hadoop伪分布式环境搭建
近期学习大数据技术,将通过博客分享它们原理与使用。
本文搭建hadoop3.x伪分布式集群,即在1台服务器上完成hdfs与yarn的搭建,完全根据官方手册进行:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html。
安装jdk1.8
进入Oracle官网JDK1.8主页:https://www.oracle.com/cn/java/technologies/javase/javase-jdk8-downloads.html,下载Linux x64 Compressed Archive压缩包。
将解压后的目录mv到/usr/local/jdk即可(也可以放到其他路径):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
root@ubuntu:~/bigdata# ll /usr/local/jdk/ total 25668 drwxr-xr-x 2 10143 10143 4096 Jun 18 06:55 bin/ -r--r--r-- 1 10143 10143 3244 Jun 18 06:55 COPYRIGHT drwxr-xr-x 3 10143 10143 4096 Jun 18 06:55 include/ -rw-r--r-- 1 10143 10143 5219010 Jun 18 04:03 javafx-src.zip -rw-r--r-- 1 10143 10143 195 Jun 18 06:55 jmc.txt drwxr-xr-x 6 10143 10143 4096 Jun 18 06:55 jre/ drwxr-xr-x 4 10143 10143 4096 Jun 18 06:55 legal/ drwxr-xr-x 4 10143 10143 4096 Jun 18 06:55 lib/ -r--r--r-- 1 10143 10143 44 Jun 18 06:55 LICENSE drwxr-xr-x 4 10143 10143 4096 Jun 18 06:55 man/ -r--r--r-- 1 10143 10143 159 Jun 18 06:55 README.html -rw-r--r-- 1 10143 10143 424 Jun 18 06:55 release -rw-r--r-- 1 10143 10143 21005583 Jun 18 06:55 src.zip -rw-r--r-- 1 10143 10143 190 Jun 18 04:03 THIRDPARTYLICENSEREADME-JAVAFX.txt -r--r--r-- 1 10143 10143 190 Jun 18 06:55 THIRDPARTYLICENSEREADME.txt |
在合适位置将上述bin目录加入PATH环境变量:
|
1 2 |
root@ubuntu:~/bigdata# cat /etc/profile.d/java.sh export PATH=/usr/local/jdk/bin:${PATH} |
重新登录shell,确认java可用:
|
1 2 3 4 |
root@ubuntu:~# java -version java version "1.8.0_261" Java(TM) SE Runtime Environment (build 1.8.0_261-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode) |
下载hadoop
选择任意下载源:http://www.apache.org/dyn/closer.cgi/hadoop/common/,下载hadoop-3.3.0.tar.gz即可。
准备目录/root/bigdata,解压hadoop-3.3.0.tar.gz到该目录下:
/root/bigdata/hadoop-3.3.0
编辑/root/bigdata/hadoop-3.3.0/etc/hadoop/hadoop-env.sh,增加JAVA_HOME环境变量:
export JAVA_HOME=/usr/local/jdk
各种hadoop的命令都会先加载该env脚本来初始化一些必要的环境变量。
现在把hadoop的bin也加入到PATH中,再次编辑/etc/profile.d/java.sh,增加如下PATH:
|
1 2 |
root@ubuntu:~/bigdata/hadoop-3.3.0# cat /etc/profile.d/java.sh export PATH=${PATH}:/usr/local/jdk/bin:/root/bigdata/hadoop-3.3.0/bin |
