azkaban入门
azkaban是当下最主流的ETL任务调度工具,容易理解与使用,轻松分布式扩展处理能力。
下面做一个入门介绍,记录我的发现和理解。
编译
azkaban支持2种模式:
- Solo Server:单机版本,适合做学习调研用。
- Multi Executor Server:生产版本,分布式架构,由1个web与n个executor实现横向扩展,基于mysql存储。
官方安装文档:https://azkaban.readthedocs.io/en/latest/getStarted.html#getting-started。
下面将安装单机版,要求linux/mac环境,java8+版本(建议就用Java8,太高版本是不行的):
|
1 2 3 |
git clone https://github.com/azkaban/azkaban.git cd azkaban ./gradlew build installDist |
因为GFW原因,上述过程会反复超时,最终是可以成功的,保持耐心。
配置
Solo Server版本被编译到了路径:azkaban-solo-server/build/install/azkaban-solo-server。
进入该目录,bin下是启停脚本,conf下是配置。
文件conf/azkaban.properties是核心配置,不考虑性能优化的话只需要改一下时区,这样azkaban界面上时间会显示为本地时间:
|
1 |
default.timezone.id=Asia/Shanghai |
同时观察到azkaban的默认用户管理实现类是azkaban.user.XmlUserManager类,它会加载conf/azkaban-users.xml来加载用户集合:
|
1 2 3 |
# Azkaban UserManager class user.manager.class=azkaban.user.XmlUserManager user.manager.xml.file=conf/azkaban-users.xml |
azkaban-users.xml文件的内容默认如下:
