tensorflow2.0 – 端到端的wide&deep模型训练
本文将基于泰坦尼克数据集,展现tensorflow2.0实现wide&deep模型训练的整个工程化流程,内容包括:
- 生成tfrecords格式的训练样本文件
- 使用keras构建wide&deep模型结构
- 利用dataset API加载tfrecords训练样本
- 训练并保存wide&deep模型文件
本文采用单机模式完成训练,在下一篇博客我将演示如何利用spark实现海量训练样本场景下的分布式训练。
本文代码:https://github.com/owenliang/tf2-widedeep,你应该对tensorflow有一定了解,我不会对基础知识做过多解释。
csv原始数据
在data目录下,我下载了泰坦尼克的数据集:
- train.csv:训练文件,Survived列是训练目标(0死亡,1生还)
- test.csv:测试文件,没有Survived列,模型预测结果只能提交到kaggle来进行准确率判定。
train.csv格式:
|
1 2 3 4 |
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked 1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S 2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C 3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S |
原始特征可以从2个视角划分:
- 数字、字符串。
- 类别、连续值。
train流程
先从整体视角,看一下train.py是如何完成模型训练的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import pandas as pd import tensorflow as tf from dataset import dataframe_to_tfrecords, dataset_from_tfrecords from model import build_model import time def train_model(model, dataset): version = int(time.time()) tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir='./tensorboard/{}'.format(version), histogram_freq=1) # tensorboard --logdir=./tensorboard model.fit(dataset.batch(100).shuffle(100), epochs=2000, callbacks=[tensorboard_callback]) model.save('model/{}'.format(version), save_format='tf', include_optimizer=False) # two optimizer in wide&deep can not be serialized, excluding optimizer is ok for prediction # csv转tfrecords文件 dataframe_to_tfrecords(pd.read_csv('../data/train.csv'), 'train.tfrecords', include_outputs=True) # 加载tfrecords文件为dataset dataset = dataset_from_tfrecords('train.tfrecords', include_outputs=True) # 创建wide&deep model wide_deep_model = build_model() # 训练模型 train_model(wide_deep_model, dataset) |
为了训练得到模型文件,整体分为4步:
- 预处理csv文件,生成tfrecords格式的训练文件。
- 将磁盘上的tfrecords文件加载为dataset对象。
- 构建wide&deep模型对象。
