elasticsearch之搭建篇
Elasticsearch是一个实时分布式搜索和分析引擎,主要支持3种功能:
- 全文搜索
- 结构化搜索
- 分析
本文的目标
ES作为一个检索系统,本身具有一定的领域复杂度,因此很难一次性将所有理论知识掌握透彻,为了更快更轻松的开始使用ES,本文将采用目标驱动的方式对ES进行一个初步的掌握。
- 搭建一个分布式的ES集群。
- 以移动版糯米m.nuomi.com的美食频道为例,看看该如何基于ES实现一个类似的东西:
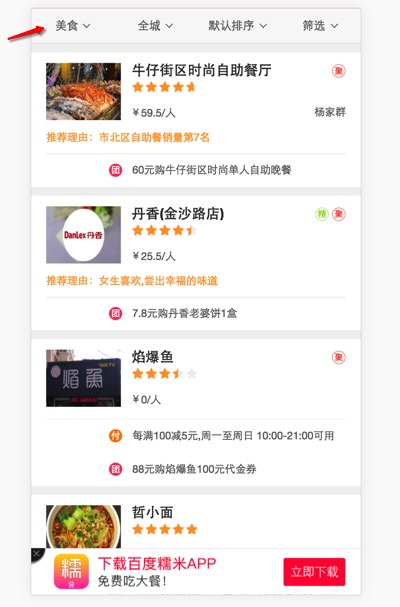
搭建ES
先切换到root用户。
安装JAVA
jre
|
1 |
yum install java |
jdk
|
1 |
yum install java-1.8.0-openjdk-devel.x86_64 |
安装Maven
去maven官网下载一个binary格式最新版本,解压后整个目录移动到/usr/local目录下:
|
1 2 3 4 5 6 7 8 9 |
[root@9a291b37ca04 ~]# ll /usr/local/apache-maven-3.3.9/ total 44 drwxr-xr-x 2 root root 4096 Mar 15 05:47 bin drwxr-xr-x 2 root root 4096 Mar 15 05:47 boot drwxr-xr-x 3 root root 4096 Mar 15 05:58 conf drwxr-xr-x 3 root root 4096 Mar 15 05:47 lib -rw-r--r-- 1 root root 19335 Nov 10 2015 LICENSE -rw-r--r-- 1 root root 182 Nov 10 2015 NOTICE -rw-r--r-- 1 root root 2541 Nov 10 2015 README.txt |
并修改其配置使用阿里云镜像加速:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[root@9a291b37ca04 ~]# vim /usr/local/apache-maven-3.3.9/conf/settings.xml <mirrors> <!-- mirror | Specifies a repository mirror site to use instead of a given repository. The repository that | this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used | for inheritance and direct lookup purposes, and must be unique across the set of mirrors. | <mirror> <id>mirrorId</id> <mirrorOf>repositoryId</mirrorOf> <name>Human Readable Name for this Mirror.</name> <url>http://my.repository.com/repo/path</url> </mirror> --> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> |
安装git
用于后续下载代码:
|
1 |
yum install git |
安装unzip
用于后续解压文件:
|
1 |
yum install unzip |
修改用户进程/线程数限制
默认centos对普通用户限制1024个进程数,ES要求不低于2048。
|
1 2 3 4 5 6 7 |
[work@9a291b37ca04 elasticsearch2]$ cat /etc/security/limits.d/90-nproc.conf # Default limit for number of user's processes to prevent # accidental fork bombs. # See rhbz #432903 for reasoning. * soft nproc 2048 root soft nproc unlimited |
下载ES
切换到普通用户,我这里使用work用户。
到官方找到最新版本,我下载的是5.2.2版本:
|
1 |
[work@1f2827106418 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.tar.gz |
我们搭建3个节点的分布式集群,它们均身兼master调度节点和data数据节点两个身份。
为此我们需要拷贝三份ES代码,虽然它们位于同一台服务器上,但是我要将按照分布式配置它们:
|
1 2 3 4 5 |
[work@24da9450e779 elasticsearch]$ cp -r elasticsearch-5.2.2/ elasticsearch0 [work@24da9450e779 elasticsearch]$ cp -r elasticsearch-5.2.2/ elasticsearch1 [work@24da9450e779 elasticsearch]$ cp -r elasticsearch-5.2.2/ elasticsearch2 [work@24da9450e779 elasticsearch]$ pwd /home/work/elasticsearch |
为它们创建各自的日志和数据目录,最终看起来是这样的:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[work@24da9450e779 elasticsearch]$ ll total 12 drwxr-xr-x 9 work work 4096 Mar 14 07:56 elasticsearch0 drwxr-xr-x 9 work work 4096 Mar 14 07:55 elasticsearch1 drwxr-xr-x 9 work work 4096 Mar 14 07:55 elasticsearch2 [work@24da9450e779 elasticsearch]$ mkdir -p elasticsearch0/logs elasticsearch0/data elasticsearch1/logs elasticsearch1/data elasticsearch2/logs elasticsearch2/data [work@24da9450e779 elasticsearch]$ ll elasticsearch0 total 224 drwxr-xr-x 2 work work 4096 Mar 14 07:53 bin drwxr-xr-x 2 work work 4096 Mar 14 07:53 config drwxrwxr-x 2 work work 4096 Mar 14 07:56 data drwxr-xr-x 2 work work 4096 Mar 14 07:53 lib -rw-r--r-- 1 work work 11358 Mar 14 07:53 LICENSE.txt drwxrwxr-x 2 work work 4096 Mar 14 07:55 logs drwxr-xr-x 12 work work 4096 Mar 14 07:53 modules -rw-r--r-- 1 work work 172700 Mar 14 07:53 NOTICE.txt drwxr-xr-x 2 work work 4096 Mar 14 07:53 plugins -rw-r--r-- 1 work work 9108 Mar 14 07:53 README.textile |
配置ES
现在我们首先配置elasticsearch0,而elasticsearch1和elasticsearch2可以拷贝它并稍作修改即可。
config/elasticsearch.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
cluster.name: nuomi-search node.name: nuomi-search-0 path.data: /home/work/elasticsearch/elasticsearch0/data path.logs: /home/work/elasticsearch/elasticsearch0/logs network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 discovery.zen.ping.unicast.hosts: ["172.17.0.2:9300", "172.17.0.2:9301", "172.17.0.2:9302"] discovery.zen.minimum_master_nodes: 2 |
- cluster.name:集群名,防止其他集群的ES误入本集群。
- node.name:确保每个ES节点有独一无二的名字,方便追查问题。
- path.data:数据存储目录。
- path.logs:日志存储目录。
- network.host:服务的监听IP地址。
- http.port:提供给客户端的RESTful Http端口。
- transport.tcp.port:ES节点之间互相通讯。
- discovery.zen.ping.unicast.hosts:启动后访问这些节点来加入集群
- discovery.zen.minimum_master_nodes:至少有2个备选master节点参与选举才能产生master。
关于ES的上述核心配置,可以通过这个博客学习与理解,我只说明一下比较难理解的配置项:
- discovery.zen.minimum_master_nodes:
- ES节点默认同时扮演备选master调度节点和data数据节点两个身份,我的集群里目前有3个备选master,它们同时也是data节点,真正的master通过它们3个选举产生。
- 如果后续扩充集群节点,应该明确指定它们仅扮演数据节点!
- 这个选项配置为2,表示master必须在至少2个备选master之间产生,这是为了防止master之间网络分割造成”脑裂”。
- 如果配置为1,那么不同网络分区内的备选master都认为自己是真正的master;
- 如果配置为3,那么一旦发生网络割裂,谁都无法成为master,均是不合理的;
- 如果配置为2,那么当2个备选master进入一个网络分区时,它们可以选出分区内的master,而另一个网络分区因为只有1个master,所以无法进行选举,因此可以防止”脑裂”。
- discovery.zen.ping.unicast.hosts:
- ES节点启动后必须加入到集群,新版的ES会访问配置的ES服务器列表并逐个尝试加入,因此保证列表内服务器至少有一个是可用的很重要。
- 这里配置成3个master节点,因为在我规划的集群里只有3个ES节点的身份是备选master,通常会保障它们的可用性远高于后续追加的普通data节点。
config/jvm.options
默认的ES配置分配了2G的jvm堆内存,由于我在虚拟机环境下测试内存有限,所以将其修改为512M即可:
|
1 2 3 4 5 |
# Xms represents the initial size of total heap space # Xmx represents the maximum size of total heap space -Xms512m -Xmx512m |
至此,你可以把上述2个配置文件拷贝到其他2个ES目录中,并对其他2个配置文件稍作修改,最终结果如下:
elasticsearch1
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
cluster.name: nuomi-search node.name: nuomi-search-1 path.data: /home/work/elasticsearch/elasticsearch1/data path.logs: /home/work/elasticsearch/elasticsearch1/logs network.host: 0.0.0.0 http.port: 9201 transport.tcp.port: 9301 discovery.zen.ping.unicast.hosts: ["172.17.0.2:9300", "172.17.0.2:9301", "172.17.0.2:9302"] discovery.zen.minimum_master_nodes: 2 |
elasticsearch2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
