【mysql】为什么count那么慢?
最近有个接口偶尔超时,定位发现某些user因为记录数较多,导致count的SQL耗费了1~2秒,分析到最后其实就回到了老问题:“覆盖索引”。
背景
表结构如下:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE `t_track` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `user_id` bigint(20) DEFAULT NULL , `article_id` varchar(50) DEFAULT NULL, `article_channel_id` int(1) DEFAULT NULL , `access_time` datetime DEFAULT NULL , PRIMARY KEY (`id`), KEY `idx_user_id_article_id` (`user_id`,`article_id`), KEY `idx_access_time` (`access_time`) ) ENGINE=InnoDB AUTO_INCREMENT=113163268 DEFAULT CHARSET=utf8 |
慢SQL如下,统计出的count值为2万,耗时1.8秒:
|
1 |
select count(distinct article_id) from t_track where user_id=383822 and article_channel_id!=22; |
数据库是SSD磁盘,性能方面没有问题。
分析
SQL走idx_user_id_article_id索引过滤user_id=383822的记录,一共就2万多条,再怎么count也不应该卡顿到2秒时间吧?
count(distinct article_id) 是问题吗?当然也不是,2万条article_id去重没什么大不了的。
那么问题可能是article_channel_id!=22这个条件吧?
没错,去掉这个条件后SQL就不再卡顿了。
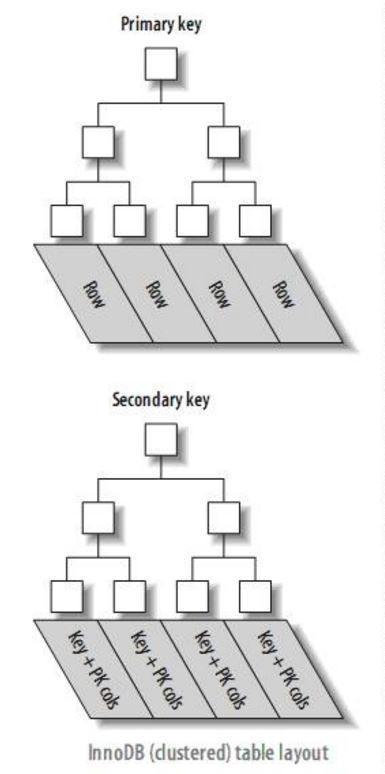
我们回顾一下innodb的索引,分为:
- Primary Key的主索引
- 其他辅助索引
当我们走idx_user_id_article_id辅助索引的时候,可以根据user_id快速定位到该用户的2万条记录,但是为了进一步过滤article_channel_id条件,必须回到主索引上来查询该字段的值。
我们知道B+树相同的key会紧密排列在相同的磁盘页上,顺序读性能是很高的,因此辅助索引在这里效率非常高;但是当拿着2万条记录的id回到主索引查询article_channel_id字段的时候,这2万条id在B+树上的分布就是散乱的,所以可能要从磁盘上的不同位置读入多个磁盘页,这就花费了很多时间做I/O。
优化
我们只需要让辅助索引的B+树key中包含article_channel_id,这样过滤时就不需要回到Primary Key的索引做二次读取了。
修改索引:KEY
idx_user_id_article_id(user_id,article_id,article_channel_id`),加入这一列即可,虽然B+树定位的时候用不上,但是过滤的时候就不需要回主索引了。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

🐂🍺
1
1
1