- 训练模型,保存模型文件。
仅看本文件的话,train_model负责训练wide&deep模型:
- 生成模型版本号。
- 创建TensorBoard的callback,这样训练过程将被trace,后续可以打开tensorboard可视化的训练过程和模型结构。
- 传入dataset完成fit,合理调整dataset的batch size,传入训练轮数epoch。
- 将keras模型保存为saved_model文件格式,后续可以从文件恢复出模型或者直接用tensorflow-serving加载提供GRPC服务。
save模型时include_optimizer=False表示不保存优化器,优化器是训练时用来梯度下降的,训练好的模型后续用作线上推断时是不需要使用优化器的。但这并不是设为False的理由,真正理由是我们的wide&deep模型为wide和deep两部分采用了各自的优化器,现有tensorflow还没有兼容1个model包含多个optimizer的导出,索性就不导出。
定义feature
打开config.py,它定义了wide&deep模型的原始输入与特征工程:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
from collections import OrderedDict model_spec = { 'inputs': { 'Pclass': {'default': -1, 'type': 'int'}, 'Sex': {'default': '', 'type': 'str'}, 'Age': {'default': -1, 'type': 'int'}, 'SibSp': {'default': -1, 'type': 'int'}, 'Parch': {'default': -1, 'type': 'int'}, 'Fare': {'default': -1, 'type': 'float'}, 'Embarked': {'default': '', 'type': 'str'}, 'Ticket': {'default': '', 'type': 'str'} }, 'outputs': { 'Survived': {'default': -1, 'type': 'int'}, }, 'feature_columns': { # 连续值, 只进入deep 'num': [ {'feature': 'Age'}, {'feature': 'SibSp'}, {'feature': 'Parch'}, {'feature': 'Fare'} ], # 类别,onehot进入wide完成记忆,embedding进入deep完成扩展 'cate': [ {'feature': 'Sex', 'vocab': ['male', 'female'], 'embedding': 10}, {'feature': 'Pclass', 'vocab': [1, 2, 3], 'embedding': 10}, {'feature': 'Embarked', 'vocab': ['S', 'C', 'Q'], 'embedding': 10}, ], 'hash': [ {'feature': 'Ticket', 'bucket': 10, 'embedding': 10} ], 'bucket': [ {'feature': 'Age', 'boundaries': [10, 20, 30, 40, 50, 60, 70, 80, 90], 'embedding': 10} ], # 人工交叉:进入wide 'cross': [ {'feature': ['Age#bucket', 'Sex#cate'], 'bucket': 10} ] } } |
它围绕wide&deep的输入输出进行定义,分为3部分,对于后续构建模型与训练数据生成都至关重要:
- inputs:模型原始输入,需要定义它们的name,type,default value,对生成tfrecords文件非常重要。
- outputs:模型输出。
- feature_columns:模型中的”特征工程layer”,它对inputs进行各种特征工程,最终输入到model:
- num:连续值,例如Fare票价,只会喂入deep部分,不需要做预处理(也可以标准化)。