|
1 2 3 4 5 6 7 |
<azkaban-users> <user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/> <user password="metrics" roles="metrics" username="metrics"/> <role name="admin" permissions="ADMIN"/> <role name="metrics" permissions="METRICS"/> </azkaban-users> |
azkaban设定了user,gruop,role,permission几个内置概念,user关联到role or group,gruop关联到role,role关联到permission,permission内置了几种。
azkaban.user.XmlUserManager只是基于XML配置的一种实现,我们可以自己实现一个UserManager类,实现用户认证,角色权限获取等接口即可对接到公司的现有账号体系。
在此我们不做任何修改,只是了解上述概念,同时我们将使用azkaban,azkaban这个管理员账号登录到系统。
启动
执行命令启动solo server:
|
1 |
bin/start-solo.sh |
打开浏览器访问http://127.0.0.1:8081/,登录账号密码:azkaban,azkaban。
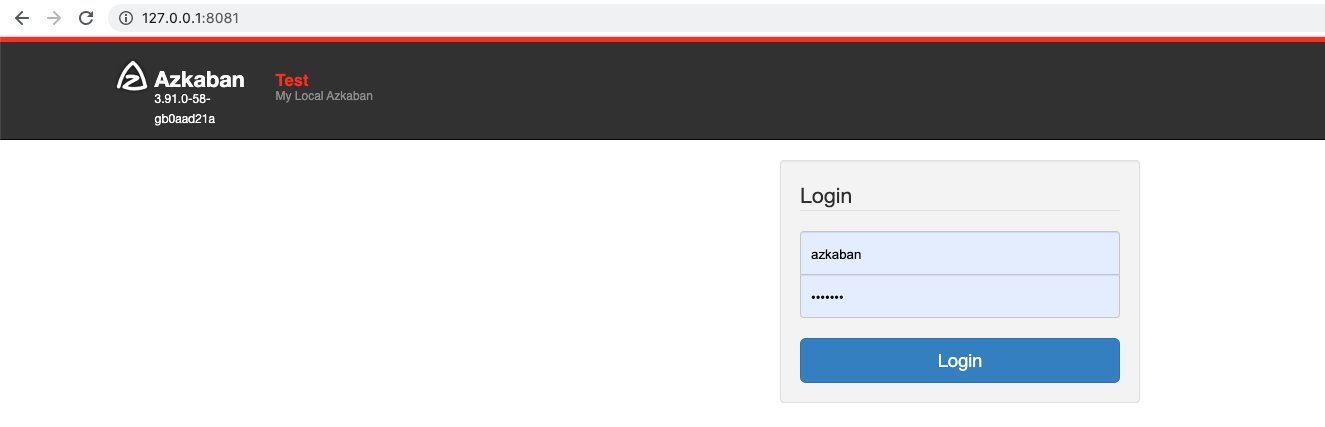
新建项目
project可以用来表示一个业务场景,比如:交易。
交易业务下又会写很多flow,每个flow由若干互相依赖的JOB先后执行构成,不同flow完成不同的ETL任务目标。
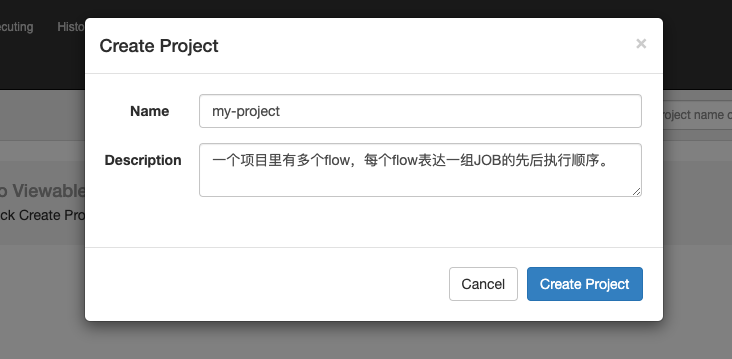
了解权限
项目里点击permissions,可以给user或者group赋予该项目的某些permission:
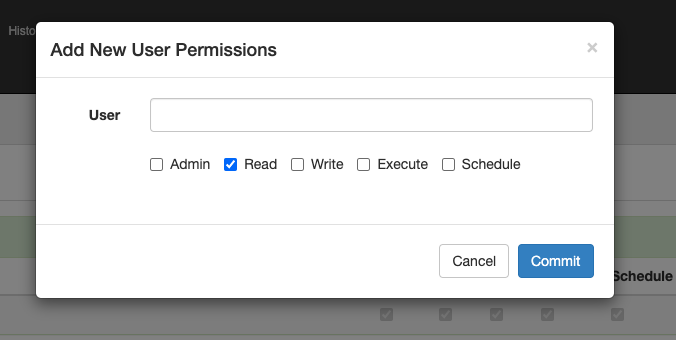
