推荐业务的JAVA程序性能分析
本文分享一下近期在推荐业务场景下的JAVA程序性能分析过程,虽然没有得到什么有效的优化结论,但过程中的思路和工具还是挺有价值的,也希望能与碰到类似场景的朋友进行交流。
场景描述
某业务基于CTR的个性化内容推荐在线服务,使用JAVA开发,其主要逻辑为:
- 周期性从外部存储拉取内容候选池文章数万篇,每篇文章包含了数百列文章特征,全部缓存到JVM内存中。
- 收到调用后,从数万篇文章中简单过滤出数千篇文章特征,从redis获取该用户特征,然后将该用户特征向量与数千篇文章的特征向量进行拼接得到数千行输入向量,grpc调用tensorflow-serving进行模型打分,最终排序返回结果。
部署规格
- 容器配置:28核28G
- JVM配置:G1垃圾回收,25G jvm heap
性能问题
- 压测极限QPS=15,响应时间在1秒内分布,继续加大并发只会增加延迟。
- CPU使用率80%+,网络带宽150MB/s。
诞生疑问,为什么响应慢?为什么耗CPU?
缩小范围
我们就2个方向进行探索:
- 延迟高问题
- CPU高问题
延迟高问题
作为经验之谈,建议在这个阶段进行日志埋点,把从入口开始到返回的每一段代码进行耗时统计并输出到日志,这是最快找到慢代码环节的方法。
千万不要上来就CPU火焰图分析,因为代码慢不一定是CPU计算重导致的,可能是I/O,可能是GC,也可能是其他瓶颈。
通过日志埋点,发现耗时长的代码竟然只是对一个存储配置的只读HashMap的get操作,竟然会慢到200~300+毫秒,其他代码环节均没有这种情况。
此时最大怀疑是GC导致卡顿引起,但是不太理解的是此处没有内存分配为什么会触发GC呢?
其实这与GC的基本原理有关,因为程序是多线程的,所以其他线程分配内存时也会触发GC。
GC算法必须有一个环节要停住所有线程以便进行一些关键的内存统计/标记,我们称这个行为是STW(stop the world),所以只要有任意线程触发了GC那么其他线程也要停顿。
JVM停顿线程是主动方式,JVM会在业务代码里的合适位置插入一些叫做safepoint的代码调用,一旦GC触发则所有线程只有执行到safepoint位置才会真的停止执行,所以我们可以猜测这个hashmap的get方法前后有safepoint,导致STW发生在它执行期间而已。
此前也怀疑过网络带宽瓶颈导致GRPC卡顿影响延迟,但其实通过上述日志埋点表现来看就已经排除了这个怀疑。
接下来就GC表现进行具体的数据分析,首先开启GC日志:
|
1 2 3 |
- -Xloggc:/root/gc.log - -XX:+PrintGCDetails - -XX:+PrintGCTimeStamps |