- cate:离散值(类别,但是枚举有限),例如Sex性别可选值为male和female,它会被onehot后送入wide部分,embedding后送入deep部分。
- hash:离散值(类别,但是枚举无限),例如Ticket票据是无穷枚举的字符串,可以通过hash算法变为有限大小的整数类别,同样onehot送入wide,embedding送入deep。
- bucket:连续值转离散值,例如Age进行分桶得到桶编号,然后onehot送入wide,embedding送入deep。
- cross:将多个类别特征交叉相乘再哈希得到新离散值,然后onehot送入wide,这属于人工经验特征交叉,依靠wide强化模型记忆。
关于wide&deep的原理,你必须读一下这篇知乎:https://www.zhihu.com/question/23194692/answer/1629971674?utm_source=hot_content_share&utm_medium=all
根据wide&deep理念,num连续值只会喂入deep层,cate/hash/bucket生成的类别可以同时喂入wide与deep,只不过wide采用one-hot侧重记忆性,deep采用embedding侧重扩展性,而cross属于人工特征交叉更侧重wide的记忆性,所以cross只onehot输入到wide部分即可。
生成tfrecords文件
打开dataset.py,它的第一个函数负责将csv文件转换成tfrecords文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import pandas as pd import tensorflow as tf from config import model_spec from copy import deepcopy def dataframe_to_tfrecords(df, tfrecords_filename, include_outputs=False): all_feature_spec = deepcopy(model_spec['inputs']) if include_outputs: all_feature_spec.update(model_spec['outputs']) with tf.io.TFRecordWriter(tfrecords_filename, 'GZIP') as tfrecords_writer: for _, row in df.iterrows(): feature_dict = {} for feature_name, feature_spec in all_feature_spec.items(): feature_value = row[feature_name] if feature_value is None or pd.isna(feature_value): feature_value = feature_spec['default'] if feature_spec['type'] == 'int': feature = tf.train.Feature(int64_list=tf.train.Int64List(value=[int(feature_value)])) elif feature_spec['type'] == 'float': feature = tf.train.Feature(float_list=tf.train.FloatList(value=[float(feature_value)])) elif feature_spec['type'] == 'str': feature = tf.train.Feature( bytes_list=tf.train.BytesList(value=[str(feature_value).encode('utf-8')])) feature_dict[feature_name] = feature example = tf.train.Example(features=tf.train.Features(feature=feature_dict)) tfrecords_writer.write(example.SerializeToString()) |