Admin就是管理员,其他4个分别代表某个具体操作的权限。
因为我们使用了XmlUserManager实现,所以user和group必须是xml文件中配置过的,否则会报不存在。当然,如果我们使用自定义的UserManager实现,那么就会通过我们的实现来查询用户是否存在了。
proxy users有点晦涩,暂时没有研究出来。
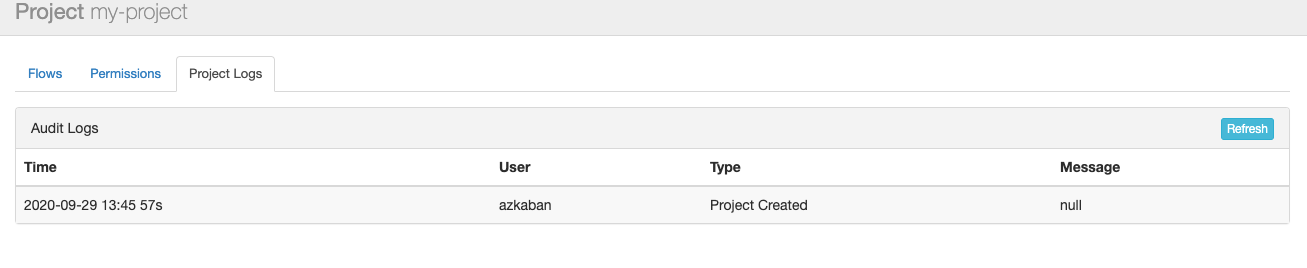
项目日志
项目内的修改操作都有日志记录:
开发project
1个flow编排一组相互依赖的JOB,作为一个DAG图调度执行;1个project包含多个flow,这些flow分别独立调度与执行,做不同的事情。
新Project下面当前没有flow,我们需要本地开发好project,然后上传压缩包到azkaban即可。
现在,我们创建1个proj1空目录,在里面放一个flow20.project声明文件(后缀重要,名字不重要):
|
1 |
azkaban-flow-version: 2.0 |
这个文件声明这个Project是使用azkaban 2.0版本的flow语法进行描述的。
|
1 2 3 |
smzdm@smzdmdeMacBook-Pro proj1 % ls -l total 24 -rw-r--r-- 1 smzdm staff 25 9 28 16:42 flow20.project |
开发first.flow
第一个flow很简单,它只有1个JOB,打印hello退出。
.flow文件可以放在proj1之下的任意层级,都会被azkaban扫描到。
我们新建1个first.flow,放在proj1下:
|
1 2 3 4 |
(base) smzdm@smzdmdeMacBook-Pro proj1 % ls -l total 24 -rw-r--r-- 1 smzdm staff 71 9 29 14:02 first.flow -rw-r--r-- 1 smzdm staff 25 9 28 16:42 flow20.project |
内容如下:
|
