hive系列 – hive搭建
本文记录hive3.x版本搭建过程。
Hive用于数仓建设,通过SQL实现大数据的统计与报表,是离线计算的关键组件。
Hive架构
hive和mysql的使用方式是差不多的,都是建表跑SQL做数据处理与统计,这样就免去编程了。
区别是Hive运行在大数据集上进行分布式计算,Mysql则是单机计算,能够处理的数据规模不同;另外,Hive用于数仓场景,有一套自己的数据分层理论,仅此而已。
要搭建Hive与使用Hive,必须了解其架构原理:
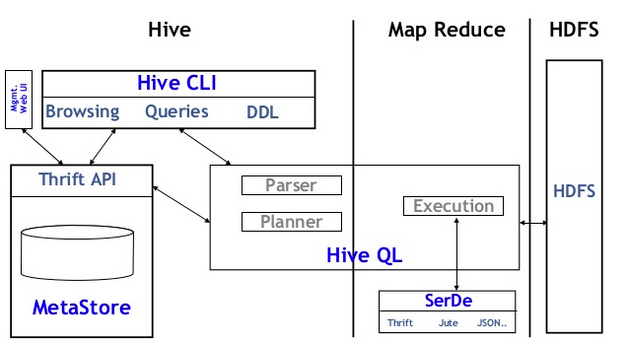
Hive的元信息和表数据是分离管理的,所有的database和table的元信息都在metastore服务里,而数据部分则在HDFS上的对应目录下。
Hive客户端需要访问Metastore服务来获取要访问的表meta信息,例如:可以获取到表有哪些字段、表有哪些分区、数据在哪个HDFS路径下。
此后,经过SQL解析器和执行计划翻译成MapReduce任务,提交到Yarn集群执行。
这里还有一个关键是理解Hive表的数据文件格式,Hive支持TextFile,SequenceFile,OrcFile等多种数据存储格式。
如果看过我之前Mapreduce的博客的话就会知道,编写MR的时候输入给Mapper的是<K,V>,每一种文件格式都已经定义好了K和V的含义:
- TextFile:K是文件偏移量,V是文本行。
- SequenceFile:K一般是NullWritable,V是行内容。
- OrcFile:K是NullWritable,V是OrcStruct。
Hive也是把表数据存储成这些格式,也是利用MR来计算这些文件,因此也就遵循上述的<K,V>约定,对于Hive来说行数据其实都在V里。
那么V里如何切出各个列呢?对于TextFile、SequenceFile可以给Hive进一步配置列解析器(一般就是按\t分隔列),OrcStruct本身就是序列化格式可以直接按列存储,这就是架构图中SERDE的作用(列解析器),每个表都有3个序列化配置项组成:
|
1 2 3 4 5 6 |
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' |
INPUTFORMAT和OUTPUTFORMAT用于解析特定文件格式为<K,V>输入给MR或者输出,而SERDE则解析一行内的多列。
下载HIVE
安装HIVE过程参考官方文档:https://cwiki.apache.org/confluence/display/Hive/GettingStarted。
从链接http://www.apache.org/dyn/closer.cgi/hive/下载最新的release即可,我下载的版本是hive3.1.3。
最终解压到安装有hadoop环境的机器上:
|
1 2 3 4 5 6 7 8 9 |
root@ubuntu:~/bigdata# ll total 20 drwxr-xr-x 27 root root 4096 Sep 30 07:24 azkaban/ drwxr-xr-x 2 root root 4096 Oct 13 08:36 demo/ drwxr-xr-x 12 1001 1001 4096 Sep 30 09:43 hadoop-3.3.0/ drwxr-xr-x 11 root root 4096 Oct 13 07:58 hive-3.1.3/ drwxr-xr-x 32 work work 4096 Aug 28 07:28 spark-3.0.1/ root@ubuntu:~/bigdata# pwd /root/bigdata |
把hive的bin目录导出PATH:
|
1 2 |
root@ubuntu:~/bigdata# cat /etc/profile.d/java.sh export PATH=/usr/local/jdk/bin:/root/bigdata/hadoop-3.3.0/bin:/root/bigdata/spark-3.0.1/bin:/root/bigdata/hive-3.1.3/bin:${PATH} |
升级guava依赖为hadoop版本:
|
1 2 |
mv lib/guava-19.0.jar lib/guava-19.0.jar.bk ln -s /root/bigdata/hadoop-3.3.0/share/hadoop/hdfs/lib/guava-27.0-jre.jar /root/bigdata/hive-3.1.3/lib/guava-27.0-jre.jar |
上述命令先备份了将hive自带的guava依赖包,然后将hadoop自带的更高版本软链过来,如果不做上述操作hive命令将报错,官方一直存在这个问题,网上很容易搜到。
安装MYSQL
hive的元数据服务是独立部署的,它基于mysql保存数据。
我在ubuntu环境安装oracle mysql:
apt-get install mysql-server
通过mysql_secure_installation初始化管理员密码,这里我遇到的问题是:
mysql -h localhost -u root -p登录时,提示access denied。
后来定位是mysql user表有一条localhost的特殊规则,需要删除它:
delete from user where User=’root’ and Host=’localhost’;
FLUSH PRIVILEGES;
然后创建hive数据库:
create database hive;