首先引入config.py中的model_spec定义,如果是训练数据则include_outputs=True,即把目标值Survived也写入tfrecords文件,因为训练时需要用到目标值。
打开TFRecordWriter文件(GZIP压缩),逐行迭代pandas dataframe的每一行样本,将inputs+outputs的各个列作为若干feature对象,如果dataframe对应值缺失则用default值填充,这样每一行就会生成一个tf.train.Example样本对象,其本质是一个dict,其中key是特征名,value是特征值,被序列化写入到tfrecords文件中。
所以tfrecords文件就是一行一行的样本,每一行样本又是KV结构的若干特征。
加载tfrecords为dataset
tfrecords是一种文件格式,用来存储训练或者预测样本。
dataset是一种数据集加载API,可以支持从tfrecords磁盘文件加载数据集,而不必全内存加载数据集。
为了训练,我们用dataset API加载tfrecords文件(dataset.py文件):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
def dataset_from_tfrecords(tfrecords_pattern, include_outputs=False): all_feature_spec = deepcopy(model_spec['inputs']) if include_outputs: all_feature_spec.update(model_spec['outputs']) feature_dict = {} for feature_name, feature_spec in all_feature_spec.items(): if feature_spec['type'] == 'int': feature = tf.io.FixedLenFeature((), tf.int64) elif feature_spec['type'] == 'float': feature = tf.io.FixedLenFeature((), tf.float32) elif feature_spec['type'] == 'str': feature = tf.io.FixedLenFeature((), tf.string) feature_dict[feature_name] = feature def parse_func(s): inputs = tf.io.parse_single_example(s, feature_dict) outputs = [] if include_outputs: for output_name in model_spec['outputs']: outputs.append(inputs[output_name]) inputs.pop(output_name) if include_outputs: return inputs, outputs return inputs dataset = tf.data.Dataset.list_files(tfrecords_pattern).interleave( lambda filename: tf.data.TFRecordDataset(filename, compression_type='GZIP').map(parse_func) ) return dataset |
最终return的dataset是这样加工而来的:
- 利用tf.data.Dataset.list_files扫描目录下的若干tfrecords文件名。
- 利用interleave将每个tfrecord文件名转换成一个dataset数据集对象。
- 利用map逐行反序列化example样本对象。
如果tfrecords_pattern通配到N个tfrecords文件,那么return的dataset对象实际内含N个dataset子对象分别对应N个文件,它会自动在这些文件之间轮转加载数据。