然后压测一下接口,表现如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Requests per second: 16.18 [#/sec] (mean) Time per request: 309.073 [ms] (mean) Time per request: 61.815 [ms] (mean, across all concurrent requests) Transfer rate: 36.23 [Kbytes/sec] received 7.74 kb/s sent 43.97 kb/s total Connection Times (ms) min mean[+/-sd] median max Connect: 1 1 0.1 1 4 Processing: 178 308 62.0 299 722 Waiting: 178 308 62.0 299 722 Total: 179 309 62.0 300 723 Percentage of the requests served within a certain time (ms) 50% 300 66% 325 75% 343 80% 356 90% 389 95% 420 98% 462 99% 491 100% 723 (longest request) |
压力对程序来说已经到达极限,此时平均16.18QPS,延迟长尾还不算差(723毫秒)。
我们可以观察一下GC日志/root/gc.log,发现是大量的young gc在发生,没有full gc的问题,说明处理请求期间的确大量的一次性内存分配在发生。
456273.182: [GC pause (G1 Evacuation Pause) (young), 0.1509288 secs]
[Parallel Time: 132.9 ms, GC Workers: 23]
[GC Worker Start (ms): Min: 456273183.1, Avg: 456273183.6, Max: 456273184.1, Diff: 1.0]
[Ext Root Scanning (ms): Min: 0.5, Avg: 1.1, Max: 3.3, Diff: 2.9, Sum: 24.7]
[Update RS (ms): Min: 0.0, Avg: 1.0, Max: 1.2, Diff: 1.2, Sum: 23.7]
[Processed Buffers: Min: 0, Avg: 7.1, Max: 19, Diff: 19, Sum: 164]
[Scan RS (ms): Min: 0.1, Avg: 0.3, Max: 0.4, Diff: 0.3, Sum: 6.6]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 128.6, Avg: 129.1, Max: 129.2, Diff: 0.6, Sum: 2969.7]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 23]
[GC Worker Other (ms): Min: 0.0, Avg: 0.2, Max: 0.5, Diff: 0.5, Sum: 5.6]
[GC Worker Total (ms): Min: 131.2, Avg: 131.8, Max: 132.3, Diff: 1.1, Sum: 3030.3]
