apache snapshots</mirrorOf> </mirror> <mirror> <id>central</id> <name>central</name> <url>https://maven.aliyun.com/repository/central</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> </settings> |
创建项目(基于命令行)
我们需要使用flink官方提供的maven脚手架来初始化项目,它做了2个事情:
- 生成项目的目录结构
- 生成pom.xml,里面配置了依赖、构建、打包
|
1 2 3 4 5 6 7 8 9 |
mvn archetype:generate \ -DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-java \ -DarchetypeVersion=1.9.0 \ -DgroupId=flink-demo1 \ -DartifactId=flink-demo1 \ -Dversion=0.1 \ -Dpackage=demo1 \ -DinteractiveMode=false |
- archetype开头的都是flink提供的脚手架地址,这样maven就会找到对应的脚手架来初始化项目了。
- groupId、artifactId、version是我们项目的信息,其中artifactId决定了生成的项目目录名。
- package挺重要的,是最终项目里面的class包名,需要写个正经的。
很快项目就初始化好了,你能看到这些信息:
|
1 2 3 4 5 6 7 8 |
[WARNING] CP Don't override file /Users/smzdm/IdeaProjects/flink-demo1/flink-demo1/src/main/resources [INFO] Project created from Archetype in dir: /Users/smzdm/IdeaProjects/flink-demo1/flink-demo1 [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 5.137 s [INFO] Finished at: 2020-01-21T11:12:55+08:00 [INFO] ------------------------------------------------------------------------ |
然后就可以进入flink-demo1目录了:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
smzdmdeMacBook-Pro-2:IdeaProjects smzdm$ cd flink-demo1/ smzdmdeMacBook-Pro-2:flink-demo1 smzdm$ find . . ./pom.xml ./src ./src/main ./src/main/resources ./src/main/resources/log4j.properties ./src/main/java ./src/main/java/demo1 ./src/main/java/demo1/BatchJob.java ./src/main/java/demo1/StreamingJob.java |
这是一个标准的maven项目,代码放在src/main/java下面,配置文件放在src/main/resources下面。
脚手架自带2个demo文件,一个做流式计算,一个做批量计算,我们删除它们即可。
rm src/main/java/demo1/*
然后在src/main/java/demo1下面创建一个我们自己的程序MyStreaming.java:
|
1 2 3 4 5 6 7 |
package demo1; public class MyStreaming { public static void main(String[] args) throws Exception { } } |
然后打开pom.xml,默认依赖库很多都是provided和runtime类型的,这样并不会把依赖类打到最终的jar包中,就会导致运行jar包的时候依赖class找不到,一般我们都是希望把依赖以及项目代码全部打包到一个jar包做发布的,所以我们都改成compile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