另外,我们需要下载JDBC mysql(从maven仓库下载):
|
1 2 |
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.21/mysql-connector-java-8.0.21.jar mv mysql-connector-java-8.0.21.jar lib |
把该Jar放到hive的lib目录下即可,hive metastore服务将用该JDBC驱动连接mysql读写元数据。
配置HIVE
hive会自动加载conf/hive-site.xml配置文件,但是该文件默认是不存在的。
官方在conf/hive-default.xml.template提供了一个模板文件,里面是hive加载不到hive-site.xml时使用的默认值,但是这不代表hive会去加载conf/hive-default.xml.template ,默认值是存在于程序里的。
我们可以参考conf/hive-default.xml.template 来编写hive-site.xml,我 只配置了必要项:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
root@ubuntu:~/bigdata/hive-3.1.3# cat conf/hive-site.xml <?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.cli.print.header</name> <value>true</value> <description>Whether to print the names of the columns in query output.</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>xxxxx</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://localhost:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property> </configuration> |
- hive.cli.print.header:hive命令行工具将打印table的表头,方便阅读结果。
- javax.jdo.option.ConnectionURL:数据库JDBC URL,这里就是mysql的hive数据库。
- javax.jdo.option.ConnectionDriverName:JDBC类名,8.x版本Mysql jar的类名有所变化,需要注意。
- javax.jdo.option.ConnectionUserName:mysql用户名
- javax.jdo.option.ConnectionPassword:mysql密码
- hive.metastore.uris:启动metastore服务的监听地址。
启动metastore服务
先执行Hive建表命令,完成mysql元数据建表:
bin/schematool -dbType mysql -initSchema
执行命令:
nohup hive –service metastore &
服务将监听在localhost:9083端口,生产环境我们需要让host是可以被其他服务器访问到的,因为访问metastore服务的客户端不一定在本机。
现在命令行使用hive命令,将会自动根据hive-site.xml连接到metastore服务,所以我们测试一下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
root@ubuntu:~/bigdata/hive-3.1.3# hive SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/bigdata/hive-3.1.3/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/bigdata/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Hive Session ID = f0d4bf60-d85f-456a-98fb-e904d50f5242 Logging initialized using configuration in jar:file:/root/bigdata/hive-3.1.3/lib/hive-common-3.1.3.jar!/hive-log4j2.properties Async: true Hive Session ID = 959e0cda-f8eb-4fc1-b798-cb5175e735d2 Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> show databases; OK database_name default Time taken: 0.516 seconds, Fetched: 2 row(s) |
可以看到自带的default数据库,并且还提示我们hive目前使用MR作为计算引擎,实际Hive建议我们开始使用spark或者tez作为SQL的底层计算引擎,未来最终会彻底取消MR。
目前我们继续使用MR作为计算引擎即可,hive会根据hadoop命令自动找到hadoop和yarn配置文件,最终SQL是通过MR运行在yarn上完成计算的。
至此Hive搭建完成。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1