[GC Worker End (ms): Min: 456273315.1, Avg: 456273315.3, Max: 456273315.6, Diff: 0.5]
[Code Root Fixup: 0.1 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 2.0 ms]
[Other: 16.0 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 12.0 ms]
[Ref Enq: 0.1 ms]
[Redirty Cards: 0.8 ms]
[Humongous Register: 0.3 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 2.1 ms]
[Eden: 14.3G(14.3G)->0.0B(13.7G) Survivors: 752.0M->1360.0M Heap: 19.0G(25.0G)->5467.1M(25.0G)]
[Times: user=3.00 sys=0.00, real=0.15 secs]
456654.671: [GC pause (G1 Evacuation Pause) (young), 0.1045057 secs]
[Parallel Time: 88.9 ms, GC Workers: 23]
[GC Worker Start (ms): Min: 456654671.8, Avg: 456654672.4, Max: 456654673.2, Diff: 1.3]
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.7, Max: 3.6, Diff: 3.5, Sum: 16.0]
[Update RS (ms): Min: 0.0, Avg: 0.5, Max: 0.6, Diff: 0.6, Sum: 10.9]
[Processed Buffers: Min: 0, Avg: 6.5, Max: 11, Diff: 11, Sum: 150]
[Scan RS (ms): Min: 0.1, Avg: 0.2, Max: 0.3, Diff: 0.2, Sum: 5.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 84.5, Avg: 86.1, Max: 86.4, Diff: 1.9, Sum: 1980.0]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 23]
[GC Worker Other (ms): Min: 0.0, Avg: 0.3, Max: 0.6, Diff: 0.5, Sum: 7.7]
[GC Worker Total (ms): Min: 86.9, Avg: 87.8, Max: 88.6, Diff: 1.7, Sum: 2019.7]
[GC Worker End (ms): Min: 456654760.0, Avg: 456654760.3, Max: 456654760.5, Diff: 0.5]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 1.8 ms]