cluster.name: nuomi-search node.name: nuomi-search-2 path.data: /home/work/elasticsearch/elasticsearch2/data path.logs: /home/work/elasticsearch/elasticsearch2/logs network.host: 0.0.0.0 http.port: 9202 transport.tcp.port: 9302 discovery.zen.ping.unicast.hosts: ["172.17.0.2:9300", "172.17.0.2:9301", "172.17.0.2:9302"] discovery.zen.minimum_master_nodes: 2 |
安装中文分词
我们使用这个开源项目实现中文分词,它是ES的一个插件。
首先下载代码:
|
1 |
git clone https://github.com/medcl/elasticsearch-analysis-ik.git |
之后切换到对应ES版本的release分支,我的ES是5.2.2版本,因此:
|
1 |
git checkout tags/v5.2.2 |
现在用mvn编译这个插件:
|
1 2 |
export JAVA_HOME=/usr /usr/local/apache-maven-3.3.9/bin/mvn package |
我的编译产物存储在:
|
1 |
/home/work/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-5.2.2.zip |
将其解压到3个ES目录的插件目录下:
|
1 2 3 |
unzip /home/work/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-5.2.2.zip -d /home/work/elasticsearch/elasticsearch0/plugins/ik unzip /home/work/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-5.2.2.zip -d /home/work/elasticsearch/elasticsearch1/plugins/ik unzip /home/work/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-5.2.2.zip -d /home/work/elasticsearch/elasticsearch2/plugins/ik |
启动ES
分别进去3个ES目录并启动它们:
|
1 2 3 |
[work@9a291b37ca04 elasticsearch0]$ bin/elasticsearch -d [work@9a291b37ca04 elasticsearch1]$ bin/elasticsearch -d [work@9a291b37ca04 elasticsearch2]$ bin/elasticsearch -d |
验证ES
访问ES的健康状态接口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[work@9a291b37ca04 elasticsearch0]$ curl http://localhost:9200/_cluster/health?pretty { "cluster_name" : "nuomi-search", "status" : "green", "timed_out" : false, "number_of_nodes" : 3, "number_of_data_nodes" : 3, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 } |
返回结果表明nuomi-search集群的状态是green(健康的),一共有3个节点,其中3个作为datanodes。
确认IK分词插件已经正常加载:
|
1 2 3 4 5 6 7 8 9 10 |
[work@9a291b37ca04 elasticsearch0]$ curl http://localhost:9200/_nodes?pretty "plugins" : [ { "name" : "analysis-ik", "version" : "5.2.2", "description" : "IK Analyzer for Elasticsearch", "classname" : "org.elasticsearch.plugin.analysis.ik.AnalysisIkPlugin" } ], |
安装PHP客户端
用命令行CURL访问ES服务太过于麻烦,为了更贴近生产环境,我会使用PHP的ES客户端来实现功能。
因此,我们需要先安装php(ES的5.x版本客户端要求php版本为5.6或者7.0):
|
1 |
yum install php70w |
之后我们需要安装composer,目的是通过它安装ES客户端,先创建一个项目目录叫做nuomi-search:
|
1 2 |
[work@9a291b37ca04 nuomi-search]$ pwd /home/work/nuomi-search |
在目录内下载composer主程序(如果你不懂composer并且感兴趣,可以看我的这篇博客):
|
1 |
curl -sS https://getcomposer.org/installer | php |
为composer替换国内镜像:
|
1 |
composer config repo.packagist composer https://packagist.phpcomposer.com |
现在安装ES官方的PHP客户端(官方文档):
|
1 |
php composer.phar require elasticsearch/elasticsearch:~5.0 |
安装完成后应该可以看到如下目录结构:
|
1 2 3 4 5 6 |
[work@9a291b37ca04 nuomi-search]$ ll total 1816 -rw-rw-r-- 1 work work 73 Mar 17 03:56 composer.json -rw-rw-r-- 1 work work 8961 Mar 17 03:57 composer.lock -rwxr-xr-x 1 work work 1836198 Mar 17 03:51 composer.phar drwxrwxr-x 7 work work 4096 Mar 17 04:48 vendor |