在map回调函数parse_func中,为了解析tfrecords中每一行序列化的example,我们必须根据model_spec定义的name和type来定义一个feature_dict描述字典,然后调用parse_single_example完成反序列化。如果是训练数据集,我们还需要将Survived列挑出来,最终返回元组(inputs特征KV字典, output目标值列表),这才是模型训练所需要的内存数据格式。
构建模型
打开model.py,它负责构建模型结构:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
def build_model(): linear_features, dnn_features = _build_feature_columns() # wide linear_input_layer = build_input_layer() linear_feature_layer = tf.keras.layers.DenseFeatures(linear_features) linear_dense_layer1 = tf.keras.layers.Dense(units=1) output = linear_feature_layer(linear_input_layer) output = linear_dense_layer1(output) linear_model = tf.keras.Model(inputs=list(linear_input_layer.values()), outputs=[output]) linear_optimizer = tf.keras.optimizers.Ftrl(l1_regularization_strength=0.5) # deep dnn_feature_layer = tf.keras.layers.DenseFeatures(dnn_features) dnn_norm_layer = tf.keras.layers.BatchNormalization() # important for deep dnn_dense_layer1 = tf.keras.layers.Dense(units=128, activation='relu') dnn_dense_layer2 = tf.keras.layers.Dense(units=1) dnn_input_layer = build_input_layer() output = dnn_feature_layer(dnn_input_layer) output = dnn_norm_layer(output) # this will break the tensorboard graph because of unfixed bug output = dnn_dense_layer1(output) output = dnn_dense_layer2(output) dnn_model = tf.keras.Model(inputs=list(dnn_input_layer.values()), outputs=[output]) dnn_optimizer = tf.keras.optimizers.Adagrad() # wide&deep wide_deep_model = tf.keras.experimental.WideDeepModel(linear_model, dnn_model, activation='sigmoid') wide_deep_model.compile(optimizer=[linear_optimizer,dnn_optimizer], loss=tf.keras.losses.BinaryCrossentropy(), metrics=tf.keras.metrics.BinaryAccuracy()) return wide_deep_model |
我们使用keras的实验性API WideDeepModel,它要求传入wide和deep两个子模型,以及各自的optimizer,整个Wide&deep模型就一路输出目标值,采用Binary交叉熵计算loss,使用BinaryAcc评估准确率。
