pyspark – 基于word2vec+LSH实现相似内容查找
本文基于kaggle豆瓣影评数据集,演示如何利用pyspark的word2vec和LSH库实现相似影评的计算,同样的方式可以用于相似内容匹配,例如:在海量文章中检测存在抄袭的文章等类似需求。
代码地址:https://github.com/owenliang/douban-comments-similarity,豆瓣影评数据集加载如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 初始化jieba jieba.initialize() # spark会话(local[*]表示使用所有cpu) spark = SparkSession.builder.master('local[*]').config("spark.driver.memory", "64g").appName('douban').getOrCreate() # 加载豆瓣数据集 douban_df = spark.read.csv('./DMSC.csv', header=True) """ +---+--------------------+-------------+----------+------+----------------+----------+----+------------------------------------+----+ | ID| Movie_Name_EN|Movie_Name_CN|Crawl_Date|Number| Username| Date|Star| Comment|Like| +---+--------------------+-------------+----------+------+----------------+----------+----+------------------------------------+----+ | 0|Avengers Age of U...| 复仇者联盟2|2017-01-22| 1| 然潘|2015-05-13| 3| 连奥创都知道整容要去韩国。|2404| | 1|Avengers Age of U...| 复仇者联盟2|2017-01-22| 2| 更深的白色|2015-04-24| 2| 非常失望,剧本完全敷衍了事,主线...|1231| | 2|Avengers Age of U...| 复仇者联盟2|2017-01-22| 3| 有意识的贱民|2015-04-26| 2| 2015年度最失望作品。以为面面...|1052| |
每行是1条影评,其关联了电影标题、影评作者、评论内容等信息,我们基于该数据集利用机器学习算法挖掘出Comment内容相似的影评。
第1步:jieba分词
下面代码对所有影评Comment进行jieba分词:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 对评论进行分词 remove_chars_pattern = re.compile('[·’!"#$%&\'()#!()*+,-./:;<=>?@,:?★、….>【】[]《》?“”‘’[\\]^_`{|}~]+') def jieba_f(line): global remove_chars_pattern try: words = [remove_chars_pattern.sub('', word) for word in jieba.lcut(line, cut_all=False)] return words except: return [] jieba_udf = udf(jieba_f, ArrayType(StringType())) douban_df = douban_df.withColumn('Words', jieba_udf(col('Comment'))) """ +---+--------------------+-------------+----------+------+----------------+----------+----+------------------------------------+----+----------------------------+ | ID| Movie_Name_EN|Movie_Name_CN|Crawl_Date|Number| Username| Date|Star| Comment|Like| Words| +---+--------------------+-------------+----------+------+----------------+----------+----+------------------------------------+----+----------------------------+ | 0|Avengers Age of U...| 复仇者联盟2|2017-01-22| 1| 然潘|2015-05-13| 3| 连奥创都知道整容要去韩国。|2404| [ , 连, 奥创, 都, 知道,...| | 1|Avengers Age of U...| 复仇者联盟2|2017-01-22| 2| 更深的白色|2015-04-24| 2| 非常失望,剧本完全敷衍了事,主线...|1231| [ , 非常, 失望, ,, 剧本...| | 2|Avengers Age of U...| 复仇者联盟2|2017-01-22| 3| 有意识的贱民|2015-04-26| 2| 2015年度最失望作品。以为面面...|1052| [ , 2015, 年度, 最, ...| | 3|Avengers Age of U...| 复仇者联盟2|2017-01-22| 4| 不老的李大爷耶|2015-04-23| 4| 《铁人2》中勾引钢铁侠,《妇联1...|1045| [ , 《, 铁人, 2, 》, ...| """ |
