kubernetes – arp缓存错误问题完整分析过程
kubernetes网络问题接二连三,这周分析了一个大2层网络的大坑,下面给大家分享一下整个过程。
阶段1
- VM集群调用K8S集群内的category应用,出现少量超时问题,询问得知category刚刚重新发布一次。
- 根据cat观察调用链,发现category自身没有超时处理,仅仅是category调用方意识到超时。
- 根据category的cat超时调用链,找到了处理请求的category POD是哪个。
- 进入category POD,观察php-fpm活跃进程数正常,tshark抓包观察到较多TCP重传,观察其他category POD并没有重传。
- 进一步观察k8s集群其他应用没有超时问题,开始打消对k8s node级故障的怀疑,目光聚焦在该问题POD。
问题POD内的TCP重传:

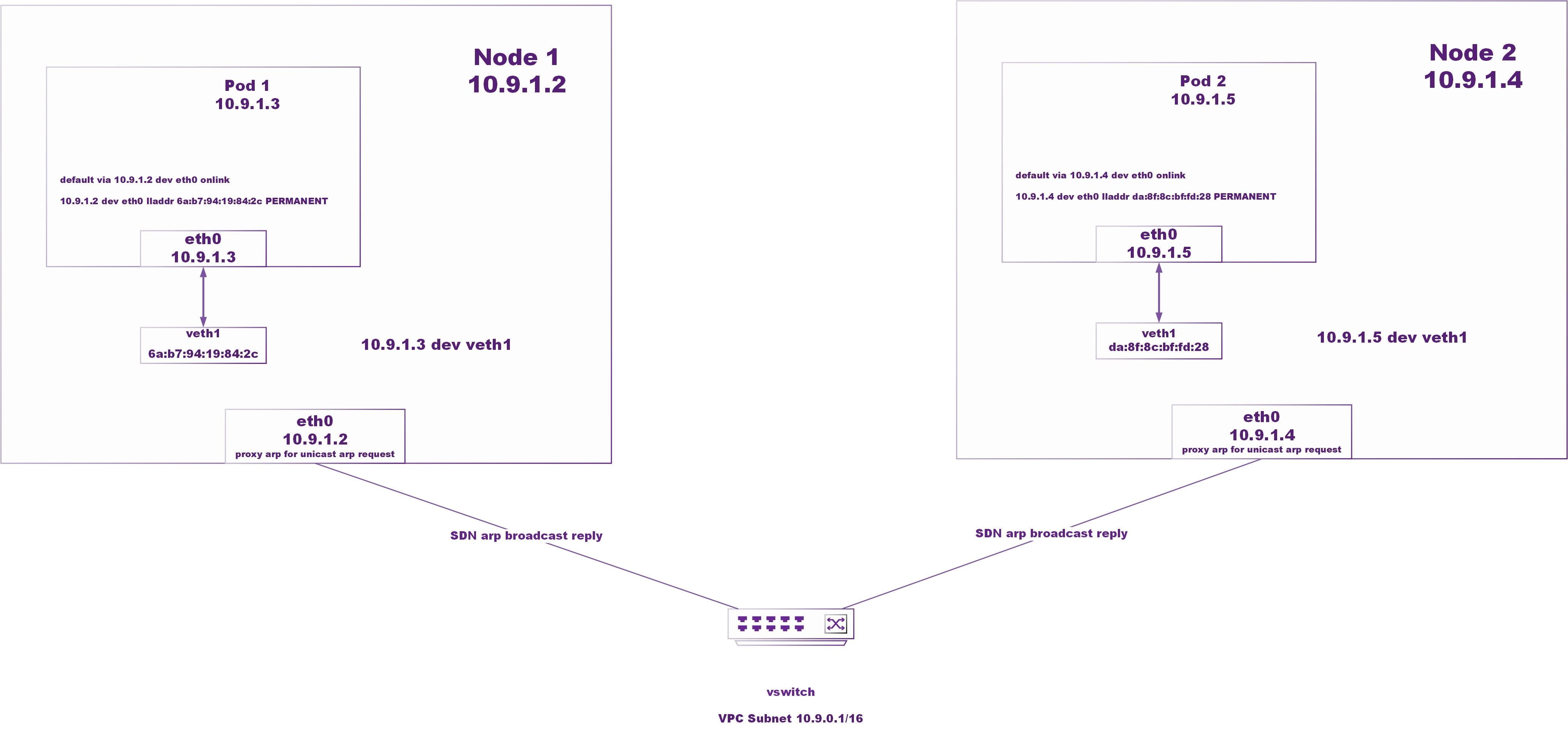
Ucloud扁平网络架构:
阶段2
- 在category问题POD内tshark抓包809端口(应用监听端口),观察TCP重传来源,发现来源IP都是同1个node。
- 对该问题node进行tshark抓包,的确收到来自问题POD的SYN+ACK重传,推断node发往POD的握手ack丢包。
- 分析问题node的3~4层,是否存在异常,然而conntrack发现没有异常。
- 分析问题node的4层,在问题node仅能抓到与问题pod发生重传,与其他POD没有异常。
- 分析问题node的2层,偶然发现node上ARP缓存的POD mac地址与其他node不一致,经确认该错误mac地址并不是POD所在node的mac,而是其他某个node。
- 根据Ucloud扁平网络架构,明确POD默认网关是所在node(node的mac地址是cni直接设置到POD的arp cache中的),所以实际2层在物理网络上用的是node的arp cache。
其他正常node缓存的pod mac:

问题node缓存的pod mac:

阶段3
- 开始怀疑错误mac地址是否是SDN代答错误导致,结果在问题node清理arp cache后立即刷到了正确的POD mac地址(也就是pod所在node的mac),基本排除SDN问题。
- 为了复现问题,尝试反复发布commonservice应用,再次触发了同样的现场,
- 这里给各个问题起一个代号方便描述:
-
- 问题node:是指arp cache错误POD MAC的node。
- 中间商node:是指问题node缓存的错误mac地址所指向的node。
- 目标node:是POD真正所在的node。
- 问题pod:就是指内部有TCP重传的问题pod
-
- 在问题node模拟curl请求直接发往POD,观察流量绕道中间商node是否能触达问题pod。
- 发现curl请求每次会卡6秒,然后才返回页面,期间curl反复的重传握手ACK给问题POD,直到6秒后正常通讯往返正常。
- 对流量路径进行分析:
-
- 因为中间商node也是开启ipv4 forward的,因此流量绕道中间商node可以被forward到目标node,因为中间商node对问题POD的mac地址解析正确,因此可以2层送达目标node,进而进入问题POD。
- 问题POD返回给问题node的回包dst ip是问题node,直接可以2层送回给问题node的mac地址,因此回程数据不经过中间商node。
-
- 基于对流量路径的分析,在问题node,中间商node,目标node 3个点tshark抓去程包、回程包,验证了想法。
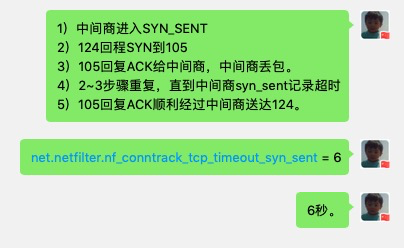
- 基于对流量路径的分析,观察了中间商node、目标node的conntrack记录,观察到中间商node conntrack记录大量处于SYN_SENT与CLOSE_WAIT状态。
- 经过进一步curl模拟与抓包观察,中间商node的conntrack记录是经过SYN_SENT后一段时间才进入CLOSE_WAIT。
- 进一步分析,因为问题POD回程到问题node不经过中间商node,所以中间商conntrack的TCP状态机实际是半匹配状态,没有机会收到问题POD回复的SYN+ACK包,所以一直处于client side的SYN_SENT状态。
- 偶然观察到conntrack的sysctl配置net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 6,意识到curl卡住6秒是因为中间商的SYN_SENT记录过期淘汰,进而下次问题node回复的握手ack正确被conntrack状态机识别,作为一条新trace的连接处理,后续流量得以恢复。
- 在中间商node的iptables mangle表增加关于conntrack invalid包的日志输出,观察到PREROUTING/FORWARD链出现了大量invalid包判定,大概率怀疑就是因为中间商node的conntrack半匹配状态问题导致主动丢包。