<dependencies> <!-- Apache Flink dependencies --> <!-- These dependencies are provided, because they should not be packaged into the JAR file. --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>compile</scope> </dependency> <!-- Add connector dependencies here. They must be in the default scope (compile). --> <!-- Example: <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> --> <!-- Add logging framework, to produce console output when running in the IDE. --> <!-- These dependencies are excluded from the application JAR by default. --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.7</version> <scope>compile</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> <scope>compile</scope> </dependency> </dependencies> |
另外,pom.xml最终是依靠maven-shade-plugin来打包jar的,我们希望它把我们的class以及依赖的所有class都打到一个jar里,为此我们需要做一些调整。
默认pom.xml中排除掉了log4j等库,这样jar中就缺少了这些依赖的class,所以我们注释掉exclude部分:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --> <!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.0.0</version> <executions> <!-- Run shade goal on package phase --> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <!-- <excludes> <exclude>org.apache.flink:force-shading</exclude> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> <exclude>log4j:*</exclude> </excludes> --> </artifactSet> |
然后在transformer部分修改一下jar包的main class,指向我们自定义的程序入口:
|
1 2 3 4 5 |
<transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>demo1.MyStreaming</mainClass> </transformer> </transformers> |
另外,我们还需要添加一个transformers来处理一个特殊问题:flink内部用了akka库,需要把akka库的配置文件reference.conf文件也打包到jar里,最终transformers部分就是这样:
|
1 2 3 4 5 6 7 8 |
<transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>demo1.StreamingJob</mainClass> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>reference.conf</resource> </transformer> </transformers> |
验证项目初始化正确
执行打包命令:
mvn package
在target目录下将生成包含完整依赖的jar包,并且jar包的程序入口是demo1.MyStreaming,所以我们只需要执行jar即可:
java -jar target/flink-demo1-0.1.jar
程序没有任何报错,就代表我们已经具备了开发flink应用的项目框架。
启动flink
flink由jobmanager和若干taskmanager组成,前者负责调度,后者负责执行任务。
现在我们利用brew info apache-flink看一下flink的安装目录:
|
1 2 3 4 5 |
smzdmdeMacBook-Pro-2:flink-demo1 smzdm$ brew info apache-flink apache-flink: stable 1.9.1, HEAD Scalable batch and stream data processing https://flink.apache.org/ /usr/local/Cellar/apache-flink/1.9.1 (172 files, 277.3MB) * |
然后进入/usr/local/Cellar/apache-flink/1.9.1。
编辑一下libexec/conf/flink-conf.yaml,将taskmanager可以处理的并发任务数量调高(slot就是线程,一般与核心数量相同):
|
1 2 3 |
