K8S – 压测导致应用间互相影响的问题(中)
在之前的博客中,我尝试通过调大conntrack表的hash桶数量来解决调用超时问题,但实际上线问题并没有明显减轻,所以我继续寻找原因,有了如下的新发现。
大家需要首先了解linux kernel中,关于SNAT实现的一个并发竞争bug:
https://mp.weixin.qq.com/s/VYBs8iqf0HsNg9WAxktzYQ
关于这个问题的更多分析,下面罗列了我收集的一些线索和分析,供大家参考解决。
官方kube-proxy的bugfix issue
在官方issue中有人提到,最新的release已经默认使用了random-fully选项,如果使用5.x内核则内核默认使用该选项。
采集inserted fail指标
有开源exporter可以采集到inserted_fail指标:https://github.com/jwkohnen/conntrack-stats-exporter
该项目中提供了3个有价值的外链,都是对该问题的复现与分析说明。
最新minikube(1.17)观察random-fully选项
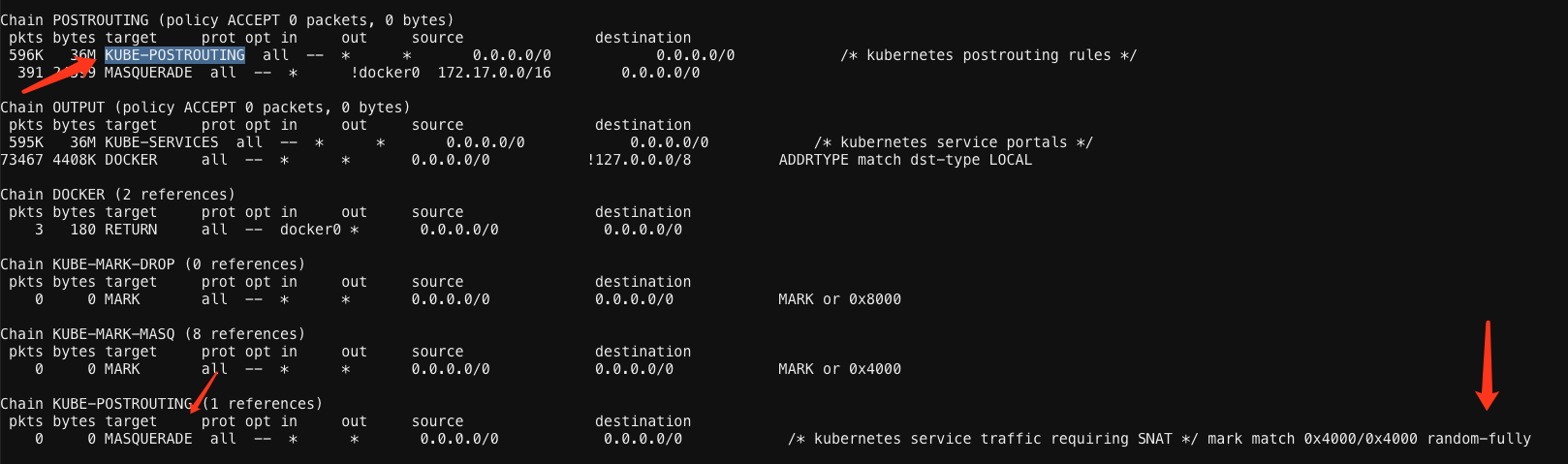
K8S官方在哪个版本修复?
最早修复release是1.16.0版本,更老的版本均没有修复。
线上流量分析
云厂商cni采用的是扁平网络,我把流量分为3类:
- 集群外 -> node1 -> node2 -> pod : 这种情况node1上会命中PREROUTING的KUBE-SERVICE链打mark作DNAT,在POSTROUTING走masquerade转发给node2。
- pod1 -> service -> pod2:这种情况会过OUTPUT的KUBE-SERVICE链打mark作DNAT,在POSTROUTING走masquerade转发给pod2。
- pod1 -> redis/mysql/vm:这种情况OUTPUT不会命中KUBE-SERVICE,因此在POSTROUTING没有命中mark,所以直接发往redis,没做源地址转换。
目前我们被场景1和场景2严重影响,导致conntrack insert fail经常出现,压力大时更加严重,大量TCP重传可以被监控捕获。
修复方法暂时只有依靠random-fully缓解。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
1
1