nscd-dns缓存的实现原理与关键参数
在K8S集群中,出于对域名解析稳定性和性能的考虑,我们在POD内启动了nscd对解析结果进行缓存。
一直以来nscd表现都正常,但是这两天每次滚动发布应用,新POD偶然会遇到大量的DNS解析失败的告警,每次持续时间都是1分钟,规律明显,这是为什么呢?
nscd实现原理
大部分程序都是基于glibc的gethostbyname或者getaddrinfo来进行域名解析的,而glibc代码实际支持了nscd本地缓存的逻辑,我们只需要启动nscd服务即可。
原本gethostbyname直接发送请求给DNS服务器,则现在其实现将会把请求发给nscd进程,由nscd进程代理请求DNS服务器。
其程序架构如下:
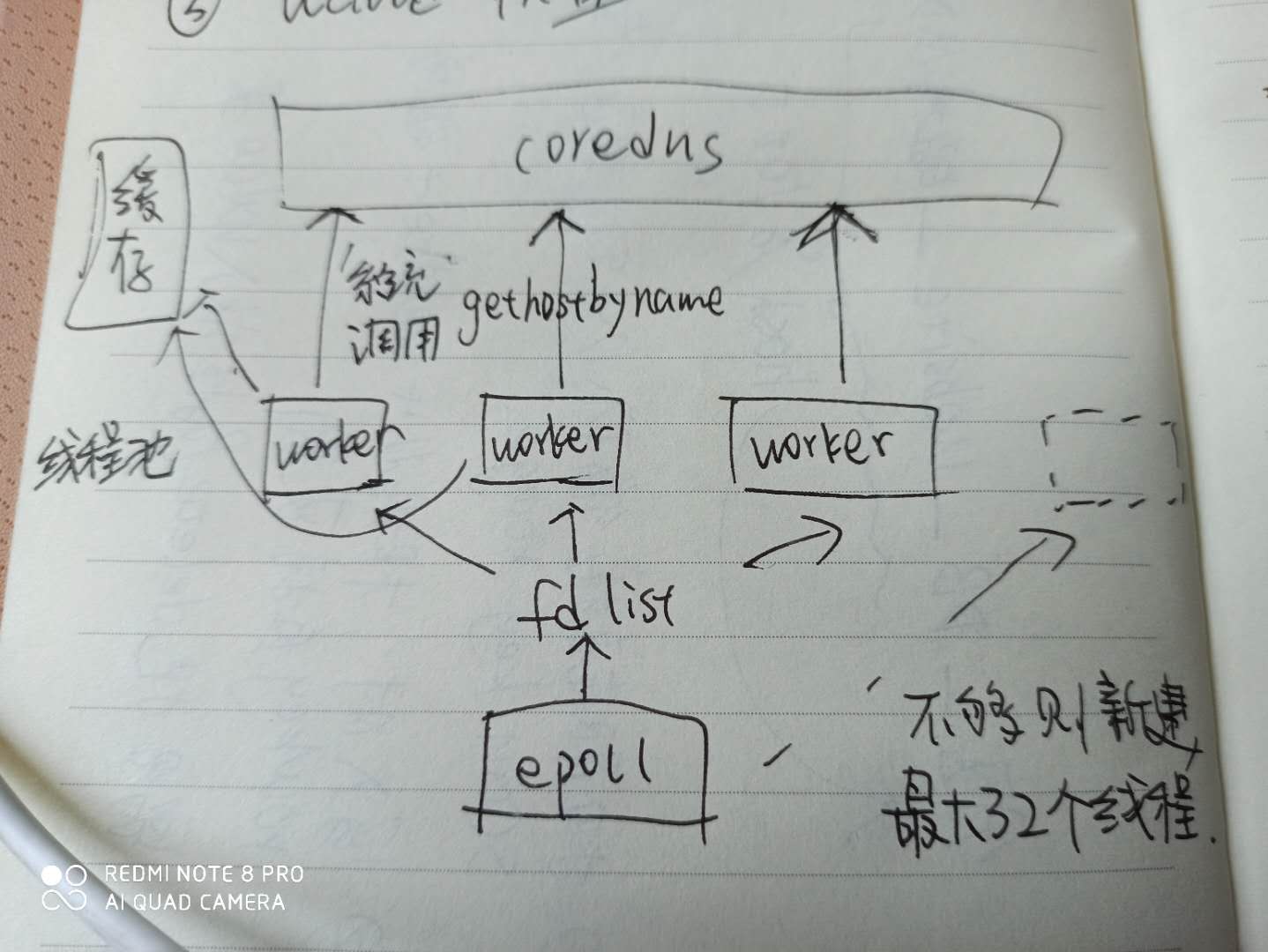
我大致看了一下,它内部有一个epoll线程监听UDP fd,当发生可读event时,会通过队列唤醒某个worker来读取一个udp请求,并且阻塞调用原gethostbyname方法完成DNS服务请求,这时候它的行为仍旧遵循/etc/resolv.conf中的配置,比如超时时间、重试次数。
如果worker因为解析慢而阻塞,则epoll线程会新建更多worker线程,最大不超过配置项max-threads个线程,而且这些线程一旦扩建则没有退出逻辑,会始终保持(初始化线程个数是threads配置项)。
回到超时问题
针对每次持续1分钟的解析超时现象,联想到nscd使用了一个关键配置项:
negative-time-to-live hosts 60
我们在配置时可能是把它理解为当DNS服务器返回NXDOMAIN(没有IP地址)的情况下的缓存时间,因此刻意设置了一个比较长的时间。
然而此刻,我开始怀疑这个配置项的真实含义是当DNS服务器超时没有响应的时候,nscd会缓存一个失败的结果,导致接下来1分钟所有解析该domain的请求都被nscd立即返回失败。
为了验证这个参数的逻辑,我继续看了一下nscd相关的代码:
- https://github.com/lattera/glibc/blob/895ef79e04a953cac1493863bcae29ad85657ee1/nscd/hstcache.c#L478https://github.com/lattera/glibc/blob/895ef79e04a953cac1493863bcae29ad85657ee1/nscd/hstcache.c#L113
- https://github.com/lattera/glibc/blob/895ef79e04a953cac1493863bcae29ad85657ee1/nscd/hstcache.c#L113
结论就是:当解析超时没有得到结果时,nscd将依据negative-time-to-live参数缓存一段时间,导致后续一段时间的请求都直接被nscd返回失败应答,导致程序没有机会重新去尝试向远端的DNS服务器解析。