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline. taskmanager.numberOfTaskSlots: 8 |
启动1个jobmanager(也就是flink的master):
|
1 |
libexec/bin/jobmanager.sh start |
然后启动1个taskmanager:
|
1 2 |
smzdmdeMacBook-Pro-2:1.9.1 smzdm$ libexec/bin/taskmanager.sh start Starting taskexecutor daemon on host smzdmdeMacBook-Pro-2.local. |
打开浏览器打开http://localhost:8081,可以看到管理界面了。
打开idea IDE
利用idea打开代码,它会提示识别到pom.xml,我们点击同意则项目被识别为一个maven项目。
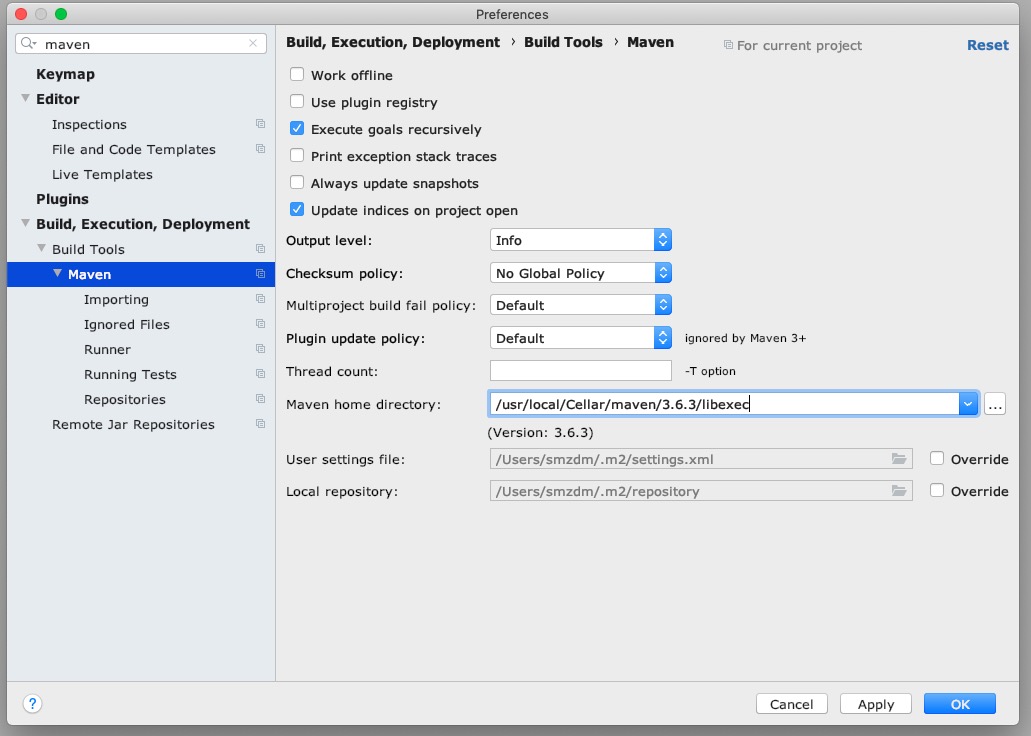
打开首选项,调整一下idea使用我们brew安装的maven而不是idea自带的maven:
然后右侧执行mvn package编译一下代码:
编译好之后的jar还是在target目录,右键执行即可:
编写代码
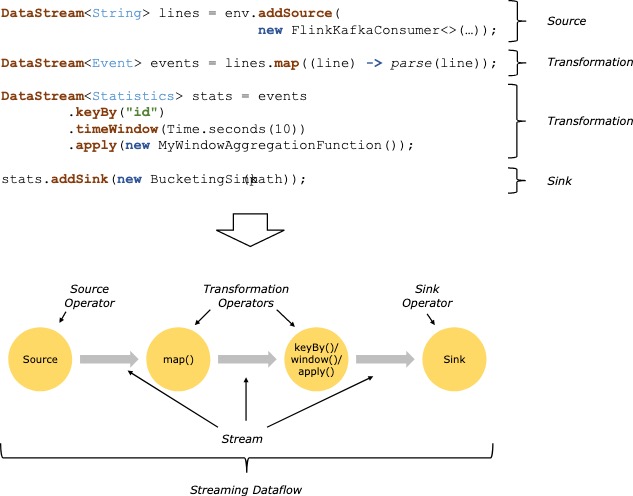
在flink中,数据需要从source流入,然后经过一系列transformation聚合统计的计算之后,再通过sink流出,其中source和sink一般就是kafka等队列。
我们要做的是自己实现source和sink,在source中源源不断的伪造”用户点击日志”,在agg阶段利用flink window窗口机制实现统计每5秒内各个用户的点击量,在sink阶段将每个window的统计结果打印出来。
flink官方给出了一个流程图如下:
更多编程上的理解大家自己阅读一下官方手册:
- https://ci.apache.org/projects/flink/flink-docs-release-1.9/concepts/programming-model.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.9/concepts/runtime.html
获取execution env
我们的程序最终打包成jar包,然后交给flink run命令来提交执行。
flink run会给我们的程序一些环境变量,这样我们main函数里可以获取到flink run指定的flink集群信息,对其进行计算图的提交。
|
1 2 3 4 |
public static void main(String[] args) throws Exception { // 获取flink集群环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); } |
自定义source
source就是数据源,大部分情况都是直接使用flink提供的kafka source。
为了演示,我们自定义一个DataSource,参考官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/datastream_api.html#data-sources
新建src/main/java/demo1/MySource.java,编写如下自定义Source:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
package demo1; import org.apache.flink.streaming.api.functions.source.SourceFunction; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Random; public class MySource implements SourceFunction<String> { // 是否终止source运行 private volatile boolean isRunning = true; // 随机数生成器 private Random rand; public MySource() { this.rand = new Random(); } @Override public void run(SourceContext<String> ctx) throws Exception { while (this.isRunning) { try { // 生成随机a~d的用户名 char username = 'a'; username = (char) (username + new Random().nextInt(26)); // 获取当前时间 Date now = new Date( ); SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); String time = dateFormat.format(now); // 生成一行日志 String log = String.format("%s\t%s", String.valueOf(username), time); // 吐出去 ctx.collect(log); // System.out.println(log); // 休眠10毫秒 Thread.sleep(10); } catch (Exception e) { } } } @Override public void cancel() { this.isRunning = false; } } |