分析当晚的一个重要结论:
conntrack的状态机:
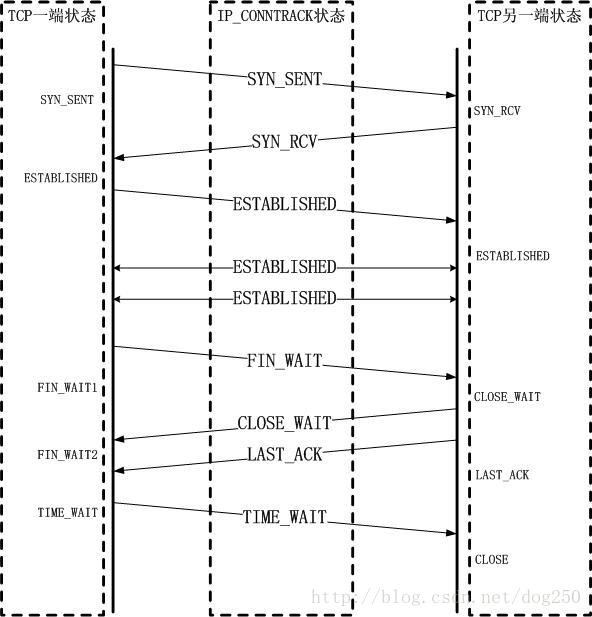
阶段4
- 在线下环境尝试复现conntrack半匹配丢包问题,模拟场景: “利用curl,在问题node默认网关到中间商node进而请求到baidu.com,并且令”中间商node不做SNAT,因此baidu.com回包将不经过中间商node直接发回给问题node”。
- 发现curl并不会复现出6秒卡顿现象,抓包确认去程和回程的路径和线上K8S集群一致,但tshark抓包发现问题node没有任何TCP重传非常顺畅,中间商node虽然也因为半匹配问题有invalid log,但也正常的forward流量给baidu.com了。
- 此时开始逐渐打消conntrack因为半匹配情况而主动丢包的怀疑,进一步阅读linux内核tcp conntrack部分源码,观察到如果是conntrack因为状态机不对主动丢包,则conntrack -S会有drop计数器,然而发现线上conntrack drop计数器是0。
- 结合未能复现的情况以及对drop计数器代码的了解,开始怀疑是不是k8s下发的iptables规则有对invalid包的drop,因为模拟环境的中间商node上并没有运行k8s,这是唯一的一个模拟差异点。
- 经过对线上k8s的ipables规则观察,发现filter表kube-forward链有一条对invalid的drop规则,可以命中该场景的握手ack包进而导致drop丢弃。
- 于是在模拟环境的中间商node的filter表添加了对invalid的drop规则,此时curl请求复现了6秒卡顿之后请求成功的情况,大概率这就是”丢包点”。
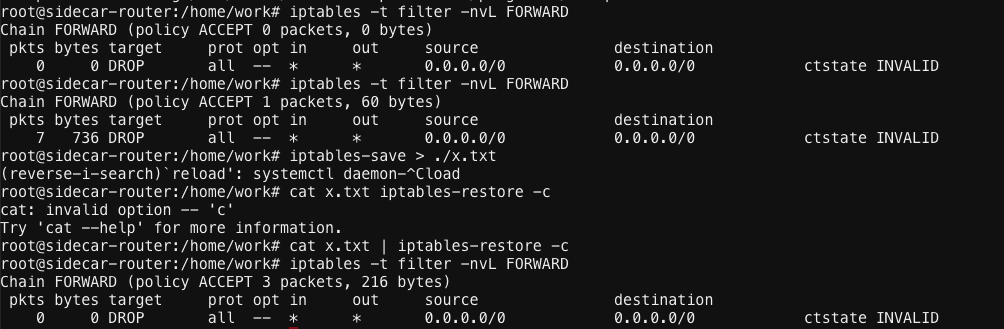
- 于是回头去K8S线上集群观察了一下drop规则的counter计数,结果发现是个0,不应该啊!
- 于是开始怀疑iptables是不是有重置计数器的逻辑,谷歌搜索到国外有人反馈iptables-save保存规则后,iptables-restore恢复规则时counter会重置为0的,于是怀疑是不是kube-proxy下发规则时也用的iptables-restore命令?
- 然后读了一下kube-proxy关于iptables规则下发的代码,发现kube-proxy是先根据集群service列表按照iptables-save的格式生成了一个规则文件,然后再调用iptables-restore生效新规则的。
- 于是在线下iptables-save,iptables-restore尝试走了一次生效流程,发现drop计数器真的被清0了,所以基本可以明确”丢包点”就是因为” conntrack半匹配+k8s的forward drop invalid规则一起导致的”
K8S下发的invalid drop规则:

中间商node的半匹配持续6秒:

iptables-restore重置计数器的问题验证:
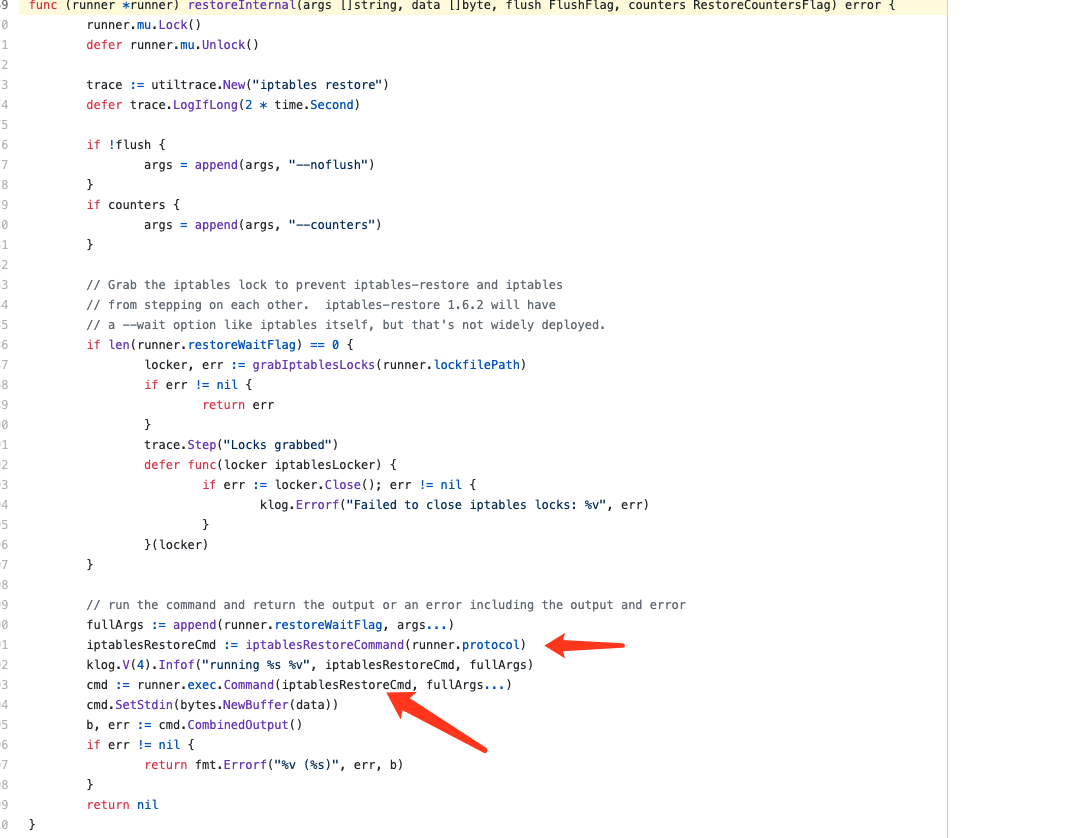
kube-proxy下发规则时的源码:
https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/iptables/proxier.go#L775
https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/iptables/proxier.go#L1543

阶段5
- 因为k8s的drop规则是合理的(k8s团队为了解决历史上其他的bad case),所以问题的根源又回到了解决arp cache错误的问题。
- 我们在问题node上抓对问题pod的arp刷新请求,结果始终抓不到arp刷新请求,这让我们匪夷所思。
- 不过在之前的阶段,就已经通过清理arp cache,验证了问题不是出在sdn层面,因此还是关注node自身的arp缓存刷新逻辑是啥。
- 经过搜索进一步了解到linux为了性能考虑将arp缓存策略做的极度复杂(https://vcpu.me/linuxarp/),其中有一个重要行为就是如果收到来自mac地址的网络通讯包,那么arp似乎就会认为这个mac地址”健在”,进而会继续延后对ip的arp刷新请求,因此就会一直持有一个错误的ip →mac对应关系。
- 我们遇到的问题就是,因为pod ip复用了,而这个ip曾经出现在旧Node上,现在又出现在了新node上,导致其他node的arp cache缓存着旧node的mac地址,因此就出现了”中间商node”。
- 目前解决方案是部署daemonset到所有node上,监听新建/删除POD事件并捕获到POD的IP地址,在每个node的network namespace中执行arp -d $ip清理对应mac缓存,代码开源在这里:https://github.com/owenliang/kubernetes-arp-cleaner,代码还没有详细优化,发布应用期间响应时间会略有颠簸,有时间会再再优化一下清理逻辑。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

优秀~
1
1
1
1