重新登录shell,现在可以直接访问hadoop、hdfs等命令了:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@ubuntu:~/bigdata/hadoop-3.3.0# hdfs version Hadoop 3.3.0 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af Compiled by brahma on 2020-07-06T18:44Z Compiled with protoc 3.7.1 From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4 This command was run using /root/bigdata/hadoop-3.3.0/share/hadoop/common/hadoop-common-3.3.0.jar root@ubuntu:~/bigdata/hadoop-3.3.0# hadoop version Hadoop 3.3.0 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af Compiled by brahma on 2020-07-06T18:44Z Compiled with protoc 3.7.1 From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4 This command was run using /root/bigdata/hadoop-3.3.0/share/hadoop/common/hadoop-common-3.3.0.jar |
配置hdfs
编辑etc/hadoop/core-site.xml:
|
1 2 3 4 5 6 7 8 9 10 |
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.2.119:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/root/bigdata/hadoop-3.3.0/tmp</value> </property> </configuration> |
关键配置就2项:
- fs.defaultFS:namenode监听地址,写网卡IP。
- hadoop.tmp.dir:数据存储根目录(同时影响namenode与datanode)
编辑etc/hadoop/hdfs-site.xml :
|
1 2 3 4 5 6 7 8 |
<configuration> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> </configuration> |
配置副本数量为1,也就是总共存储1份数据即可,没有备份。
配置hadoop启动用户
我选择使用root用户启动,但是hadoop不建议这样做,大家可以选择使用其他linux用户作为hadoop启动用户。
据我了解,哪个用户启动hadoop,那么哪个用户就是hadoop的管理员身份。
我们编辑etc/hadoop/hadoop-env.sh,增加几个环境变量即可:
|
1 2 3 4 |
export JAVA_HOME=/usr/local/jdk export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root |
令namenode、secondarynamenode、datanode均用root用户启动。
配置ssh信任
hadoop提供分布式部署脚本,需要通过ssh信任连接到其他机器启动hadoop组件。
现在是伪分布式模式,因此需要配置的就是自己信任自己,所以做如下操作即可:
|
1 2 3 |
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys |
格式化hdfs
新集群需要为namenode初始化元数据,执行如下命令即可:
|
1 |
hdfs namenode -format |
启动hdfs
|
1 |
sbin/start-dfs.sh |
检查进程是否全部启动成功:
|
1 2 3 4 5 |
root@ubuntu:~/bigdata/hadoop-3.3.0# jps 12673 DataNode 12958 SecondaryNameNode 10127 Jps 12431 NameNode |
应该包含namenode、secondaryNamenode,datanode三个进程,如果不全可以查看/root/bigdata/hadoop-3.3.0/logs目录查看错误原因,同时也注意到核心数据已经写入到了/root/bigdata/hadoop-3.3.0/tmp目录。