根据官方手册说法,我们继承一下SourceFunction即可,模板参数是我们吐出去的数据类型。
- run方法:源源不断的向ctx提交输入,我们伪造日志行,其格式是”用户名 时间”。
- cancel方法:当任务被取消的死后,需要设置标记位,以便打断死循环的run方法。
然后把这个source添加到我们的计算拓扑图里:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
public class MyStreaming { public static void main(String[] args) throws Exception { // 获取flink集群环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 新建source MySource source = new MySource(); // 添加到env, 得到一个DataStream DataStream<String> sourceStream = env.addSource(source); } } |
自定义数据解析
我们可以把日志预先解析一下,这样方便后续高效处理。
flink内置TupleN类型,对于简单的数据结构比较适用。
我们新定义一个转换类MyMapper.java:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
package demo1; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; import java.text.SimpleDateFormat; import java.util.Date; public class MyMapper implements FlatMapFunction<String, Tuple2<String, Long>> { @Override public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception { // 按\t分割 String []fields = value.split("\t"); String username = fields[0]; String time = fields[1]; // 解析时间为unix时间戳 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); Date date = dateFormat.parse(time); Long ts = date.getTime(); // flink的时间都是毫秒 // 提交tuple out.collect(new Tuple2<>(username, ts)); } } |
它输入的是String原始日志,返回的是(username, timestamp)的二元组。
我们把这个类应用到flatMap方法,就可以对原始日志做进一步解析:
|
1 2 |
// 解析日志为若2元组 sourceStream.flatMap(new MyMapper()); |
提取event time,设置watermark
因为后续我们要在无边界的流数据中按一定的时间窗口进行统计,所以需要知道每一条数据的时间,以便落入正确的窗口进行计算。
但是数据被划入某个时间段的window后并不是立即计算,而是需要等待watermark的更新,一旦watermark大于了该window的结束时间,那么这个window中的数据才开始被聚合计算。
有一个博客总结的非常好,我把它引用过来,大家理解一下即可:
Window: Window是处理无界流的关键,Windows将流拆分为一个个有限大小的buckets,可以可以在每一个buckets中进行计算
start_time,end_time: 当Window时时间窗口的时候,每个window都会有一个开始时间和结束时间(前开后闭),这个时间是系统时间
event-time: 事件发生时间,是事件发生所在设备的当地时间,比如一个点击事件的时间发生时间,是用户点击操作所在的手机或电脑的时间
Watermarks: 可以把他理解为一个水位线,这个Watermarks在不断的变化,一旦Watermarks大于了某个window的end_time,就会触发此window的计算,Watermarks就是用来触发window计算的
我们要从日志中提取真正的event time,但是因为日志到达时会乱序,所以我们需要让window到期之后再延迟几秒等到delay到达的数据。
