java – 理解classloader
最近学习大数据,意识到java不仅解决了C++高昂的内存管理成本之外,其”类动态加载”和”反射”机制无疑有效的支撑了”计算向存储移动”思路的落地,难怪java语言在大数据领域成为主流选择。
如果我们接触过mapreduce的话,就不得不产生一个这样的疑惑:
业务编写的mapper和reducer类,是如何被mapreduce框架分发到任意计算节点、实例化为对象并且执行相关函数的?
本文简单清晰的揭示classloader原理,看完之后将会明白java如何是将class移动到远端并实例化执行的。
classloader原理
编译好的.java源代码保存为.class字节码文件,代码中import一个类时就是由classloader去相应的磁盘路径下读取.class文件到内存中来实现的。
java自带了3个classloader,它们呈现分层关系,分别负责去不同的磁盘路径加载.class。
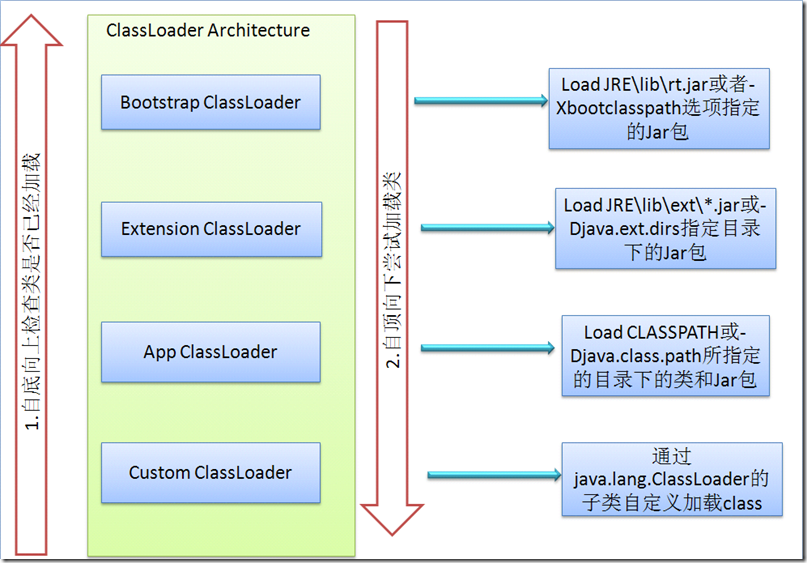
- bootstrap classloader:最顶层的loader,它伴随java启动而生效,负责加载JRE/lib/rt.jar等运行时核心类。
- extension classloader:负责去JRE/lib/ext目录下搜索加载一些功能扩展类。
- app classloader:负责帮应用程序加载类,一般通过环境变量CLASSPATH或者-Djava.class.path来指定搜索路径。
- custom classloader:我们可以自定义classloader类,通过任意方式找到.class文件并加载它。
当我们import或者反射1个classname时,java默认会帮我们调用app classloader的loadClass方法来加载.class,但是app classloader并不会立即做查找而是递归调用extension classloader的loadClass,同样extension classloader也会先递归调用bootstrap classloader的loadClass,如果递归返回没有找到,那么classloader才会通过自己的方式查找.class文件。
这种先递归向上再回溯的方式可以保证,如果bootstrap里面已经加载过该.class,那么下层的extension/app/custom classloader就不需要自己去查找了。这样也带来了一些安全性,比如我们在下层放一个伪造的String.class文件并不会覆盖标准库,因为查找String类的过程是自顶向下的,在bootstrap loader层就已经找到了。
验证ClassLoader
看如下代码:
|
1 2 3 4 5 6 7 8 9 10 11 |
package cc.yuerblog; public class TestLoader { public static void main(String []args) { ClassLoader loader = TestLoader.class.getClassLoader(); while (loader != null) { System.out.println(loader.getClass().getName()); // 打印classloader实例的类名 loader = loader.getParent(); } } } |
TestLoader就是我们程序写的类,它是由app ClassLoader负责加载的,当然app ClassLoader会委托上层的loader先行查找,最后才轮到它自己。
上述程序输出:
sun.misc.Launcher$AppClassLoader
sun.misc.Launcher$ExtClassLoader
app ClassLoader的父亲是ext ClassLoader,ext classloader的父亲应该是bootstrap ClassLoader,然而因为bootstrap ClassLoader是C++实现在JVM内核心代码,所以JAVA层无法真的获取到它。
另外一个例子,我们利用当前的app classloader加载一下java.lang.String类,实际会由bootstrap ClassLoader完成真正加载:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
package cc.yuerblog; public class TestLoader { private static class MyClassLoader extends ClassLoader{ } public static void main(String []args) { ClassLoader loader = TestLoader.class.getClassLoader(); try{ Class strClz = loader.loadClass("java.lang.String"); // 调用app classloader进行加载 System.out.println(strClz.getClassLoader()); // 打印null,因为是bootstrap classloader真正加载的 } catch (Exception e) { System.out.println(e); } } } |
打印:
null
app classloader委托查找给bootstrap classloader,因为String类放在bootstrap classloader的加载路径下,所以被它实际加载,因此打印String类的classLoader是null(bootstrap classloader是c++实现的),可见class的loader是谁取决于真正加载者,并不一定是我们直接调用的loader。