1 2 3 4 5 |
nodes: - name: job-a type: command config: command: echo hello |
nodes下面是JOB数组,当前只配置了1个job-a,其类型是command执行命令,具体命令放在config.command下面,也就是echo hello。
flow真正的优势是编排多个JOB之间的依赖与并发执行关系,在下一个例子将涉及到。
提交first.flow
我们把first.flow和flow20.project打包到.zip文件里,注意不要包含proj1目录层级,而是直接把2个文件打进去。
|
1 2 3 4 5 |
(base) smzdm@smzdmdeMacBook-Pro proj1 % ls -l total 32 -rw-r--r-- 1 smzdm staff 71 9 29 14:02 first.flow -rw-r--r-- 1 smzdm staff 25 9 28 16:42 flow20.project -rw-r--r--@ 1 smzdm staff 472 9 29 14:07 归档.zip |
把.zip上传到azkaban:
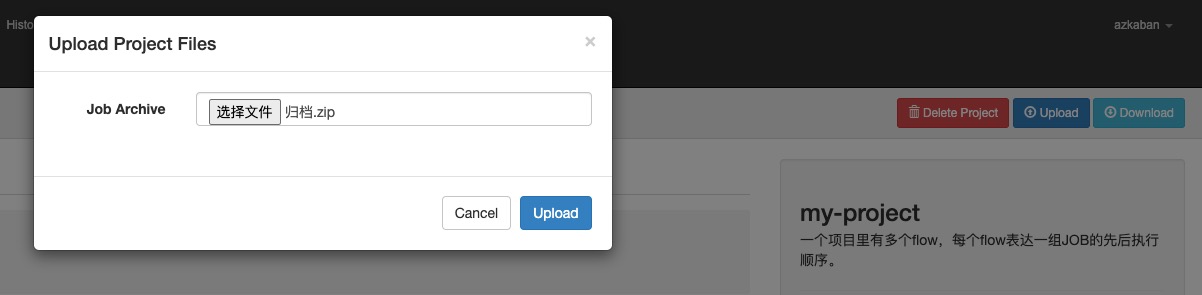
azkaban识别到first.flow,里面有job-a:
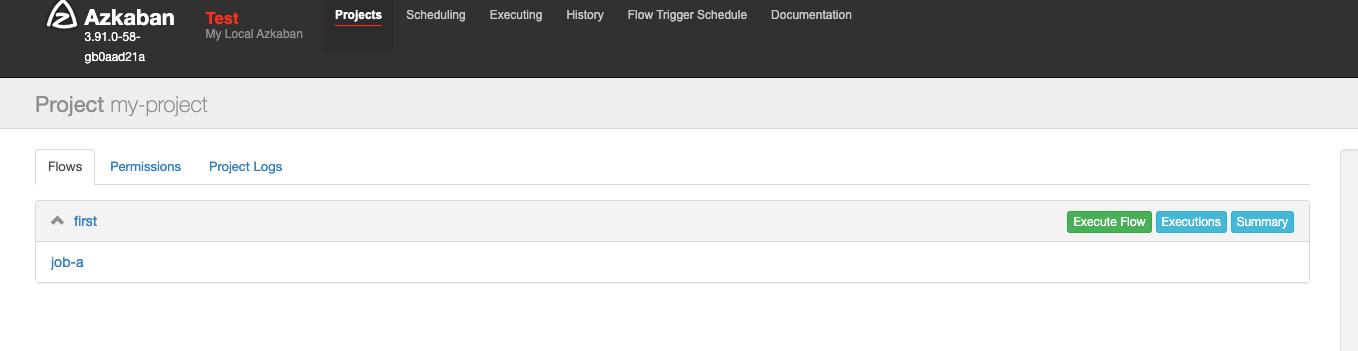
execute flow可以进一步配置如何执行flow,executions则是历史执行记录,summary是一些汇总信息。
flow执行配置
点击execute flow按钮,将弹出执行配置的界面。
flow的执行分为2种方式,一种就是手动立即触发1次,另外一种是cron定时执行。
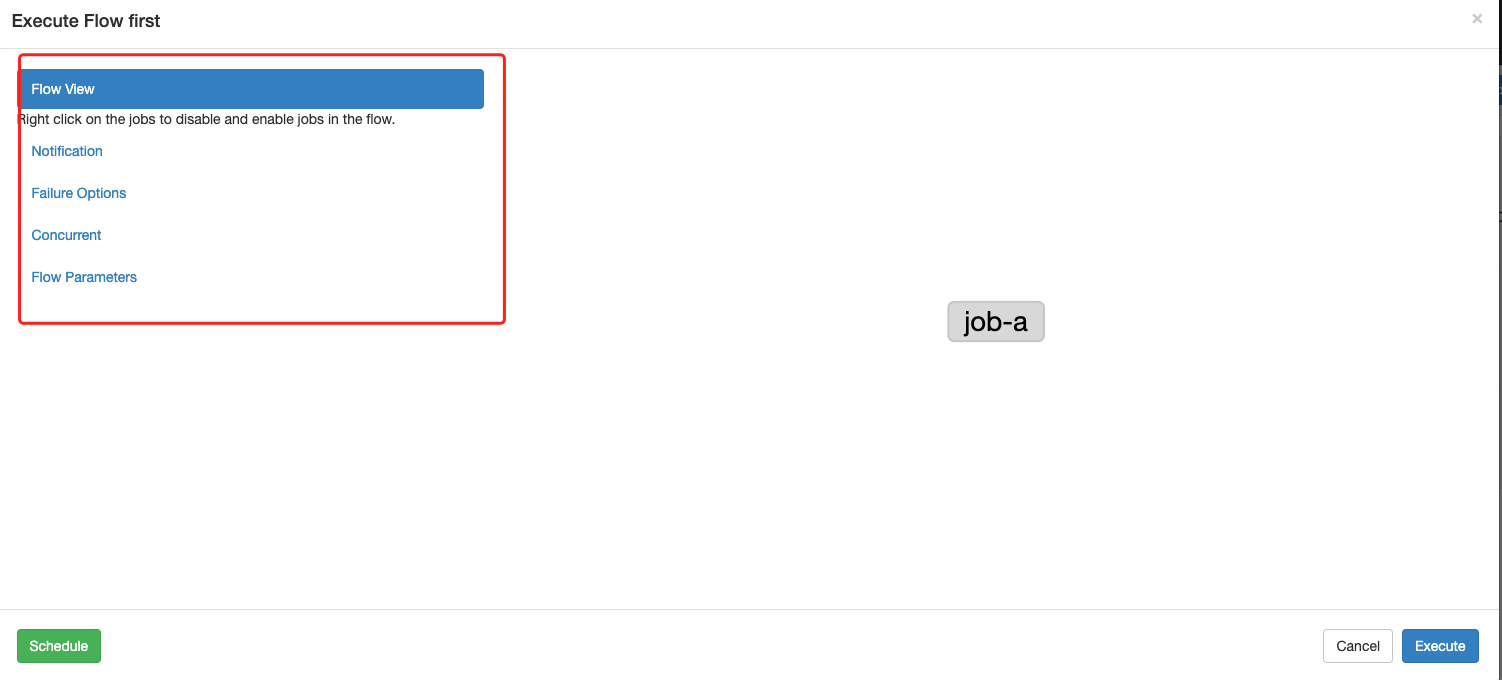
弹窗右下角就是立即执行一次,左下角是cron调度的进一步配置界面。
左侧红框的各个配置项需要我们逐一配置,最后点击左下角或者右下角的按钮来生效到本次或者定时调度中去。