一个更好的方法是基于最新到达数据的event time,在其基础上减去一定的时间作为watermark,这样就可以让已经过期的window多等待一会,我们就使用这种方法。
自定义一个类叫做MyAssigner:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
package demo1; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks; import org.apache.flink.streaming.api.watermark.Watermark; import javax.annotation.Nullable; public class MyAssigner implements AssignerWithPunctuatedWatermarks<Tuple2<String, Long>> { @Nullable @Override public Watermark checkAndGetNextWatermark(Tuple2<String, Long> lastElement, long extractedTimestamp) { // System.out.println(extractedTimestamp); return new Watermark(extractedTimestamp - 2000); // 基于该日志时间倒退2秒作为watermark } @Override public long extractTimestamp(Tuple2<String, Long> element, long previousElementTimestamp) { // System.out.println(element); return element.f1; // 日志时间作为event time } } |
复写extractTimestamp方法,从tuple里提取出日志时间,作为event time,用于指导flink该数据落入哪个window。
复写checkAndGetNextWatermark方法,根据该event time倒退2秒作为watermark,这样就可以让已经过期的window可以延迟2秒进行最终计算。
然后设置flink基于event time来将数据划入window,同时设置我们的assginer从日志提取eventtime以及更新watermark:
|
1 2 3 4 |
// 设置按照event time计算日志落入哪个window env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // 定义如何为每条日志设置event time,以及基于日志的时间来更新watermark以便让过期窗口进行计算。 DataStream<Tuple2<String,Long>> timedStream = tupleStream.assignTimestampsAndWatermarks(new MyAssigner()); |
transformation:按username分组
正式进入计算环节。
我们希望是统计每个user在5秒内的点击次数,所以首先要按user聚合,每个user有各自的window进行统计。
这时候需要使用keyBy方法:
|
1 2 |
// 按tuple的第0列分组 KeyedStream<Tuple2<String,Long>, Tuple> keyedStream = timedStream.keyBy(0); |
transformation:划分窗口(window)
在无边界的流式数据中,我们按系统时间每5秒作为一个window,数据根据其event time落入对应区间的window,当watermark超过window的end_time时,该window中的所有数据被一次性计算。
划分窗口只需要调用window方法:
|
1 2 |
// 按eventime 5秒划分window,产生带边界的数据流 WindowedStream<Tuple2<String,Long>, Tuple, TimeWindow> windowStream = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(5))); |
transformation:自定义统计
最终我们需要定义一个统计方法,用于给每个window做计算,其输入就是window内的所有数据,它们当然一定属于同一个username,因为此前已经keyBy分组过了。
window展开来说又有很多概念,但是都不难理解,大家可以重点来看一下官方手册window部分:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/stream/operators/windows.html。
我演示一下用Aggregation方式来统计次数,我们新建一个MyAgg.java文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