执行命令确认hdfs工作正常:
|
1 |
hdfs dfs -ls / |
hdfs默认基于登录的linux用户进行文件权限判定,除非我们配置独立的认证机制,这和linux文件系统基本一致。
同时hdfs web管理界面可以访问:http://192.168.2.119:9870/。
配置Yarn
hadoop yarn是一套资源与容器调度框架,mapreduce只是yarn上的一套应用,诸如spark、flink等则是可以运行到yarn上的其他应用。
我们现在要简单配置yarn,让mapreduce可以通过yarn得到调度执行。
编辑etc/hadoop/mapred-site.xml:
|
1 2 3 4 5 6 7 8 9 10 |
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration> |
该文件配置mapreduce将基于yarn框架调度,并配置mapreduce程序依赖的jar包路径。
编辑etc/hadoop/yarn-site.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> </configuration> |
前2个配置项是官方指定的必要选项,不仔细研究了。
第3个配置开启了yarn的nodemanager日志采集到HDFS存储:
以mapreducer应用为例,提交给yarn的任务会先拉起一个mapreduce的master容器,再由 master二次向resourceManager索要更多worker容器资源来启动mapper/reducer程序。当mapper/reducer运行退出后,本地日志也随着容器销毁了。
而yarn日志采集可以把这些容器日志收集到hdfs上存储,所以历史日志可以追溯。
启动yarn
执行命令:
|
1 |
sbin/start-yarn.sh |
将拉起resourceManager和nodeManager和,前者是yarn的master节点负责资源调度,后者是每个服务器上的worker节点负责具体程序(容器)执行。
|
1 2 3 4 5 6 7 |
root@ubuntu:~/bigdata/hadoop-3.3.0# jps 12673 DataNode 13432 NodeManager 12958 SecondaryNameNode 13214 ResourceManager 12431 NameNode 10319 Jps |
现在可以命令行查看yarn集群中的application列表:
|
1 |
yarn application -list |
也可以查看yarn的web控制台:http://192.168.2.119:8088/cluster。
启动MR的historyserver
mapreduce框架只是yarn上的一种应用,其会启动MR的master程序,master又会拉起mapper和reducer容器。
而yarn日志聚合只是把容器的日志保存到了HDFS上,它并不知道容器里跑的是mapper还是reducer,以及到底是哪个mapper和哪个reducer。
为了最终在web界面上可以查看具体某个mapper/reducer容器的日志,当然得通过部署一个针对MR框架的historyserver程序,它负责关联HDFS上的容器日志到mapper和reducer,最终在web界面上提供简单易用的日志查询交互。
启动它:
|
1 |
sbin/mr-jobhistory-daemon.sh start historyserver |
现在如果你执行MR任务,那么可以通过yarn界面上对应application的history按钮,跳入到该应用对应的historyserver界面,进行具体日志查看。该mr jobhistory server只服务于MR应用,后续spark也会运行自己的historyserver,届时spark application的history就会跳入spark的historyserver了。
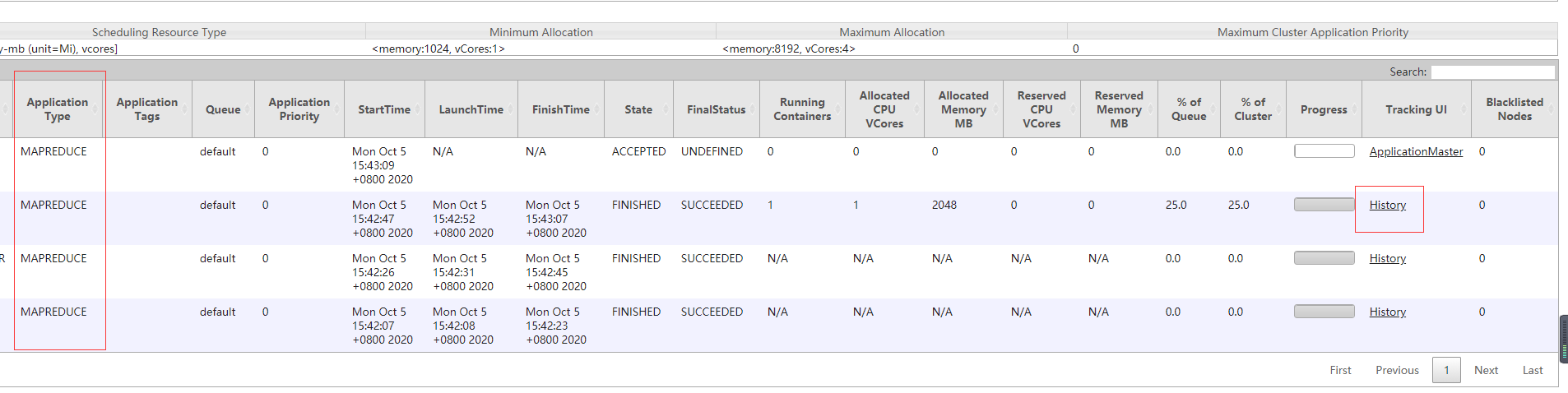
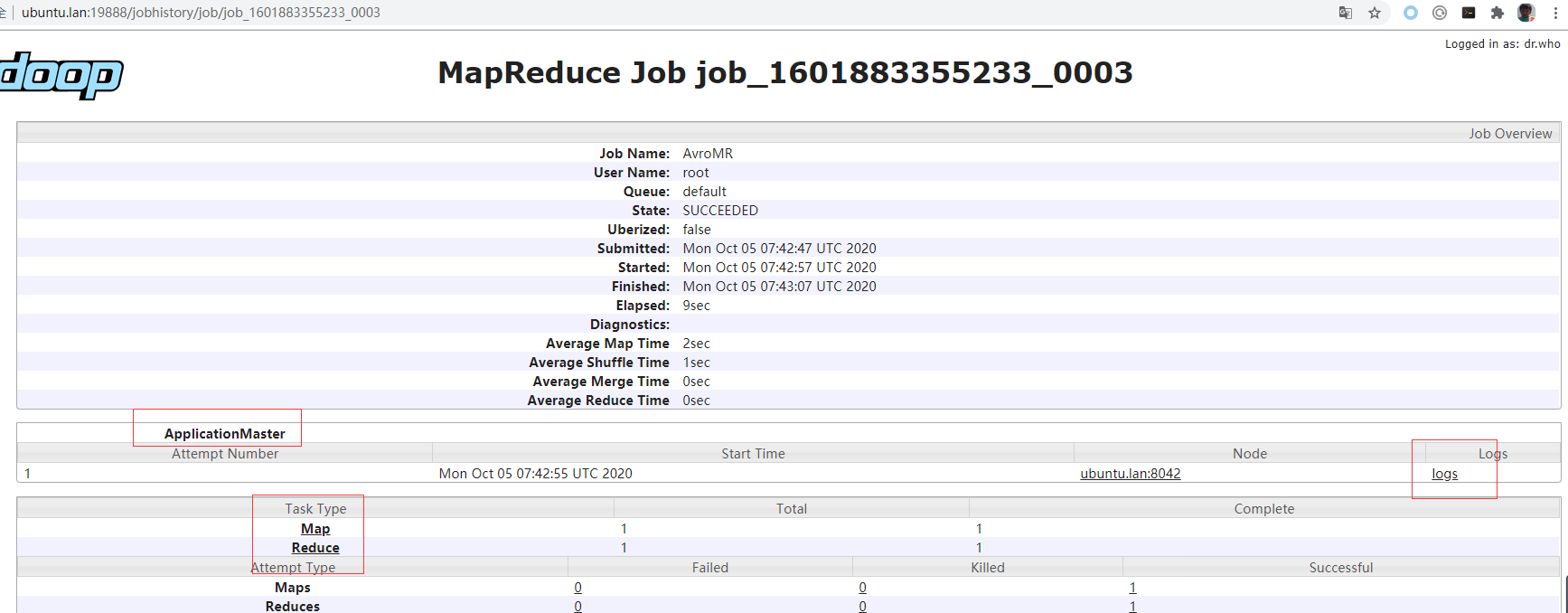
可以查看到mapreduce任务的app master日志,以及每个mapper和reducer的容器日志,就不具体展示了。
至此,hadoop伪分布式搭建完成,我们已经具备了一个可用的hdfs和yarn平台,后续可以玩一下mapreduce、spark、flink、flume等大数据组件。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

很不错 ~