spark系列 – spark on yarn搭建
mapreduce框架在开发需要多轮MR的任务时,因为shuffle过程和reducer输出需要写到磁盘上,所以执行效率很低。
spark框架通过将任务关系描述为DAG依赖图,经过spark的拆解可以让多个计算步骤尽量在一个进程内完成,避免数据经过网络或磁盘中转,效率得以提高。
基本原理
spark需要1个master负责任务分解和进度维护,多个executor从master拉取任务进行执行并回传结果给master。
而master和executor都可以跑到Yarn框架下,因此部署spark非常简单,编写与部署程序也非常简单。
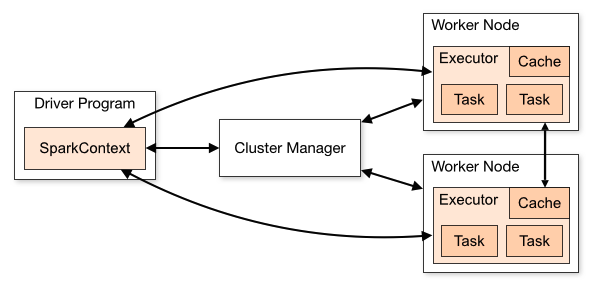
Driver是我们编写的计算程序,它定义与实现了整个计算任务的DAG图,把它打包Jar即可。
要把Jar运行到Yarn有2种模式:
- cluster模式:在Yarn集群里拉起一个ClusterManager容器(也就是ApplicationMaster),由它拉起executor容器,此时本地driver程序不负责调度,仅通过网络从ClusterManager拉取最新进度。
- client模式:本地Driver客户端直接与yarn的ResourceManager交互,此时集群里没有ClusterManager容器,而是由本地客户端直接执行它的逻辑。
生产环境中我们会用cluster模式完全托管整个spark任务,这样客户端可以离开。
调试开发环境中,我们用client模式可以打印出中间计算结果到终端上,方便快速调试程序正确性。
下载spark
访问https://spark.apache.org/downloads.html,下载不带hadoop的spark版本:
解压到安装有hadoop的服务,比如我现在这么放置:
|
1 2 3 4 5 6 7 8 |
root@ubuntu:~/bigdata# ll total 16 drwxr-xr-x 27 root root 4096 Sep 30 07:24 azkaban/ drwxr-xr-x 2 root root 4096 Oct 4 10:48 demo/ drwxr-xr-x 12 1001 1001 4096 Sep 30 09:43 hadoop-3.3.0/ drwxr-xr-x 13 work work 4096 Aug 28 08:31 spark-3.0.1/ root@ubuntu:~/bigdata# pwd /root/bigdata |
修改/etc/profile,把spark目录下的bin加入到PATH中(重新登录一下会话):
export PATH=/usr/local/jdk/bin:/root/bigdata/hadoop-3.3.0/bin:/root/bigdata/spark-3.0.1/bin:${PATH}
现在可以直接访问到spark-submit等命令,说明PATH正常。
接下来的配置严格遵守spark官方文档,都是必要配置:https://spark.apache.org/docs/latest/running-on-yarn.html
配置spark-env.sh
类似于hadoop-env.sh,给spark命令和程序提供环境变量的文件。
我们需要复制一份默认模板:
cp conf/spark-env.sh.template conf/spark-env.sh
然后打开spark-env.sh,加入如下3行必须配置项:
|
1 2 3 |
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/root/bigdata/hadoop-3.3.0/lib/native export SPARK_DIST_CLASSPATH=$(hadoop classpath) export HADOOP_CONF_DIR=/root/bigdata/hadoop-3.3.0/etc/hadoop |
- LD_LIBRARY_PATH:帮助spark系列命令加载到hadoop的.so动态库。
- SPARK_DIST_CLASSPATH:hadoop classpath是调用hadoop命令获取hadoop基础jar包作为spark的依赖。
- HADOOP_CONF_DIR:指定hadoop的配置文件所在目录,比如spark会去下面读取hadoop-env.sh,需要大家根据自己hadoop路径改一下。
配置spark-defaults.conf
该文件是spark程序的默认运行时配置项。
当我们通过spark-submit提交程序时,会为spark任务默认加载这些配置项,这样spark程序里就不需要通过代码重复设置了。
拷贝一份模板配置:
cp conf/spark-defaults.conf.template conf/spark-defaults.conf
在spark-env.sh中配置的LD_LIBRARY_PATH只能帮助客户端找到hadoop的native so动态库,当spark任务运行到yarn集群中之后则需要通过给spark任务带上这样的property才能帮助executor在所在机器找到本地的hadoop动态库:
|
1 |
spark.executor.extraLibraryPath /root/bigdata/hadoop-3.3.0/lib/native/ |
没有上述配置,如果在spark里操作带压缩的文件就会报一些警告信息甚至失败。
验证安装
可以通过spark-submit命令,运行spark自带的一个demo任务:
|
1 |
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 4g --executor-memory 2g --executor-cores 1 --queue default examples/jars/spark-examples*.jar 10 |
如果运行没有报错,则说明安装成功。
安装spark on yarn就是这么简单,后面几篇博客会演示一下spark编程。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

打卡~谢谢分享
1