package demo1; import org.apache.flink.api.common.functions.AggregateFunction; import org.apache.flink.api.java.tuple.Tuple2; public class MyAgg implements AggregateFunction<Tuple2<String,Long>, Tuple2<String,Integer>, Tuple2<String,Integer>> { @Override public Tuple2<String, Integer> createAccumulator() { return new Tuple2<>("",0 ); // 窗口计算前初始值 } // 窗口迭代计算 @Override public Tuple2<String, Integer> add(Tuple2<String, Long> value, Tuple2<String, Integer> accumulator) { // 迭代一条记录 accumulator.f0 = value.f0; // 设置username accumulator.f1 += 1; // 累计访问次数 // System.out.println(accumulator); return accumulator; } // 返回最终结果 @Override public Tuple2<String, Integer> getResult(Tuple2<String, Integer> accumulator) { // System.out.println(accumulator); return accumulator; } // 合并并发计算的2个中间结果 @Override public Tuple2<String, Integer> merge(Tuple2<String, Integer> a, Tuple2<String, Integer> b) { Tuple2<String, Integer> merged = new Tuple2<String, Integer>(); merged.f0 = a.f0; merged.f1 = a.f1 + b.f1; return merged; } } |
这个类用于对1个window做计算,accumulator表示中间计算结果,一开始需要初始化一个。
flink会不断的回调add让我们对当前窗口进行统计计算,我们需要不断的更新中间结果accumulator。
因为flink允许并行计算,可能同一个username被2个windows分别计算,最终再merge为一个结果。
getResult就是输出Output,我们做的仅仅是把中间结果直接返回即可。
把MyAgg添加到后续计算过程中:
|
1 2 |
// 聚合统计 DataStream<Tuple2<String, Integer>> aggStream = windowStream.aggregate(new MyAgg()); |
自定义sink输出
终于到了最后,每个window经过计算最终输出了一个tuple,就是当前5秒窗口的一个计数结果,他属于某个用户。
我们可以自定义一个sink把结果打印出来(真实情况应该是写到hbase/redis等存储):
|
1 2 3 4 5 6 7 |
// 输出结果 aggStream.addSink(new SinkFunction<Tuple2<String, Integer>>() { @Override public void invoke(Tuple2<String, Integer> value, Context context) throws Exception { System.out.println(value); // 仅仅是打印一下 } }); |
这里我直接输出到了终端,稍后我们基于本地模式调试运行代码,是可以看到每个计算环节的标准输出的。而最终代码如果打包成jar提交到flink,那么就只能去flink的web界面查看日志了。
提交计算图
最后调用env把计算任务提交到flink集群:
|
1 2 |
// 提交 env.execute("demo1"); |
运行代码
本地调试
写好flink代码后,我们可以在idea中点绿色小箭头运行MyStreaming.java,它会启动一套临时的flink集群环境,并且代码中的println都可以在终端看到。
我这里运行后,每隔5秒就会输出若干window的agg计算结果:
|
1 2 3 4 5 6 7 8 9 10 11 |
(p,16) (f,13) (p,16) (o,22) (o,22) (q,12) (q,12) (h,17) (h,17) (v,15) (v,15) |
其统计了最近5秒,各个用户的日志条数。
正式提交
我们只需要执行mvn package得到jar包,然后利用flink命令行工具正式向flink集群提交即可。
|
1 2 3 |