[Other: 13.8 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 10.7 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.5 ms]
[Humongous Register: 0.2 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 1.8 ms]
[Eden: 13.7G(13.7G)->0.0B(14.3G) Survivors: 1360.0M->752.0M Heap: 19.0G(25.0G)->4870.3M(25.0G)]
[Times: user=2.00 sys=0.00, real=0.10 secs]
根据红色部分,可以统计本次GC和上次GC之间的时间差、本次GC掉了多少内存,GC的停顿是多少。
那么就可以根据一些日志,输出一张这样的GC统计表:
| 上次YGC后的young区 | 上次YGC结束时间(相对) | 本次YGC前的young区 | 本次YGC开始时间(相对) | 期间young区增长量 | YGC时间间隔 | 分配速率 | 本次GC耗时 |
| 0B | 1218.595 | 14.8G | 1219.432 | 14.8G | 0.837s | 17.68GB/s | 54ms |
| 0B | 1219.432 | 14.8G | 1220.254 | 14.8G | 0.822s | 18.00GB/s | 45ms |
| 0B | 1220.254 | 14.7G | 1221.128 | 14.7G | 0.874s | 16.82GB/s | 45ms |
| 0B | 1221.128 | 14.8G | 1222.120 | 14.8G | 0.992s | 14.92GB/s | 45ms |
计算1218.595~1222.120总时间区间内,平均Young内存分配速率:
平均分配速率 = (14.8+14.8+14.7+14.8) / (1222.120-1218.595) = 16.77GB/s
计算平均每秒GC次数:
平均每秒GC次数 = 4 / (1222.120-1218.595) = 1.135次/s
计算平均GC时间:
平均GC时间 = (54+45+45+45) / 4 = 47.25ms
可见内存分配很重,每秒高达16.77GB/s,基本上不到2秒就会把heap吃满一轮,所以GC频率是1.135次/s,但是GC耗时没那么慢。
实际测量程序在没有压力情况下响应时间也需要300ms+,所以看到上述压测99%的请求都在491毫秒内返回,结合GC耗时与CPU高负载情况其实也算能够理解。
美团博客给过一个评估GC影响面的分析方法,如下图:
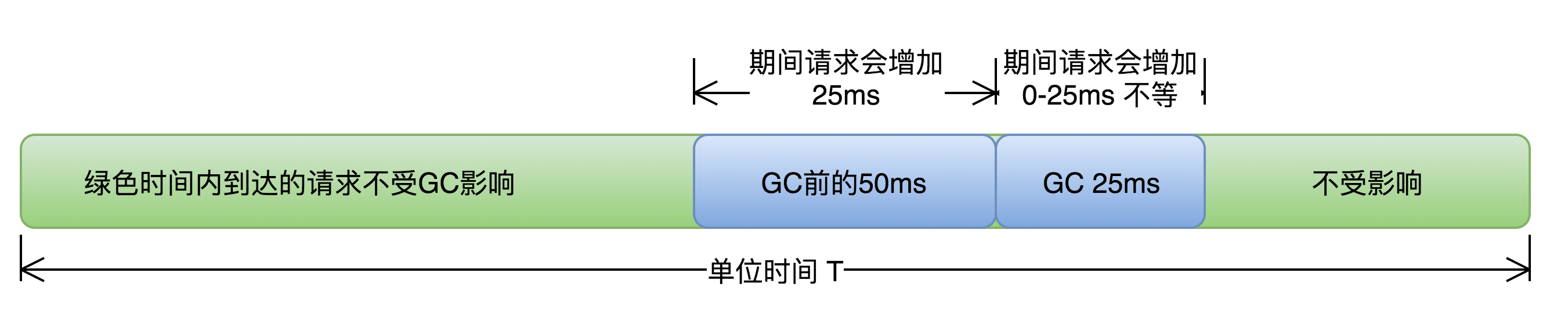
根据我们的实际统计数据:
- 平均GC时间≈ 47.25ms