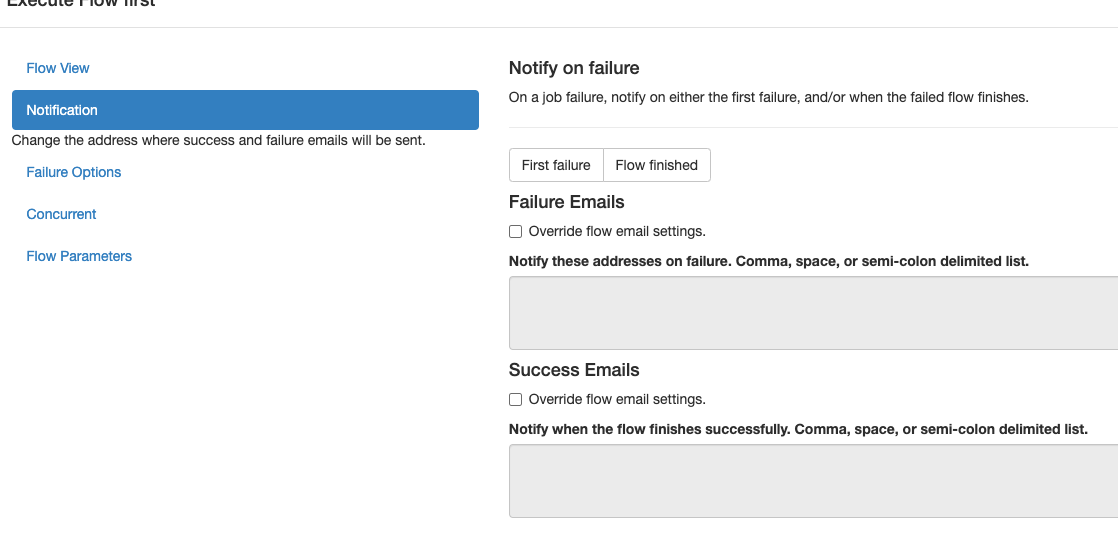
flow执行成功失败可以邮件通知。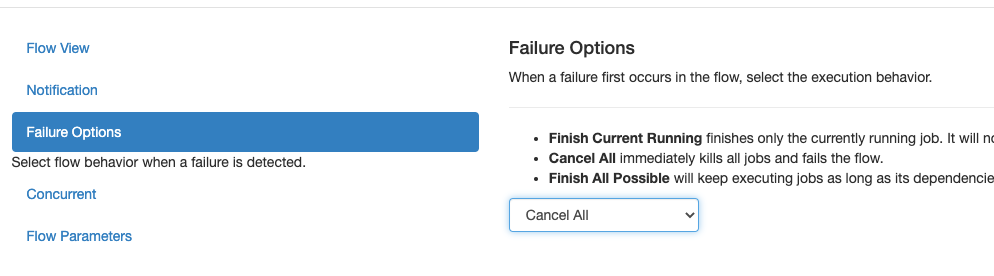
当flow里某个job失败后,可以选择flow的处理策略,比如:跑完正在跑的,取消掉正在跑的,或者把剩余能跑的全跑完。这里选择了cancel all就是说一旦某个JOB失败了那么整个flow的其他JOB全部停掉,整个flow尽快失败。
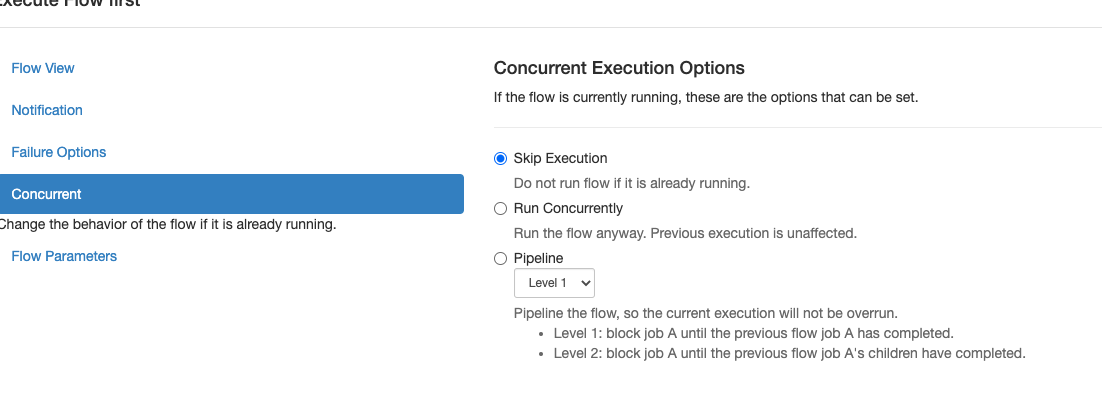
当flow前一次execution还没完成时,下一次cron到期了,此时的并发策略需要选择。
一般来说我们会选择放弃本次执行,因为大部分ETL任务都是依赖前一轮ETL数据输出的。
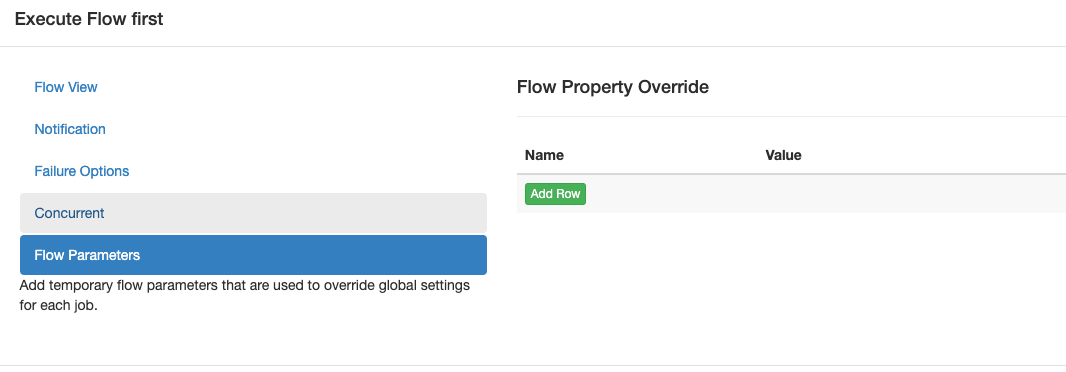
.flow支持动态参数,通过UI界面传入的参数优先级最高,会覆盖写死在.flow中的配置,稍后会做演示。
立即执行
配置好上述内容后,点击右下角的execute按钮触发一次性执行。
注意,下次打开上述弹窗的配置都将重置,需要重新填写,这个UI交互逻辑需要大家理解。
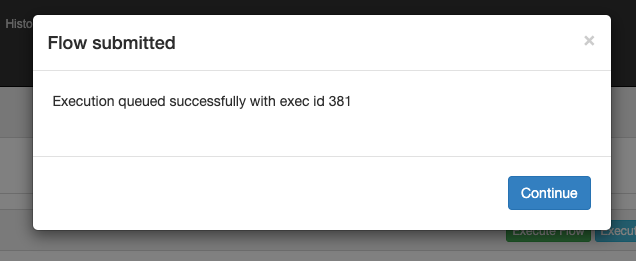
这次的execution id是381,代表flow的1次执行历史。
查看execution
点击flow旁边的executions可以进入到执行历史界面:
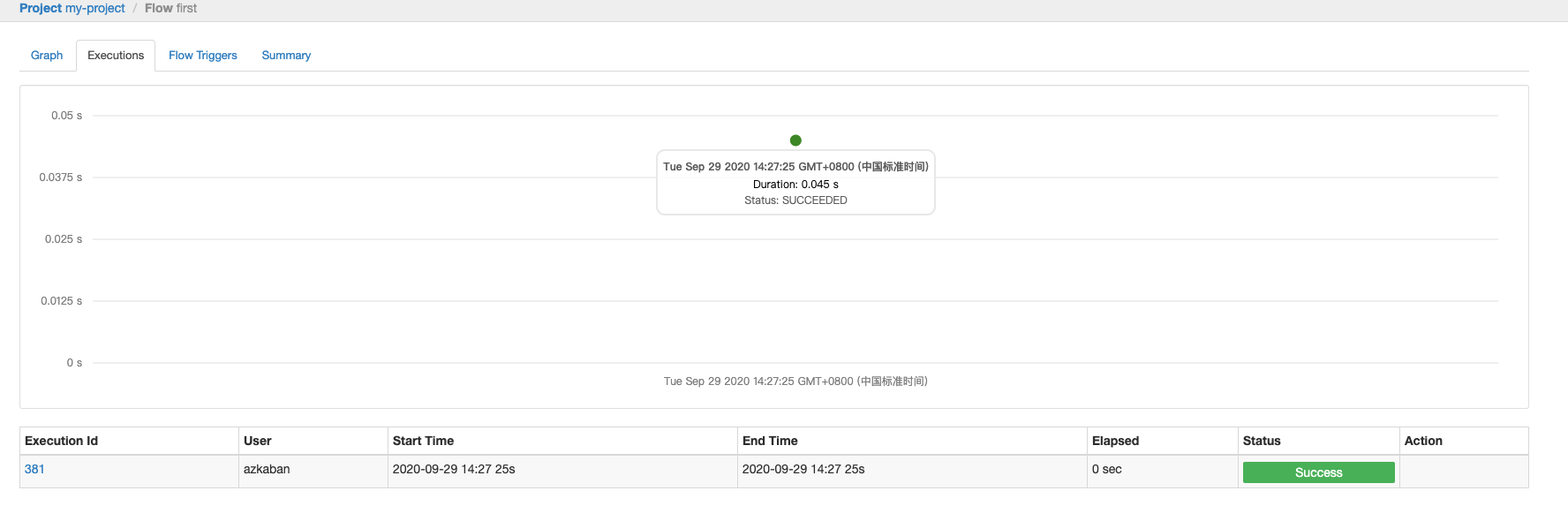
可以看到first.flow的所有历史执行记录以及耗时曲线,点击某个execution可以进去看每个JOB的执行耗时、日志等。
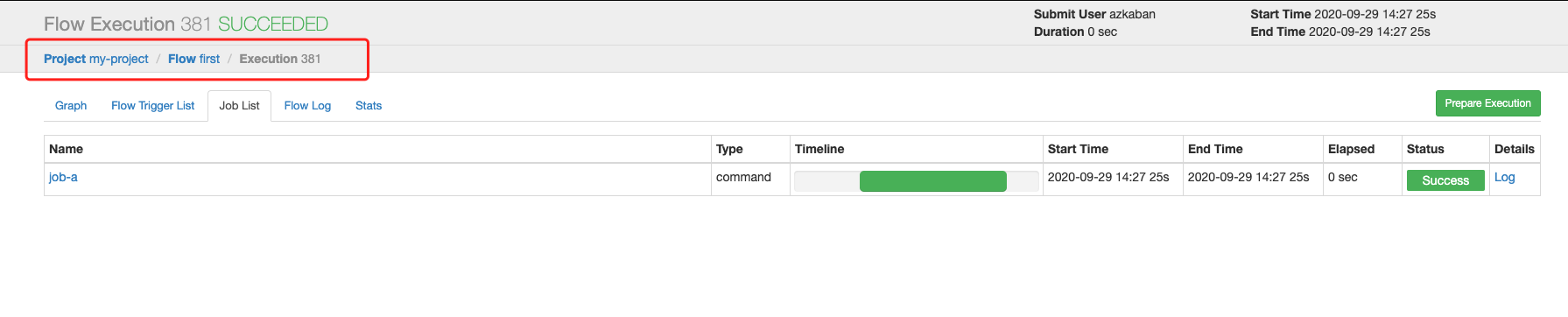
注意看左上角的面包屑,很容易理解UI的交互逻辑:project -> flow -> execution,本次execution的job-a耗时、状态、日志都可以看到。
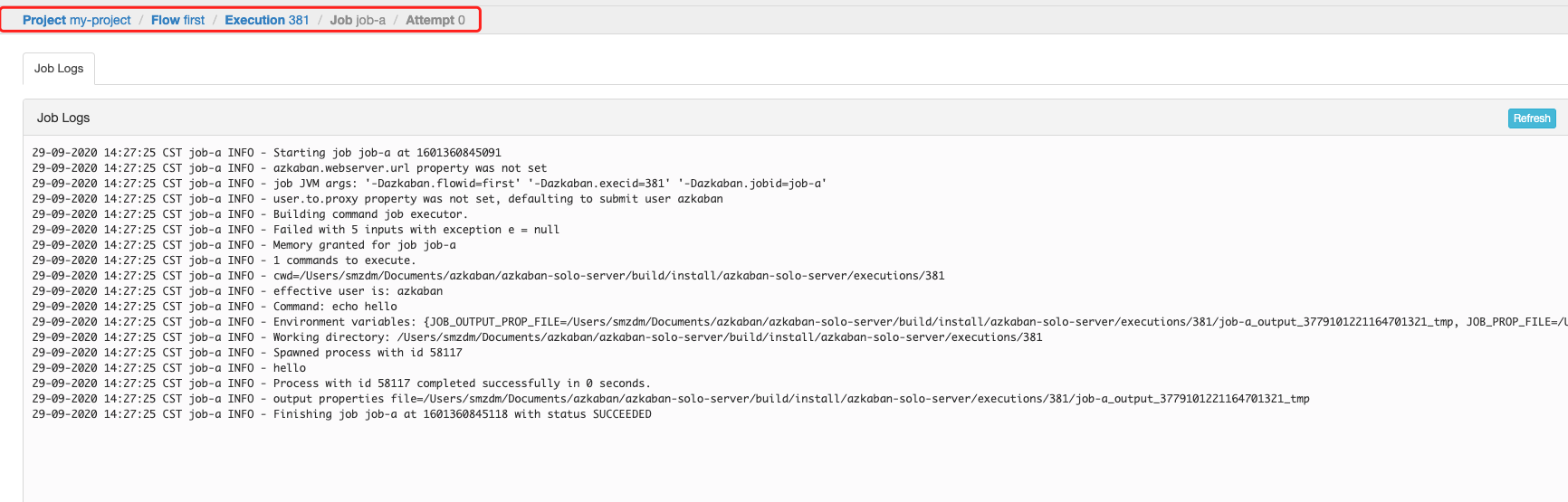