自定义classloader
我们可以自定义ClassLoader类,只有上层loader都找不到要加载的class时,才轮到我们自定义的查找方法执行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
package cc.yuerblog; public class TestLoader { private static class MyClassLoader extends ClassLoader{ @Override protected Class<?> findClass(String name) throws ClassNotFoundException { Class clz = null; // 1,我们去磁盘或者网络读取对应的.class文件,将它的二进制内容读取进来 // 2,调用defineClass()方法,传入二进制内容,返回一个Class对象 if (clz == null) { throw new ClassNotFoundException(); } return clz; } } public static void main(String []args) { try{ ClassLoader loader = new MyClassLoader(); System.out.println(loader.getParent().getClass().getName()); Class a = loader.loadClass("java.lang.String"); System.out.println(a.getClassLoader()); Class b = loader.loadClass("cc.yuerblog.TestLoader"); System.out.println(b.getClassLoader().getClass().getName()); Class c = loader.loadClass("cc.yuerblog.fake"); System.out.println(c.getClassLoader()); } catch (Exception e) { System.out.println(e); } } } |
首先自定义了MyClassLoader类,我们只需要实现findClass方法,通过任意方式把类对应的.class内容读取进来即可;我们不需要覆盖loadClass方法,因为loadClass方法已经实现先查找上层loader最后再调用findClass的逻辑。
程序输出:
sun.misc.Launcher$AppClassLoader
null
sun.misc.Launcher$AppClassLoader
java.lang.ClassNotFoundException
- MyClassLoader的父loader默认是sun.misc.Launcher$AppClassLoader,也可以构造MyClassLoader的时候手动传入父loader。
- String会被委托给祖父bootstrap loader加载得到。
- cc.yuerblog.TestLoader是我们程序入口类,当然是委托给父sun.misc.Launcher$AppClassLoader搞定的。
- cc.yuerblog.fake压根不存在,所以app classloader也不会成功,而轮到我们的MyClassLoader时因为findClass压根没实现加载.class逻辑直接抛出了class not found。
class相等性问题
只有同1个classloader实例加载的class对象才会相等,就像这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
package cc.yuerblog; public class TestLoader { private static class MyClassLoader extends ClassLoader{ @Override protected Class<?> findClass(String name) throws ClassNotFoundException { Class clz = null; // 1,我们去磁盘或者网络读取对应的.class文件,将它的二进制内容读取进来 // 2,调用defineClass()方法,传入二进制内容,返回一个Class对象 if (clz == null) { throw new ClassNotFoundException(); } return clz; } } public static void main(String []args) { try{ ClassLoader loader1 = new MyClassLoader(); ClassLoader loader2 = new MyClassLoader(); Class a = loader1.loadClass("cc.yuerblog.TestLoader"); Class b = loader2.loadClass("cc.yuerblog.TestLoader"); System.out.println(a==b); } catch (Exception e) { System.out.println(e); } } } |
虽然我new了2个MyClassLoader,但是它们加载cc.yuerblog.TestLoader都是委托给同一个app classloader实例对象完成的,因此返回的是同1个class对象。