- 每秒GC次数≈ 1.135次
- 接口平均响应时间(无压力情况)≈ 309ms
可以得到影响面:
- 在GC时间窗口47.25ms之内到达的请求,受GC影响会增加0~47.25ms不等。
- 在GC时间窗口之前309.45ms期间到达的请求,受GC影响一定会增加47.25ms。
- 1秒内受GC影响的请求比例为:(309ms+47.25ms)*1.135次/1000ms = 40.44%,即将近40%的请求会被GC拖慢,根据压测的响应时间分布也比较吻合。
虽然内存分配率的确很高,但这个数据也许属于合情合理范围之内,况且业务代码很难去优化减少内存分配,毕竟业务本身就是计算密集型的逻辑,所以暂且如此。
cpu高问题
压测CPU已经比较高位了,所以考虑是否可以快速找到一些可以优化CPU使用的计算逻辑,这样肯定有利于提升QPS。
如何分析java程序的CPU消耗分布呢?当然是阿里巴巴的arthas了,它可以直接attach到运行中的JVM,几乎没有损耗的监控的线程与内存表现,还可以产出CPU/MEM/Lock的火焰图,甚至直接替换运行中的class字节码,非常强大。
直接下载jar包运行即可连接到JVM进程:
|
1 2 |
curl -O https://arthas.aliyun.com/arthas-boot.jar java -jar arthas-boot.jar |
然后可以看一下实时监控:
dashboard -i 1000
分析火焰图可以这样:
|
1 2 3 |
profiler start -e cpu 等待一阵子 profiler stop |
就可以得到svg格式的CPU火焰图了,直接拷到电脑上双击浏览器打开即可(另外它还支持Mem分配火焰图,Lock锁时间火焰图)。
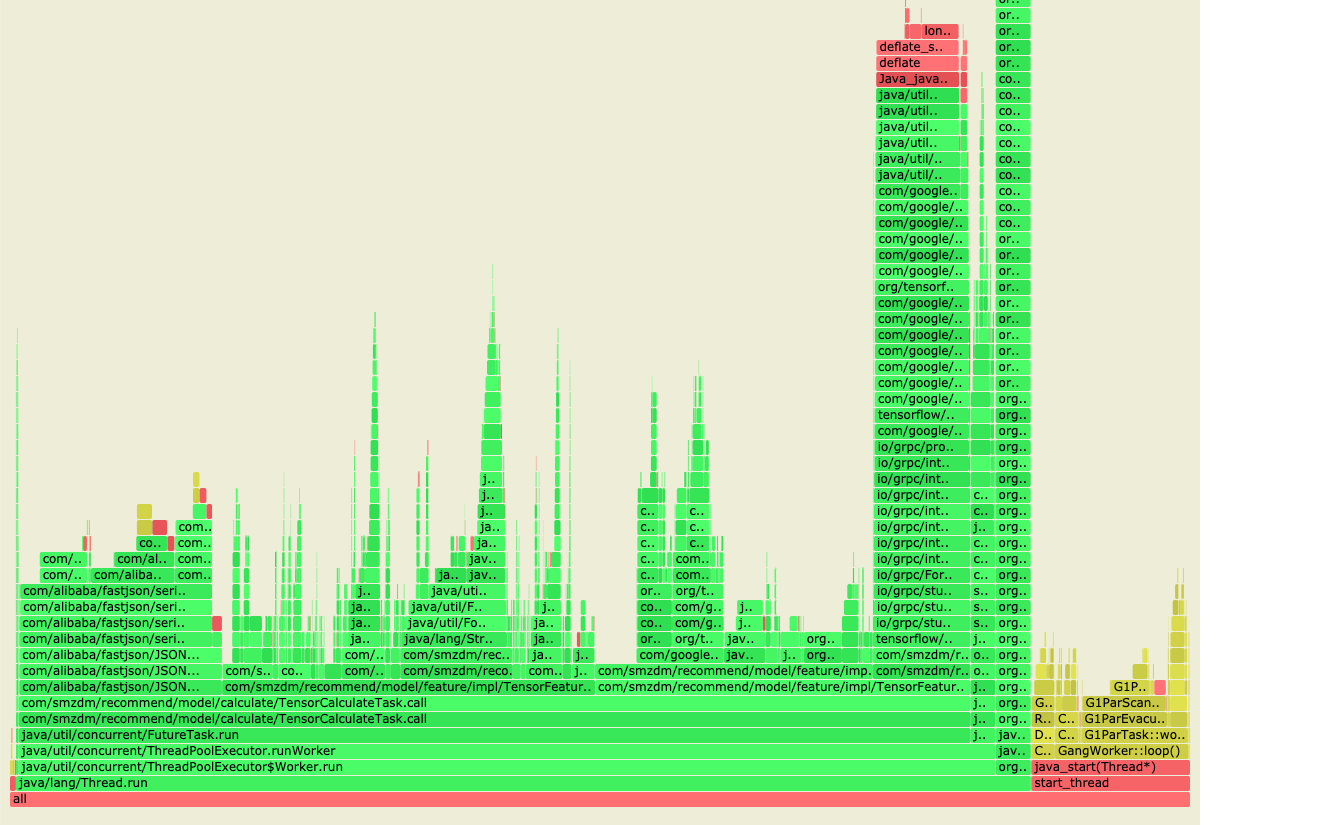
简单优化了一下比较宽的那些函数调用,收效甚微,可能程序整体计算量客观很大,一点点细节已经无足轻重,索性放弃了优化。
为了确认一下CPU瓶颈,于是找了一台64核128G的高配虚拟机,验证一下更多的CPU是否可以带来更高的QPS。
此时压测发现QPS仍旧丝毫未动,即便调大了jvm heap到120G,也无法用掉所有的64核心,此时 GC耗时已到达数百毫秒,程序就像被一把锁hold住了一样,当然程序里并没有这种限制并发量的代码。
这个结果不容易解释,即便大堆一次GC需要500ms,那么1个并发大约可以带来2个QPS,我只要加更多的并发量,在CPU够用的情况下应该可以继续提升QPS吧?为什么现在还剩好多CPU无法用上呢?
此时发现JVM分配速率只有20GB/s,似乎并没有比之前的16GB/s高多少,此时猜测可能是JVM分配能力不足或者底层内存条的带宽到达瓶颈。
内存带宽瓶颈也就是所谓的”内存墙”,是指计算密集型应用会因为大量读写内存数据,导致内存带宽打满的问题,该问题在当下AI时代开始逐步暴露出来,本质上是CPU和内存发展速度不匹配导致的,以往解决方法就是靠CPU L1/L2/L3缓存来实现内存读加速。
大家可以看一下DDR内存带宽的相关话题,会有更加具体的认识:
山穷水复
因为实在没有其他线索,所以我决定看一下内存带宽是否真的到达了瓶颈。