smzdmdeMacBook-Pro-2:flink-demo1 smzdm$ flink run -d target/flink-demo1-0.1.jar Starting execution of program Job has been submitted with JobID 4cfa618fb4ee4635fc7ce5d41d1df921 |
-d表示提交给flink就直接返回,如果不传则flink run命令会阻塞住,但是要注意flink run即便被杀死任务也已经提交到flink,不会因为终端程序杀死而取消任务。
我们可以打开http://localhost:8081/,查看任务的执行情况(但是并不直观。。。因为多个步骤都被flink作为一个task运行,所以看不出各个子阶段的输入输出次数):
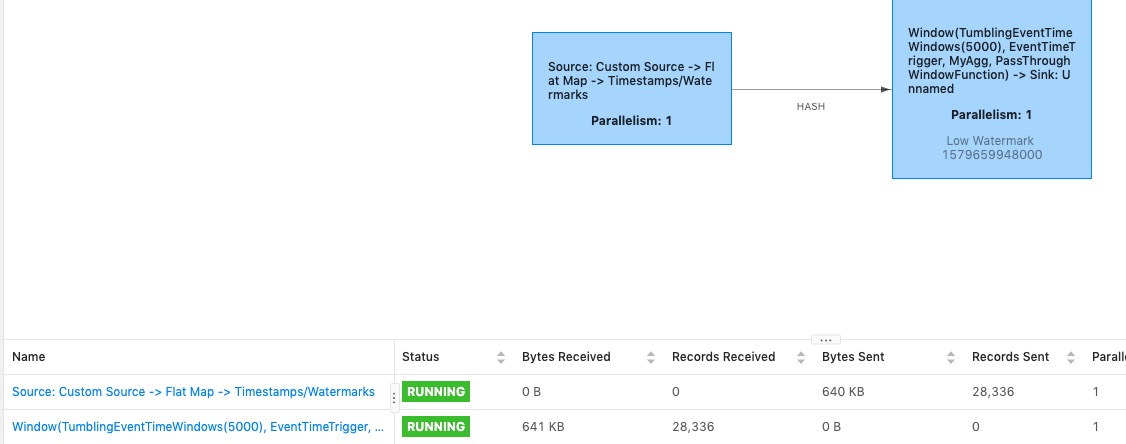
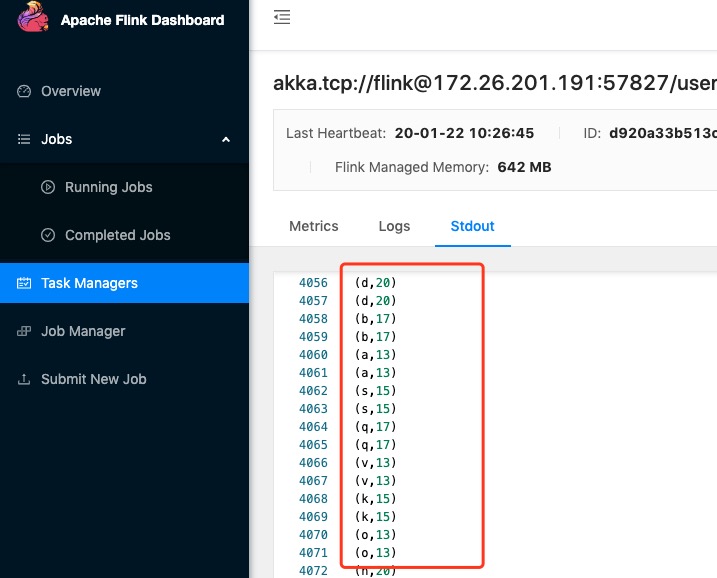
也可以通过查看taskManager看到终端日志输出:
如果要更新job代码,那么需要通过flink命令行或者web界面先杀死正在运行的,然后再重新提交一次jar;如果不杀死旧的而是直接重新提交一次jar,那么就会生成1个新job,老job也同时在运行,这个真是不方便。
其他
并发度
从flink web可以看出,这个任务目前被分为2个并行度为1的task,分别占用1个slot(也就是线程):
- source的task
- window -> sink的task
为了提高计算能力,我们可以根据需要配置各个步骤的并行度,可以从几个角度配置,具体见官方手册:https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/dev/parallel.html。
最简单的就是flink run提交任务的时候通过命令行参数指定一个并发度:
|
1 2 3 |
$ flink run -d -p 3 target/flink-demo1-0.1.jar Starting execution of program Job has been submitted with JobID 328bf297302d25e04a6240d32a09775c |
这样flink会自动的去增加每个计算步骤的并发线程数量,并自动做好shuffle。
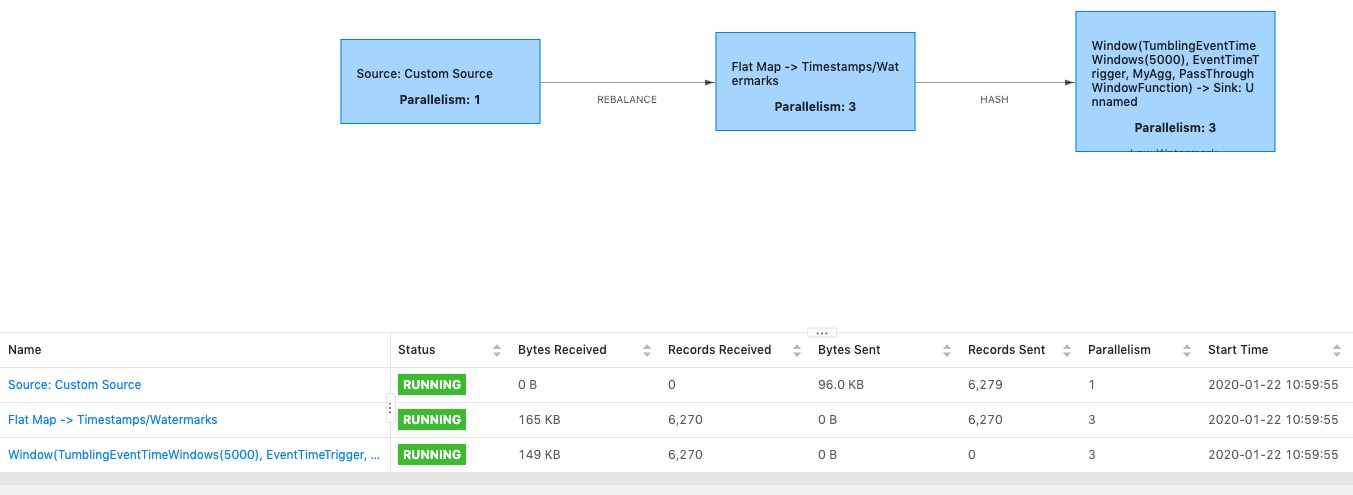
因为有了更高并发度,所以flink调度的时候已经把flatmap和window计算环节单独摘了出来作为新的task,并且并行度都被提高到了3个slot(线程)。
checkpoints
为了避免flink集群节点宕机导致某些正在计算中途的数据丢失,flink通过checkpoint定期备份来确保数据不会丢失,我们要做的主要是激活这个特性即可,具体参考文档:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/stream/state/checkpointing.html
我们要做的就是激活这个特性:
|
1 2 |
// 开启checkpoint, 2秒1次 env.enableCheckpointing(2000); |
checkpoints是每个flink节点都会去作的,所以checkpoint还需要我们指定一个分布式的文件系统来作存储,一般选择是hdfs,这里我就不展开了。
更复杂的拓扑
从我们上面的代码来看,每次都是基于上一个datastream执行增加新的算子得到新的datastream,整个流程是串行向后的。
实际上,我们完全可以基于上一个datastream做2个分叉出来,也就是对同一个datastream分别添加2次新算子,那么就会得到2个新的datastream,从而实现更复杂的计算拓扑。
比如我们把处理结果复制到2个sink各自打印:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
aggStream.addSink(new SinkFunction<Tuple2<String, Integer>>() { @Override public void invoke(Tuple2<String, Integer> value, Context context) throws Exception { System.out.println("哈哈" + value); // 仅仅是打印一下 } }); aggStream.addSink(new SinkFunction<Tuple2<String, Integer>>() { @Override public void invoke(Tuple2<String, Integer> value, Context context) throws Exception { System.out.println(value); // 仅仅是打印一下 } }); |
关于flink入门的部分就到这里,完整代码见github:https://github.com/owenliang/flink-demo1
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1