点击Log查看具体Job运行过程中的输出,发现的确echo了hello:
开发second.flow
现在做一个带JOB依赖的flow,新建second.flow:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
config: retries: 3 retry.backoff: 30000 nodes: - name: job-a type: command config: xx: hello command: ${azkaban.shell} ./scripts/a.sh ${run_date} ${xx} - name: job-b type: command config: command: ${azkaban.shell} ./scripts/b.sh ${run_date} dependsOn: - job-a |
nodes数组包含了job-a和job-b,其中job-b依赖job-a的成功。
config是flow级的配置,retries和retry.backoff会被所有job的config继承,其效果就是影响每个job的重试次数和间隔。在job内的config也可以配置标准的或者自定义的参数。
简单总结就是上级的参数会被下级继承,想访问这些参数通过${名字}就可以拿到值,例如:xx只能被job-a的command使用,因为它被定义在job里面。
还有2个没有在flow或者job中定义过的参数,例如azkaban.shell,run_date,它们的来源是哪里呢?我们先不管scripts/a.sh和b.sh是什么,继续来解释参数的几个来源。
(注意:${}是azkaban解释执行的,全部替换后才会执行command,千万不要误以为${}是shell解释执行的!)
global参数
azkaban有一个配置文件可以配置全局参数,它会被所有project的所有flow的所有job共享:
|
1 2 |
azkaban-solo-server % cat conf/global.properties azkaban.shell=/bin/bash |