目前已知JVM的内存分配带宽是20GB/s,但并不知道程序对这些内存的读与写带宽是多少,为了监控JVM压测期间的实时内存带宽则需要使用物理机才能实现,因为这属于硬件级指标必须从物理CPU获取,而虚拟机是无权访问到硬件级的统计数据的。
于是只能先用sysbench命令压一下虚拟机的极限内存带宽,发现随机写的表现是很差的,大约只有1GB/s左右,但是顺序读写还是可以跑到几十G的。
由于无法获取压测期间的实时内存带宽,工作一筹莫展,于是决定搞一台高配物理机试一下。
这里刻意选择了一款带睿频3.7GHz的48核,内存DDR4 2666MHz将近190GB的物理机做最终验证,利用实时带宽监控工具:https://github.com/opcm/pcm,下载编译后运行pcm-memory.x命令即可实时监控到内存带宽:
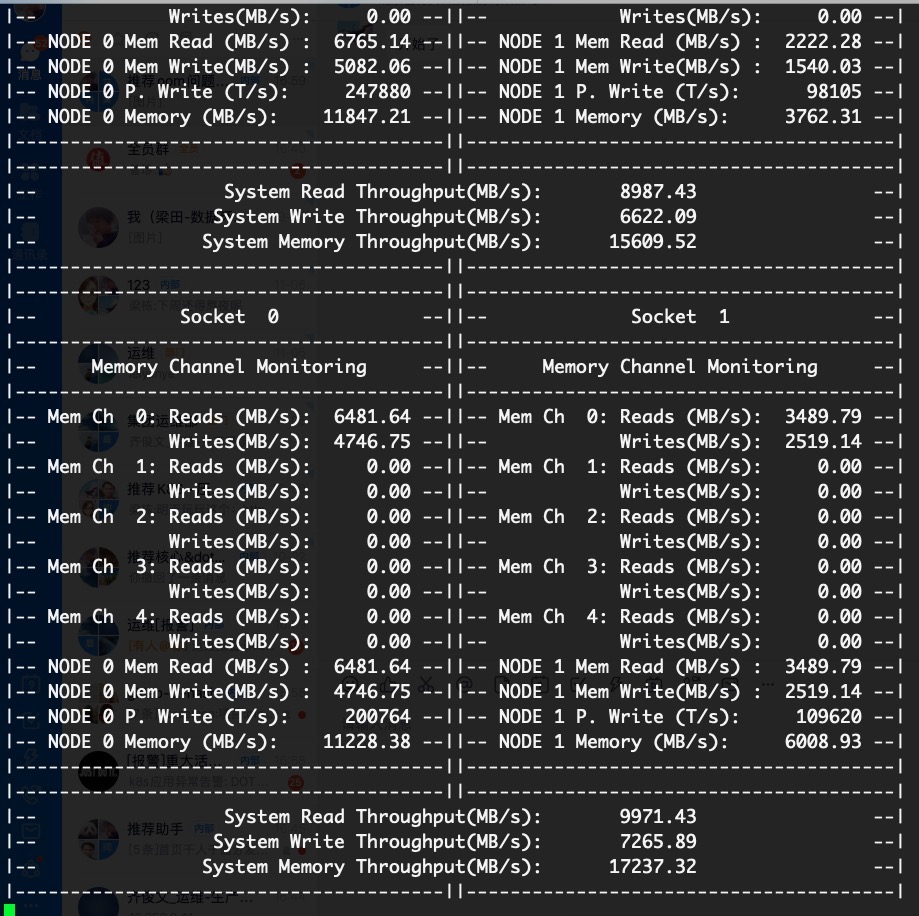
Socket0与Socket1代表两颗CPU(每颗多核心),每颗CPU访问多个内存通道,我们可以只关注下方的汇总带宽。
为了观察更多CPU是否可以得到更多QPS,以及随机QPS提高是否遇到内存带宽瓶颈,我选择逐步增加并发来得到一组数据:
并发=1,内存带宽=12G,idle=89,QPS=3.06,延迟=327ms。
并发=2,内存带宽=24G,idle=79,QPS=5.77,延迟=346ms。
并发=3,内存带宽=35G,idle=71,QPS=8.29,延迟=361ms。
并发=4,内存带宽=40G,idle=55,QPS=10.17,延迟=393.449ms。
并发=5,内存带宽=45G,idle=45,QPS=11.07,延迟=451.558ms。
并发=6,内存带宽=52G,idle=37,QPS=12.88,延迟=465.810ms。
并发=7,内存带宽=60G,idle=26,QPS=13.27,延迟=527.453ms。
并发=8,内存带宽=68G,idle=20,QPS=15.97,延迟=500.973ms。
并发=9,内存带宽=71G,idle=13,QPS=17.36,延迟=518.303ms。
并发=10,内存带宽=71G,idle=5,QPS=15.95,延迟=626.784ms。
根据这组数据,我们发现每增加1个并发可以带来2个QPS并额外消耗掉10%左右的CPU(对应4.8个核),内存带宽基本线性提升,响应延迟逐步升高导致QPS非线性提升,最终cpu idle几乎耗尽导致内存带宽也无法继续提升。
此时70G的内存带宽的确令人望而生畏,也许64核虚拟机无法打满CPU的原因是内存带宽瓶颈,而此时48核则CPU先达到瓶颈了吧,真的很难说。。
虽然没有完全确认上述结论,但是在当前配置下基本可以认为在内存带宽瓶颈尚未瓶颈的情况下CPU已经瓶颈,而且该业务本身的计算密集型场景是必须面对的客观事实,毕竟一次请求将根据精排文章数量放大数千倍再根据特征数量放大数百倍,这种计算量恐怕也很难从外围给予”免费优化”了。
如果大家有类似场景欢迎一起留言交流。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1