关键代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
time_t timeout = MAX_TIMEOUT_VALUE; if (hst == NULL) { if (he != NULL && errval == EAGAIN) { /* If we have an old record available but cannot find one now because the service is not available we keep the old record and make sure it does not get removed. */ if (reload_count != UINT_MAX) /* Do not reset the value if we never not reload the record. */ dh->nreloads = reload_count - 1; /* Reload with the same time-to-live value. */ timeout = dh->timeout = t + dh->ttl; } else { /* We have no data. This means we send the standard reply for this case. Possibly this is only temporary. */ ... .. timeout = datahead_init_neg (&dataset->head, (sizeof (struct dataset) + req->key_len), total, (ttl == INT32_MAX ? db->negtimeout : ttl)); ... ... (void) cache_add (req->type, &dataset->strdata, req->key_len, &dataset->head, true, db, owner, he == NULL); |
大概意思就是:
如果本次没解析到结果(hst),那么如果之前缓存的记录存在(he),那么还是给记录刷新TTL,用一个旧结果总比没有结果强吧!
如果之前没有缓存的记录,那么就将这次失败缓存negtive-time-to-live秒。
结论
当dns解析失败时,对失败结果做缓存也不是毫无道理,这是避免dns雪崩的一种手段,但是可能这个配置并不适合大多数人,我们希望的还是失败后下一次解析可以重新执行,而不是继续得到一个nscd缓存的失败结果。
解决方法就是将该配置修改为0即可。
但是为什么DNS服务端解析会超时,这个问题才是根因,还需进一步观察。
相关链接:https://zhuanlan.zhihu.com/p/44556919
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
1