作为管理员,我会定义上述azkaban.shell的一个参数,告诉所有用户应该使用哪个bash程序。
UI参数
在UI上配置flow执行时,同样可以传参,而且其优先级高于一切,会覆盖.flow写死的值:
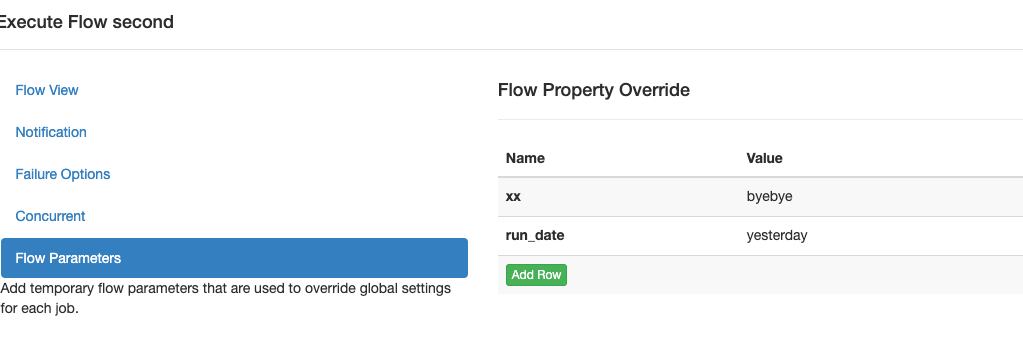
像上图一样的参数值会被带入到command中的${run_date}和${xx},这只是示例,目前我们还没有把新的project zip上传,让我们继续完成scripts。
编写scripts
command中执行了scripts下面的bash脚本,azkaban的工作目录总是zip包的根目录,因此相对路径总是相对于zip包根目录的。
整个project目录结构如下:
|
1 2 3 4 5 6 |
(base) smzdm@smzdmdeMacBook-Pro proj1 % ls -l total 32 -rw-r--r-- 1 smzdm staff 71 9 29 14:02 first.flow -rw-r--r-- 1 smzdm staff 25 9 28 16:42 flow20.project drwxr-xr-x 4 smzdm staff 128 9 28 16:47 scripts -rw-r--r--@ 1 smzdm staff 288 9 29 14:02 second.flow |
a.sh脚本:
|
1 2 3 4 5 6 7 8 9 |
#!/bin/bash run_date=$1 xx=${2} if [ "${run_date}" = "yesterday" ];then run_date=`date -d "-1 day" +%Y-%m-%d` fi echo "a.sh ${run_date} ${xx}" |
b.sh脚本:
|
1 2 3 4 5 6 7 8 |
#!/bin/bash run_date=$1 if [ "${run_date}" = "yesterday" ];then run_date=`date -d "-1 day" +%Y-%m-%d` fi echo "b.sh ${run_date}" |
