hive系列 – spark on hive配置与编程
我们经常会选择使用spark做原始数据的ETL清洗,清洗后的Dataframe最终需要写入到数仓的Hive表中,也就是说spark能否直接读写hive表特别重要。
spark on hive原理
要让spark程序可以直接读写hive表,只需要让spark可以访问到hive表的meta信息即可,因为spark自己实现了一套和hive一样的SQL引擎并且底层直接用spark运算,其SQL已经支持了hive的大部分特性。
下面是Hive和Spark的关系:
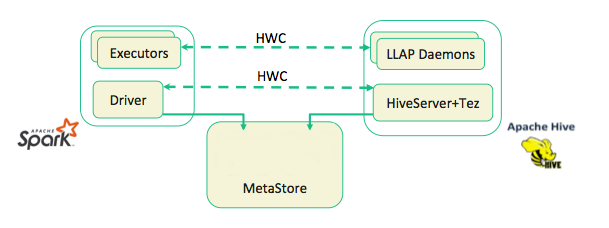
说白了,spark把hive又实现了一遍,为了和hive可以联动所以支持直接操作hive的metastore来共享元数据。
这里容易和hive on spark混淆,hive on spark是将hive的计算引擎换成spark,目的是为了加速计算。而这里的spark on hive是为了可以让spark可以读写hive表,以便可以通过Java编程形式的方式实现灵活的数据计算。
配置spark on hive很简单,把hive-site.xml软链接到spark的conf目录下即可,spark会自动读取该配置来识别metastore的地址。
ln -s /root/bigdata/hive-3.1.3/conf/hive-site.xml /root/bigdata/spark-3.0.1/conf/hive-site.xml
这就配置完成了,下面我们编写一个具体的spark程序作为示例,项目地址:https://github.com/owenliang/spark-sql-demo。
引入maven依赖
在《spark系列 – spark-sql编程使用》中,我演示了如何通过spark-sql库操作Dataframe以及直接写Hive格式的数据到HDFS指定路径下。
但是我们要注意,spark-sql虽然可以将DataFrame输出到HDFS上作为Hive表的数据,但是并没有修改过metastore中的元数据,所以并没有真的与HIve联动,Hive侧是看不到对应的表或者数据的。
要让spark-sql库可以直接读写metastore,我们需要引入另外spark-hive库来支持hive:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.1</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.0</version> </dependency> <dependency> <!-- Spark dependency --> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.1</version> <scope>provided</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>3.0.1</version> </dependency> </dependencies> |
编写spark操作hive
接下来我们用spark直接创建hive数据库和表结构,然后将DataFrame的数据插入到hive表里。
初始化SparkSession需要额外调用enableHiveSupport()开启Hive支持,它会去spark的conf目录读取hive-site.xml配置获取metastore地址,其他代码没有变化:
|
1 2 3 4 5 6 7 |
public class Main { public static void main(String []args) { try { // spark sql session SparkSession sess = SparkSession.builder().appName("spark-sql-demo").enableHiveSupport().getOrCreate(); // hdfs FileSystem dfs = FileSystem.get(new Configuration()); |
既然spark已经和hive直通了,我们可以像使用hive cli一样直接写Hive sql:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
package cc.yuerblog.sql; import org.apache.hadoop.fs.FileSystem; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import java.io.IOException; public class HiveTest { public void run(FileSystem dfs, SparkSession sess) throws IOException { // 建hive库 sess.sql("create database if not exists spark "); // 切库 sess.sql("use spark"); // 建表 sess.sql("create table if not exists people(name string, age int) stored as orc"); // 加载JSON DataFrame Dataset<Row> df = sess.read().json("/people.txt"); // 查看DataFrame df.show(); // 创建视图 df.createOrReplaceTempView("people_view"); // 追加到表里(注意通过select调整视图表的字段顺序与hive表一致) sess.sql("insert into table people select name,age from people_view"); } } |
- 创建数据库:create database if not exists spark
- 使用数据库:use spark
- 创建people表:create table if not exists people(name string, age int) stored as orc,采用Orc列存储格式,Hive表一般采用列存来提升查询效率,压缩数据量。
- 加载DataFrame:通过sparkSession加载json文件/people.txt,里面每一行是json字符串,包含name和age两个字段。
- 创建视图:把Dataframe创建为视图表people_view,它只是逻辑视图,实际做计算时才会通过DAG图计算出来,不会真的存在Hive里。
- 插入people表:把视图表的数据select出来,插入到hive people表中去。(这里需要注意select字段的数量和顺序必须和hive表结构完全一致,hive插入时就是这样要求的,并不是spark特殊)
运行spark程序
将上述代码打包成jar,然后提交:
spark-submit –master yarn –deploy-mode client –executor-memory 1G –num-executors 1 ./spark-sql-demo-1.0-SNAPSHOT.jar
查看df.show()打印了DataFrame表格:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
2020-10-14 05:53:02,225 INFO codegen.CodeGenerator: Code generated in 13.879469 ms +---+---------+ |age| name| +---+---------+ | 83| person-0| | 96| person-1| | 96| person-2| | 34| person-3| | 93| person-4| | 64| person-5| | 25| person-6| | 33| person-7| | 91| person-8| | 72| person-9| | 90|person-10| | 74|person-11| | 68|person-12| | 66|person-13| | 93|person-14| | 92|person-15| | 79|person-16| | 36|person-17| | 84|person-18| | 51|person-19| |
利用hive cli查看hive表:
hive> select * from spark.people limit 10;
OK
people.name people.age
person-0 83
person-1 96
person-2 96
person-3 34
person-4 93
person-5 64
person-6 25
person-7 33
person-8 91
person-9 72
Time taken: 2.554 seconds, Fetched: 10 row(s)
本篇博客就这些内容,spark操作hive体验和hive基本一致,但是可以把dataframe转成view并通过hive sql直接访问是很实用的特性。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1