根据wide&deep实现原理,wide就是一层线性函数并且采用带L2正则的Ftrl优化器做梯度下降,这样可以令wide部分的权重系数更加稀疏易于保存,deep部分是普通的深层网络,最终只有1个神经元的输出与wide部分做add求和操作得到1个数字,再经过sigmoid激活后作为最终wide&deep模型的概率输出。
对于wide和deep来说,大部分的inputs都会使用,因此它们采用一样的input layer,但是wide和deep的特征工程不一样(wide输入onehot,deep输入embedding),所以它们有各自不同feature column层做特征预处理。
input layer负责接受模型的输入,因为我们的输入的样本是KV字典风格的Example,因此input layer也遵循相同格式生成:
|
1 2 3 4 5 6 7 8 9 10 11 |
def build_input_layer(): input_layer = {} for input_name, input_spec in model_spec['inputs'].items(): if input_spec['type'] == 'int': input_feature = tf.keras.Input((), name=input_name, dtype=tf.int64) elif input_spec['type'] == 'float': input_feature = tf.keras.Input((), name=input_name, dtype=tf.float32) elif input_spec['type'] == 'str': input_feature = tf.keras.Input((), name=input_name, dtype=tf.string) input_layer[input_name] = input_feature return input_layer |
根据model_spec生成KV风格的Input()映射关系即可,实际生产中我们都是像这样按KV风格传入若干特征的。
最终就是feature column特征预处理层的逻辑:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
def _build_feature_columns(): num_feature_arr = [] onehot_feature_arr = [] embedding_feature_arr = [] feature_column_spec = model_spec['feature_columns'] base_cate_map = {} for num_feature in feature_column_spec['num']: num_feature_arr.append(tf.feature_column.numeric_column(num_feature['feature'])) for cate_feature in feature_column_spec['cate']: base_cate_map[cate_feature['feature'] + '#cate'] = (tf.feature_column.categorical_column_with_vocabulary_list(cate_feature['feature'], cate_feature['vocab']), cate_feature) for hash_feature in feature_column_spec['hash']: base_cate_map[hash_feature['feature'] + '#hash'] = (tf.feature_column.categorical_column_with_hash_bucket(hash_feature['feature'], hash_feature['bucket']), hash_feature) for bucket_feature in feature_column_spec['bucket']: num_feature = tf.feature_column.numeric_column(bucket_feature['feature']) base_cate_map[bucket_feature['feature'] + '#bucket'] = (tf.feature_column.bucketized_column(num_feature, boundaries=bucket_feature['boundaries']), bucket_feature) cross_cate_map = {} for cross_feature in feature_column_spec['cross']: cols = [] for col_name in cross_feature['feature']: column, spec = base_cate_map[col_name] cols.append(column) cross_cate_map['&'.join(cross_feature['feature']) + '#cross'] = tf.feature_column.crossed_column(cols, hash_bucket_size=cross_feature['bucket']) for cate_name in base_cate_map: column, spec = base_cate_map[cate_name] onehot_feature_arr.append(tf.feature_column.indicator_column(column)) embedding_feature_arr.append(tf.feature_column.embedding_column(column, spec['embedding'])) for cross_cate_name in cross_cate_map: cross_feature_col = cross_cate_map[cross_cate_name] onehot_feature_arr.append(tf.feature_column.indicator_column(cross_feature_col)) return onehot_feature_arr, num_feature_arr + embedding_feature_arr |
feature column将特征预处理纳入了模型结构中,因此线上推断时客户端不需要做特征预处理,比如Sex的male与female直接按字符串传入即可。
根据model_spec的feature_column定义,我们生成:
- num_feature_arr:连续值,给deep用。
- onehot_feature_arr:独热编码,给wide用,包含:枚举的类别、hash取模产生的类别、连续值经过bucket分桶产生的类别,或者将这几个类别cross交叉产生的新类别。
- embedding_feature_arr:嵌入稠密向量,给deep用,包含:枚举的类别、hash取模产生的类别、连续值经过bucket分桶产生的类别。
indicator_column用于生成onthot向量,embedding_column用于生成embedding向量。
函数最后返回wide部分使用的特征工程,与deep部分使用的特征工程。
模型predict
查看predict.py,它加载keras model进行预测:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import pandas as pd import numpy as np import tensorflow as tf from dataset import dataframe_to_tfrecords, dataset_from_tfrecords # 预测 def model_predict(model, dataset, df ): dataset = dataset.batch(100) pred_y = [] for x in dataset: y = wide_deep_model(x) y = np.where(y.numpy()[:, 0]>0.5, 1, 0) pred_y.extend(y) df['Survived'] = pred_y # csv转tfrecords文件 df = pd.read_csv('../data/test.csv') dataframe_to_tfrecords(df, 'test.tfrecords', include_outputs=False) # 