如果某个class是通过MyClassLoader的findClass方法加载的,而我们通过2个不同MyClassLoader实例加载同一个class,则2个class一定是不等的。
所以我们要注意classloader的单例化是非常重要的,java自带的都是单例的,并且classloader基类的loadClass方法默认会记住曾经加载过的class对象,因此同一个类总是返回同一个class对象。
实战:动态加载jar包中的类
我们模拟mapreduce框架的工作流程:
- 将业务开发的mapper和reducer类打包成jar
- 由另外一个程序通过classloader来加载jar包中的类,反射创建实例并执行map和reduce方法。
项目地址:https://github.com/owenliang/classloader-demo
打包mapper和reducer
在mapreduce项目中,我们实现业务的mapper和reducer类:
|
1 2 3 4 5 6 7 |
package cc.yuerblog; public class Mapper { public void map() { System.out.println("map"); } } |
与
|
1 2 3 4 5 6 7 |
package cc.yuerblog; public class Reducer { public void reduce() { System.out.println("reduce"); } } |
将它们通过maven打包到jar包里:C:\Users\xx\IdeaProjects\classloader-demo\mapreduce\target\mapreduce-1.0-SNAPSHOT.jar。
上传至hdfs
上述mapreduce jar包放在本地磁盘上,我们假想这就是hdfs分布式文件系统。
运行mapreduce
当MR框架选定任意计算节点之后,会从hdfs上(也就是我们的本地磁盘)找到jar包,并通过自定义classloader加载jar包中的class。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
package cc.yuerblog; import java.lang.reflect.Method; import java.net.MalformedURLException; import java.net.URL; import java.net.URLClassLoader; public class Hadoop { public static void main(String[] args) { String mapperClass = args[0]; String reducerClass = args[1]; try { URL []classpath = new URL[] { new URL("file:C:\\Users\\xx\\IdeaProjects\\classloader-demo\\mapreduce\\target\\mapreduce-1.0-SNAPSHOT.jar") }; // 在jar中加载class URLClassLoader loader = new URLClassLoader(classpath); Class mapperClz = loader.loadClass(mapperClass); Class reducerClz = loader.loadClass(reducerClass); // 反射构造对象 Object mapper = mapperClz.newInstance(); Object reducer = reducerClz.newInstance(); // 反射方法 Method map = mapperClz.getMethod("map"); Method reduce = reducerClz.getMethod("reduce"); // 执行 map.invoke(mapper); reduce.invoke(reducer); } catch (Exception e) { System.out.println(e); } } } |
业务的mapper和reducer类名,需要通过命令行告知MR框架,然后MR框架会通过classloader从HDFS下载Jar包然后去里面找到这两个类,因此运行命令是:
java -jar C:\Users\xx\IdeaProjects\classloader-demo\hadoop\target\hadoop-1.0-SNAPSHOT.jar cc.yuerblog.Mapper cc.yuerblog.Reducer
map
reduce
能够扫描jar包中.class文件的Classloader不用我们自己实现,标准库自带一个URLClassLoader,因此我们直接把要查找的所有路径与JAR包拼成一个URL数组,构造一个URLClassLoader对象即可。
显然URLClassLoader能够从指定的jar包中找到mapper和reducer类,经过反射创建实例后调用它们的对应方法即可。
如果你用过hadoop就会知道,hadoop提交MR任务的命令是:
hadoop -jar xxxx.jar,实际上hadoop命令会将jar包保存到HDFS,然后任意worker就可以通过自定义的classloader从hdfs上的xxxx.jar中加载到业务的mapper和reducer类了。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1