我们创建测试用的php文件,通过客户端连接到我们的ES集群,查看集群健康状况以及当前有哪些数据库(index):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<?php require_once __DIR__ . "/vendor/autoload.php"; // 客户端 $client = Elasticsearch\ClientBuilder::fromConfig([ 'hosts' => ['localhost:9200', 'localhost:9201', 'localhost:9203'], // 最好在为ES集群搭建Haproxy反向代理 'retries' => 2 ]); // 集群状态相关方法 $cluster = $client->cluster(); print_r($cluster->health()); // 集群健康状况 // 索引管理相关方法 $indices = $client->indices(); print_r($indices->stats()); // index+type列表 |
执行程序,应该可以看到如下输出:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
[work@df6c675da97e nuomi-search]$ php main.php Array ( [cluster_name] => nuomi-search [status] => green [timed_out] => [number_of_nodes] => 3 [number_of_data_nodes] => 3 [active_primary_shards] => 0 [active_shards] => 0 [relocating_shards] => 0 [initializing_shards] => 0 [unassigned_shards] => 0 [delayed_unassigned_shards] => 0 [number_of_pending_tasks] => 0 [number_of_in_flight_fetch] => 0 [task_max_waiting_in_queue_millis] => 0 [active_shards_percent_as_number] => 100 ) Array ( [_shards] => Array ( [total] => 0 [successful] => 0 [failed] => 0 ) [_all] => Array ( [primaries] => Array ( ) [total] => Array ( ) ) [indices] => Array ( ) ) |
至此,ES服务与PHP客户端都搭建完成,本文最后将分析一下需求。
需求分析
经过对”糯米美食”频道的观察,发现它的搜索功能有4个核心能力:
- 搜索”肯德基”,会列出所有的肯德基”商铺“。
- 搜索”鱼香肉丝”,会列出所有售卖”鱼香肉丝”的”商铺“。
- 在搜索的基础上,可以按距离筛选一定范围内的”商铺“。
- 在搜索的基础上,”商铺“可以按照评分/距离…等进行排序。
在搜索方面可以得出一个结论:用户搜索的关键字,无论其含义是一个”商铺”名称还是一个”商品”名称,最终都应该返回相关联的”商铺”列表。
很明显,”商铺”和”商品”之间存在一个关联关系,1个”商铺”有N个”商品”,并且搜索时应该能基于”商品”进行筛选得到满足条件的”商铺”,类似于mysql中的一次JOIN+WHERE。
那么,在ES中有2种功能都是支持这种关联查询的,它们分别是:
- 嵌套关系(Nested),它的优缺点如下:
- 优点:
- 对于主要实体(如商铺)加上有限数量的紧密相关实体(如商品)来说,可以很快的根据商品信息筛选出店铺信息。
- 可以同时基于商铺与商铺的商品两部分信息进行筛选。
- 缺点
- 增删改任意嵌套的商品,需要重新索引整个商铺的数据。
- 总是返回商铺与其所有商品的完整数据。
- 优点:
- 父子关系(Parent-Child)
- 优点:
- 修改店铺数据,无需重新索引商品数据。
- 增删改查商品数据,无需重新索引商铺的数据。(这对于商品数量庞大的场景很重要)
- 缺点:
- 比嵌套查询慢5-10倍。
- 商品检索时关联的商铺_id会放在内存里计算,有内存限制。
- 只能基于商品信息筛选出商铺,或者基于商铺信息筛选出商品。(无法做到这样的效果:基于商铺与其售卖的商品共同筛选出店铺)
- 优点:
看完各自的优缺点后,我们知道ES也不是万能药,必然有其技术限制,因此怎么将自己的业务场景转换到ES的存储上来就是我们必须考虑的问题了。
ES不是Mysql,我们知道Mysql的表之间彼此JOIN查询是很寻常的事情;但是ES作为一个检索系统更强调扁平化,并不强力的支持JOIN类查询,我们应该更多的利用数据冗余的思路将需要JOIN的数据打平(冗余)到一个表中,这样就可以基于一个表的检索完成本来需要JOIN多个表的需求了。
对于上述的嵌套关系(Nested)来讲,其实就是一种扁平化思路,商铺与属于商铺的商品将被存储在同一个表(type)中,可以很方便基于商铺信息与所属的商品信息完成搜索。
对于上述的父子关系(Parent-Child)来讲,其实就是一种JOIN思路,店铺和商品直接隔离在两个表(type)中各自独立索引,同时ES会在商品表中维护一个_parent字段指向所属的商铺记录,从而满足一些类似JOIN的查询任务。
那么,我们要模仿的糯米检索应该使用哪种技术呢?
商品数量不是很多,增删改查的频率不是很高,同时希望同时按照商铺名称和商品名称完成筛选,似乎嵌套关系(Nested)更加适合,但是父子关系就一定不行了吗?
当然不是,借助数据冗余的思路,我们完全可以把商铺的各种信息(例如:商铺名称,商铺评分,商铺人均消费…等)全部冗余到每个商品记录中去,这样就可以先对商品表进行”商铺名称”+”商品名称”的一次检索,找出最匹配的若干”商铺名称”,之后再去”商铺表”将这些”商铺名称”对应的详细”商铺”信息取回来即可。不过缺点也很明显,每次商铺信息变动,要对属于它的每个商品进行一次冗余信息更新,这就是扁平化的代价。
实践环节
简化后的糯米检索包含如下2类数据:
- 商铺:
- 商铺名称
- 商铺图片
- 商铺类型
- 用户评分
- 人均价格
- 地理坐标
- 商品:
- 商品名称
- 商品图片
- 商品类型
- 商品价格
- 已售数量
为了更顺畅的阅读后面的博客,建议你先学习一遍官方文档。
具体内容未来请见:《elasticsearch之实例篇》
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

One thought on “elasticsearch之搭建篇”