加载tfrecords文件为dataset dataset = dataset_from_tfrecords('test.tfrecords', include_outputs=False) # 加载模型 wide_deep_model = tf.keras.models.load_model('model/1608529479') # 使用模型 model_predict(wide_deep_model, dataset, df) # 保存预测结果 df[['PassengerId','Survived']].to_csv('./result.csv', index=False, header=True) |
这里将test.csv转成tfrecords文件,然后再用dataset加载它,这时候里面不包含目标值Survived。
模型通过load_model加载对应版本,注意keras模型经过load后就不再具备predict方法了,只能当作函数调用。
模型输出值是对目标值的推断,因此我们判断>0.5就是Survived=1生还,否则Survied=0死亡,最后将passengerId和预测Survived保存到csv中。
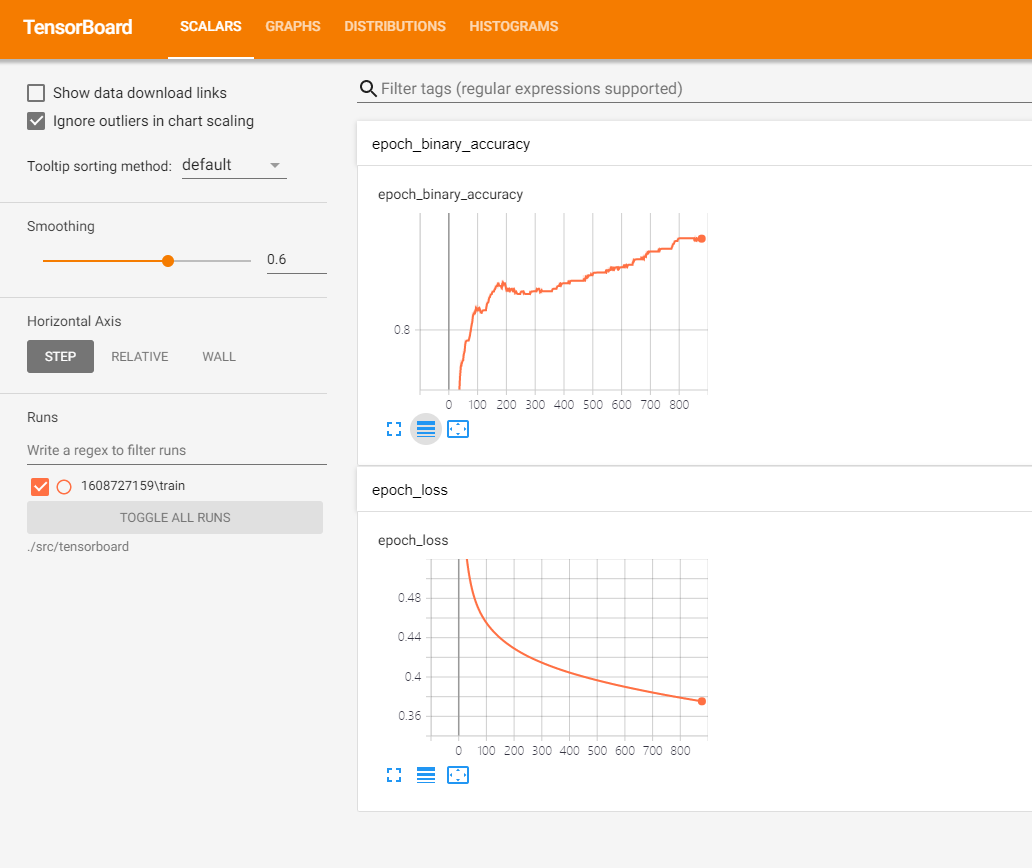
查看tensorboard
我们每次训练都会在tensorboard目录下生成一个版本号的子目录,我们可以用tensorboard –logdir指向tensorboard目录(注意不是某个版本的子目录),从而可以选择任意模型版本查看其训练过程和网络结构。(注:tensorboard可以在模型训练期间打开,通过定时刷新实时观察模型进展)
tensorboard –logdir=./src/tensorboard
查看随着epoch增长,准确率和损失的变化。
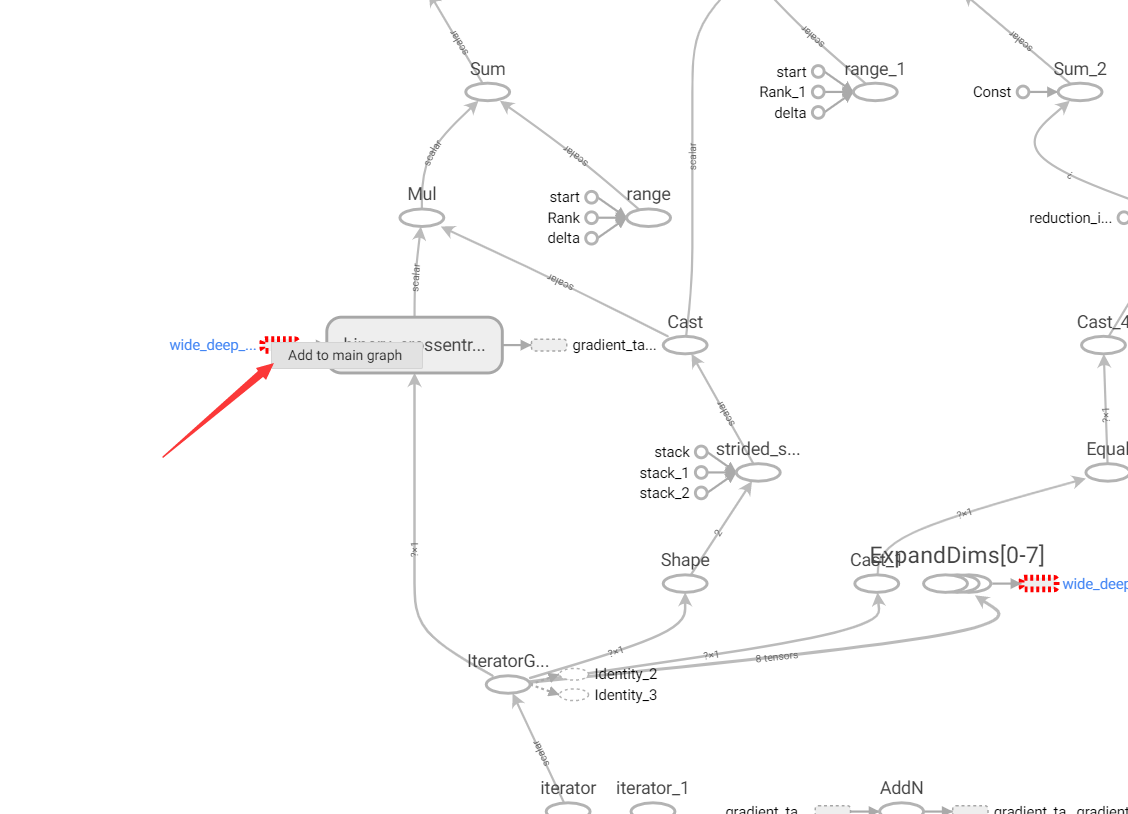
查看模型结构(我这里wide&deep模型部分被折叠了,需要右键add to main graph):
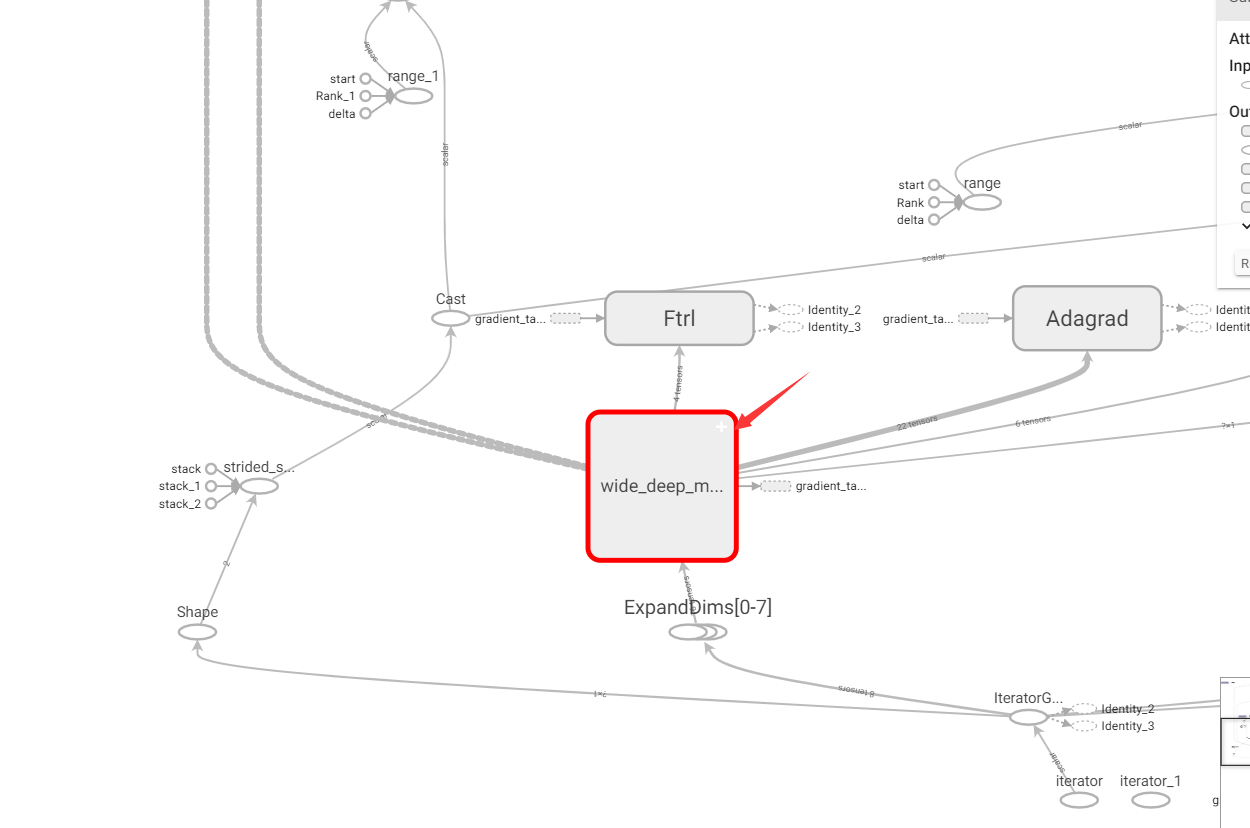
然后双击放大wide&deep模型:
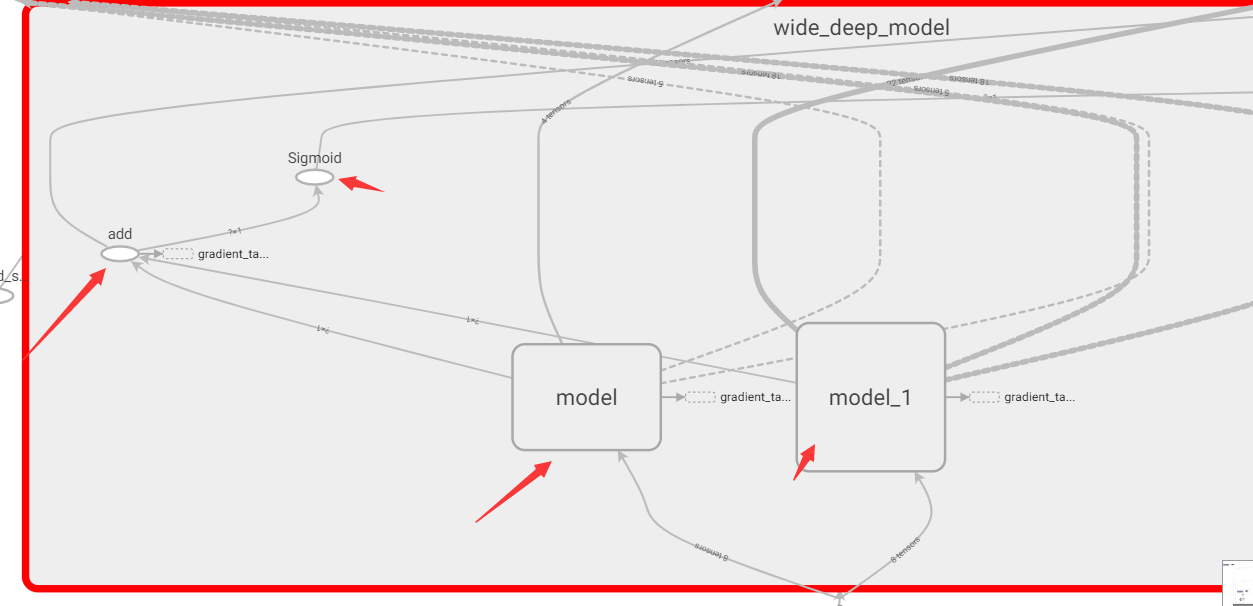
可以看到wide部分和deep部分,两路输出add后经过sigmoid:
双击展开左侧wide部分model,可以看到其内部是由dense_feature特征工程层+单神经元的dense层构成:
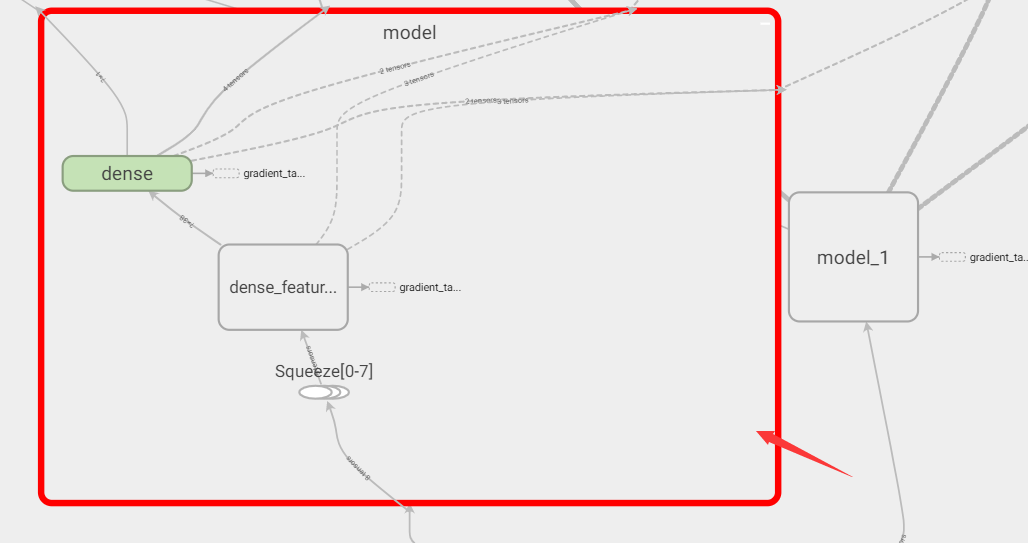
双击展开dense_feature层,我们理应看到feature column带来的各种one-hot向量:
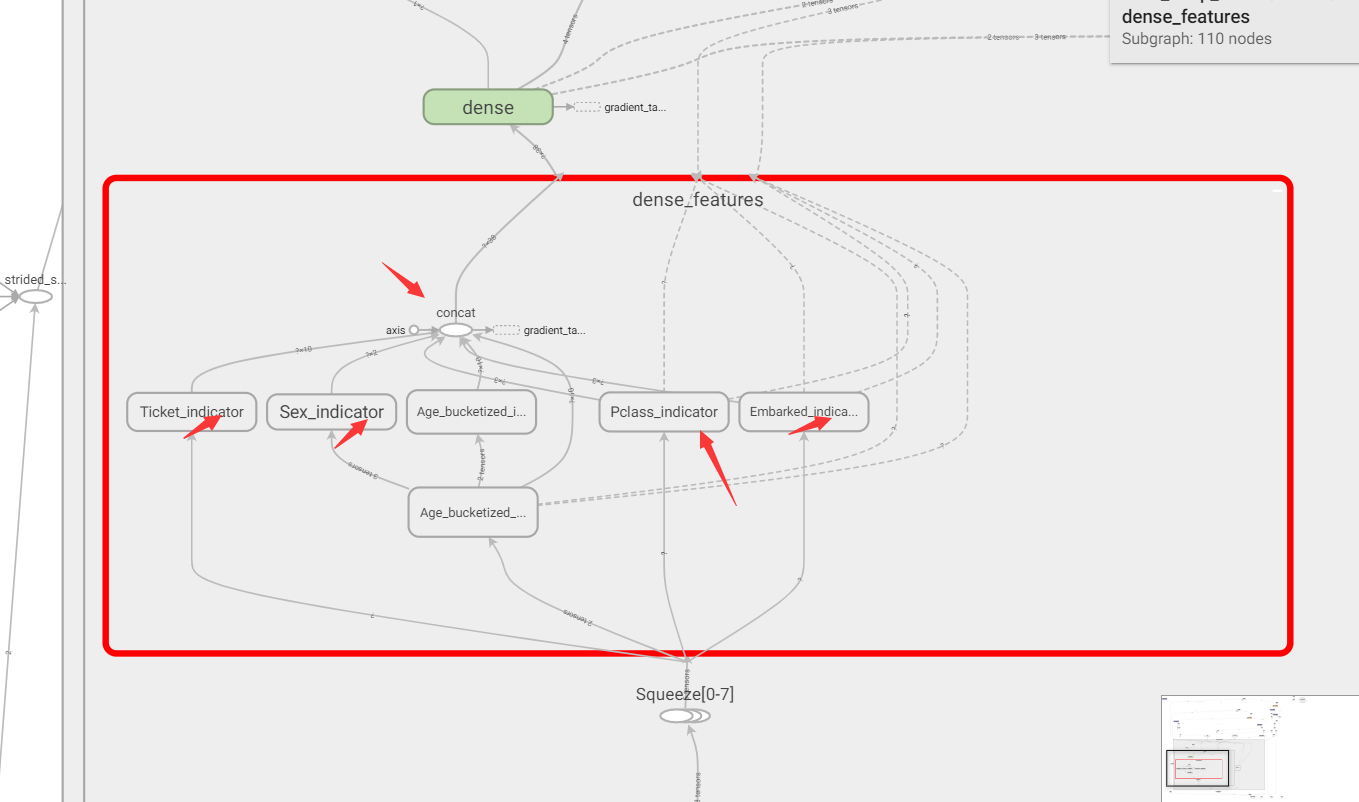
可以看到输入到dense feature层经过各种Indicator做onehot后重新concat到了一个宽向量,再送入后续的dense层,这就是dense feature layer的原理了。
再回头看一下deep层:
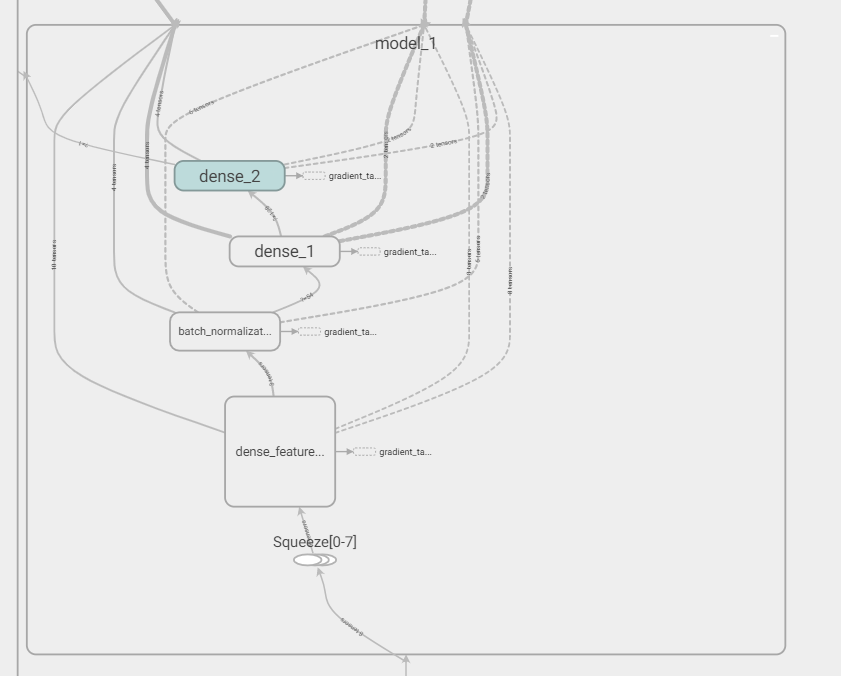
可以看出原始inputs经过dense feature层特征工程后(都是embedding),经过batch norm标准化(为了连续值),再经过2层神经网络。
双击展开dense feature层:
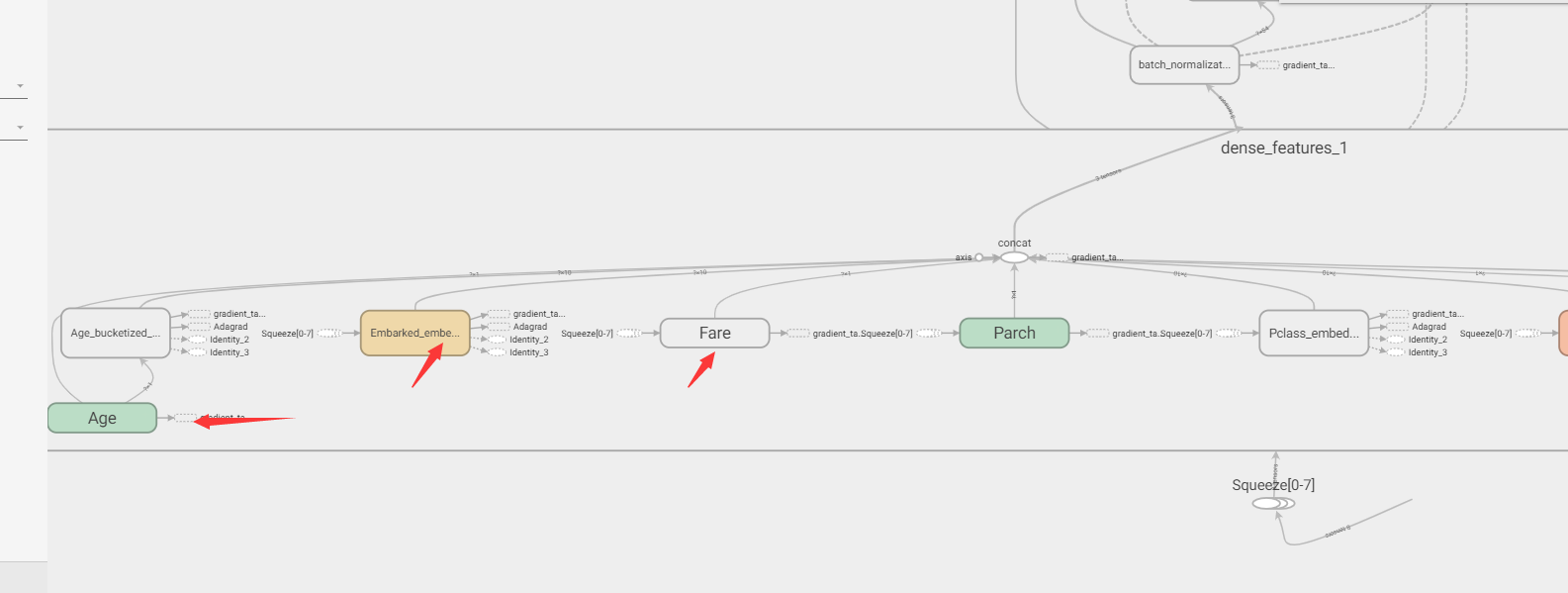
最左侧是连续值Age经过分桶后得到离散类别,再embedding。
左2是枚举类别直接embedding,左3是连续值。
结束语
tensorflow2.x的keras模型不支持optional input,也就是说调用模型的时候必须保证传所有的特征,如果没有就传一个自定义的默认值(比如-1),训练数据也遵循同样的默认值即可保证正确。
目前来看,tfrecords+dataset+feature column+saved_model+tensorboard是tensorflow端到端工程化的必备工具链,希望本文对大家有所启发,有任何问题欢迎留言交流。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
1