如果run_date传的是yesterday,那么自动计算前一天的日期,否则直接使用传入的日期。
一般ETL都是T+1执行,因此正常情况下凌晨被调度拉起都是为了获取前一天的数据。
如果希望补跑某天的数据,则可以通过UI界面临时执行run_date为具体日期。
把整个目录下所有文件打包重新upload上传,会看到project有2个flow:
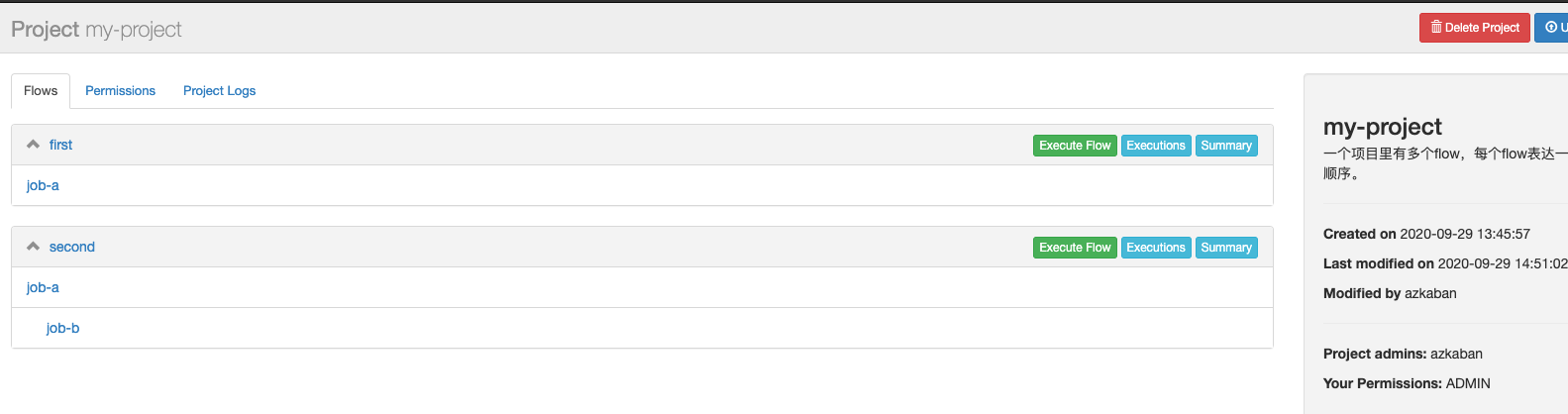
定期执行second.flow
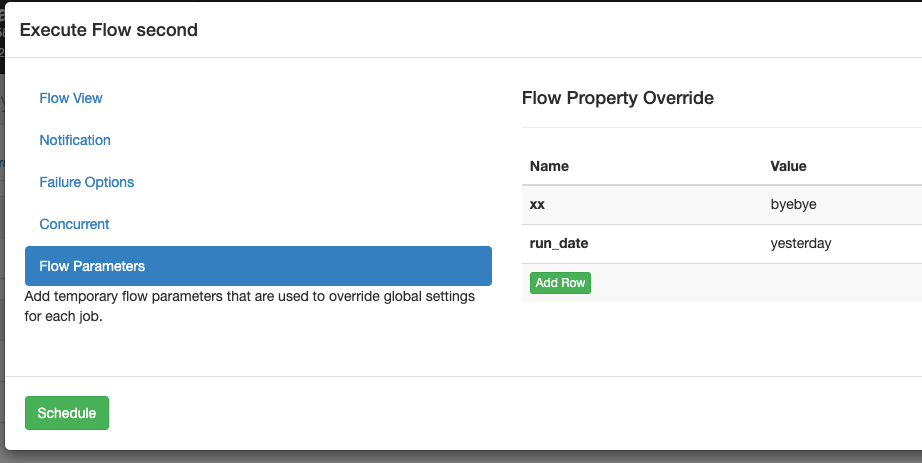
点击second.flow旁边的execute flow,配置参数:run_date为yesterday,xx为byebyte,然后点击左下角的schedule配置定时执行:
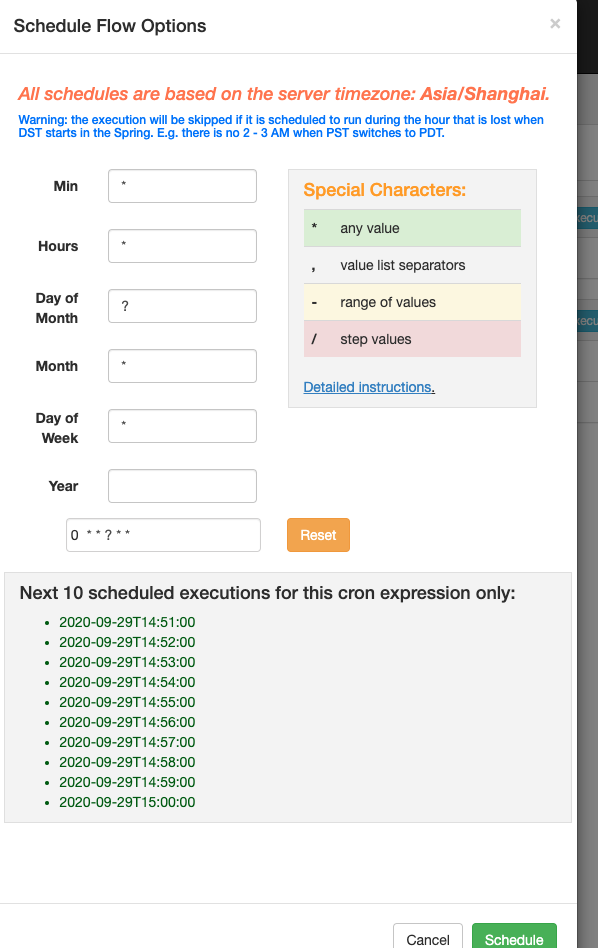
配置一下cron表达式,下方会显示接下来的10个执行时间点,确认正确后点击schedule即可创建定时任务:
定时任务在一个独立的菜单里,会反向关联到project+flow,这个UI交互不是很直观:

点击flow跳进去可以看到历史execution,之前已经介绍过了。

可以看到job-a和job-b顺序执行,全部都是成功的。
如果有个别job失败,我们可以点击prepare execution来重跑失败的JOB让整个flow恢复正常,当然也要注意flow参数是否还合适(比如已经过去好几天了,那么需要手动写一下补跑的run_date):
PS:这里没有失败任务,所有都被置灰了。
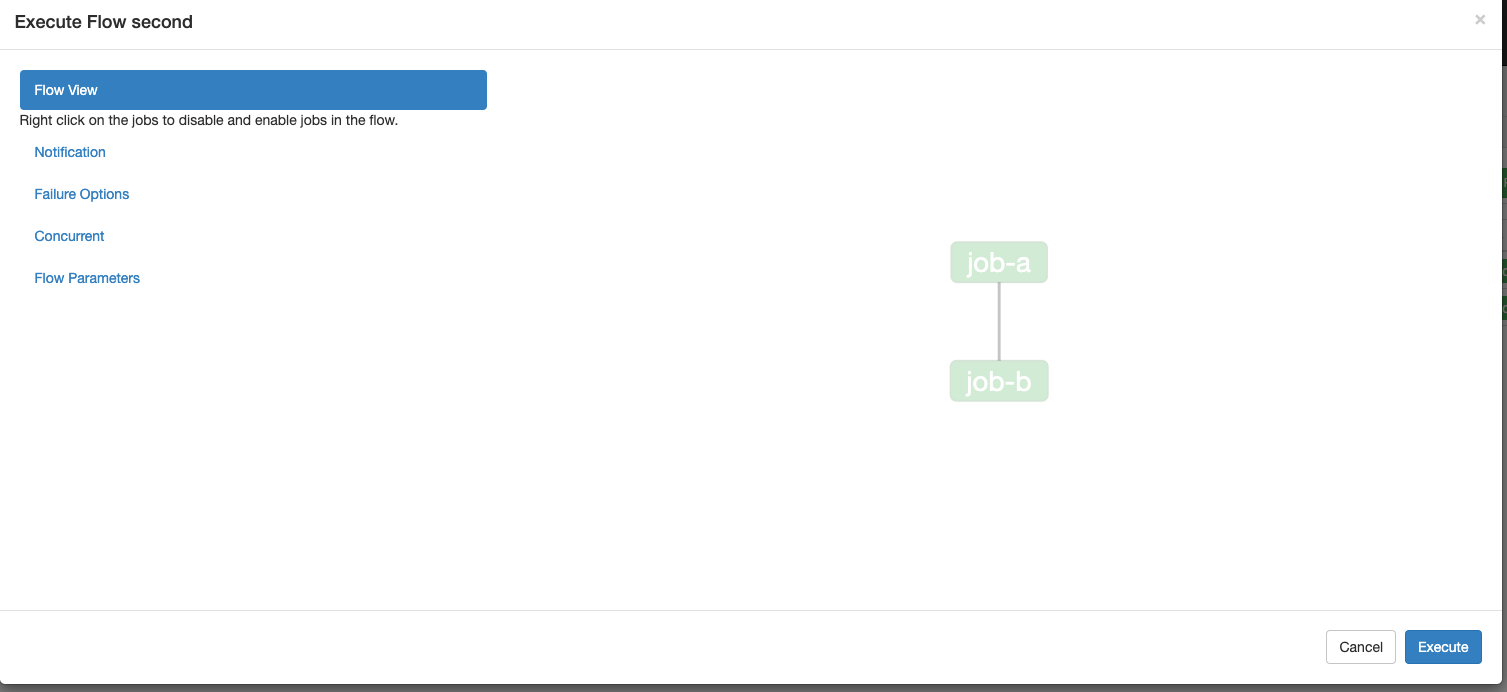
也可以查看job-a的log,观察到参数是来自于高优先级的UI参数:
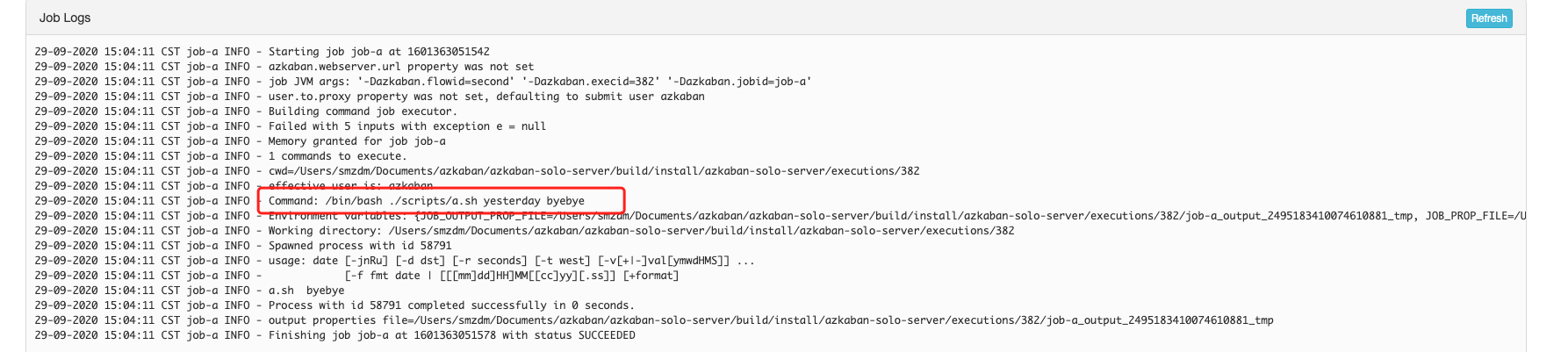
azkaban入门就到这里。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
1