分词采用udf自定义函数对Comment列执行分布式计算,利用jieba库中文分词,并擦除掉标点符号,最终生成分词列表到Words列。(这块分词处理比较粗糙,还可以进一步优化)
第2步:word2vec训练词embedding向量
每条评论的分词序列作为样本交给word2vec模型训练,可以为每个词学得K维的embedding向量表示,两个词embedding向量之间的距离可以体现出词之间的相似度。
将每条内容的所有分词的embedding向量求平均,可以得到内容的embedding向量,相似内容之间的embedding向量距离也是相近的。
下面是word2vec原理,我们理解模型的输入输出是什么、以及embedding向量来自于模型的哪个部分即可:
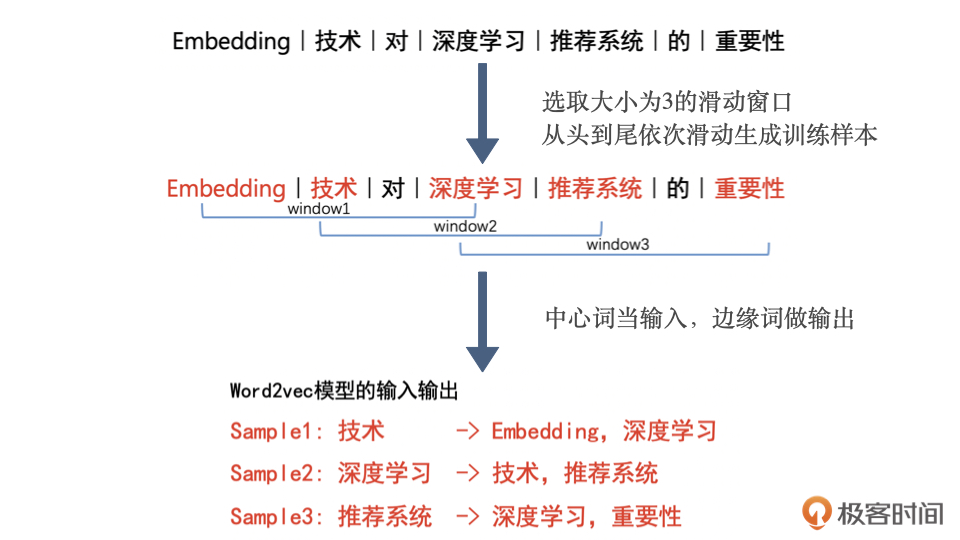
- 通过对分词序列滑动窗口,可以不断生成训练样本,中心词为输入,周边词为输出,均为onehot方式。
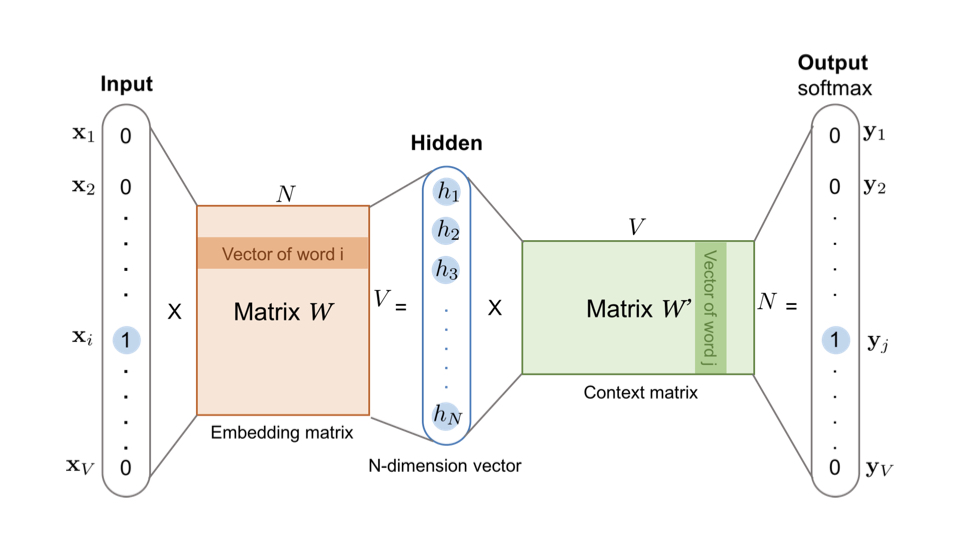
利用双层神经网络,训练后权重矩阵W的每一行就视作对应onehot位置单词的embedding向量了。
下面的代码基于每行评论的词序列生成大量样本,完成了word2vec训练并得到了词embedding向量:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# word2vec训练词向量(输入:Words词序列,输出:embedding词嵌入向量) word2vec = Word2Vec(vectorSize=20, numPartitions=4, maxIter=3, seed=33, inputCol='Words', outputCol='Embedding') model_path = './word2vec_model' try: word2vec_model = Word2VecModel.load(model_path) except: word2vec_model = word2vec.fit(douban_df) word2vec_model.save(model_path) """ # 展示词向量 word2vec_model.getVectors().show(truncate=False) +------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ |广义 |[0.2298308163881302,0.10184220224618912,0.11428806185722351,-0.2545117735862732,0.13371628522872925,0.38737785816192627,-0.18080611526966095,0.2912159264087677,-0.042845338582992554,0.007754012010991573,0.07340796291828156,0.21571871638298035,0.027845118194818497,-0.1927560269832611,-0.23800526559352875,-0.09630415588617325,0.26478031277656555,-0.02759205549955368,-0.035280026495456696,-0.11370658129453659] | |我愿用|[0.3569982349872589,-0.04008175805211067,-0.02228064462542534,-0.13809481263160706,0.11383146792650223,0.14169472455978394,0.01509785931557417,0.18307729065418243,-0.5875641107559204,0.03696838393807411,0.12065540999174118,0.0557398721575737,-0.2770899832248688,-0.4094037115573883,-0.2359398901462555,0.08770501613616943,0.1590811014175415,-0.4789951741695404,0.09150195866823196,0.2459736317396164] | |钟爱 |[0.16913776099681854,0.1437755525112152,-0.021099811419844627,0.27797627449035645,0.1678694784641266,0.5455443263053894,0.2237573117017746,0.6392733454704285,0.38522306084632874,-0.27834826707839966,-0.13266880810260773,-0.04945696145296097,0.007050633430480957,-0.15870216488838196,-0.21051383018493652,-0.1582833230495453,0.6880394220352173,-0.10668554157018661,-0.06236705929040909,-0.113636814057827] | |甩手 |[0.25139203667640686,0.055334556847810745,0.2298315018415451,-0.5309959053993225,-0.6890652179718018,0.40532222390174866,0.2501186728477478,-0.1895916908979416,-0.06725015491247177,0.5156218409538269,-0.3592650890350342,0.16960440576076508,-0.9050099849700928,-0.29024872183799744,0.011675757355988026,0.23859812319278717,0.31643491983413696,0.23006290197372437,0.2294362634420395,0.13764706254005432] """ |
这里我对训练好的word2vec神经网络做了保存与加载,避免下次启动重复计算。
这里指定:
- vectorSize:词embedding向量长度。
- numPartitions:计算并行度。
- maxIter:样本迭代训练次数。
- seed:随机数种子。
- inputCol:指定Words列为词序列字段。
- outputCol:指定内容embedding向量(也就是分词embedding的平均)的输出字段。
这里getVectors可以查看模型学到的所有word的embedding向量。
第3步:word2vec生成内容embedding向量
调用上述word2vec模型,可以直接为每条评论生成内容embedding向量,其原理为计算其所有分词embedding向量的平均值。
|
1 2 3 4 5 6 7 8 9 10 |
# 使用词embedding的平均得到评论embedding douban_df = word2vec_model.transform(douban_df) """ +---+--------------------+-------------+----------+------+----------------+----------+----+------------------------------------+----+----------------------------+--------------------+ | ID| Movie_Name_EN|Movie_Name_CN|Crawl_Date|Number| Username| Date|Star| Comment|Like| Words| Embedding| +---+--------------------+-------------+----------+------+----------------+----------+----+------------------------------------+----+----------------------------+--------------------+ | 0|Avengers Age of U...| 复仇者联盟2|2017-01-22| 1| 然潘|2015-05-13| 3| 连奥创都知道整容要去韩国。|2404| [ , 连, 奥创, 都, 知道,...|[0.10938933864235...| | 1|Avengers Age of U...| 复仇者联盟2|2017-01-22| 2| 更深的白色|2015-04-24| 2| 非常失望,剧本完全敷衍了事,主线...|1231| [ , 非常, 失望, ,, 剧本...|[0.10207881422985...| | 2|Avengers Age of U...| 复仇者联盟2|2017-01-22| 3| 有意识的贱民|2015-04-26| 2| 2015年度最失望作品。以为面面...|1052| [ , 2015, 年度, 最, ...|[0.04180616276784...| """ |
评论embedding向量输出在Embedding列,此时任意两条评论之间的距离可以直接基于embedding列的向量求距离(例如余弦距离、欧式距离等)即可。
为什么距离有意义呢,很简单:
第4步:训练LSH
虽然有了评论embedding向量,但是要为每条评论计算与其embedding距离最近的其他评论,需要进行笛卡尔乘积规模的全交叉运算,这个代价在大规模数据集下不现实。
LSH局部敏感哈希算法可以解决这个问题,它通过对所有embedding向量的观察,可以学得向量v:
对于embedding向量x,通过与 v内积可以映射为整数h(v),即: h(v)=v⋅x
此时对整数h(v)进行哈希分桶,LSH可以基本保证相同桶内embedding向量距离相近,而不同桶之间的embedding向量相远,因此对于任意x向量通过通过快速分桶并仅对桶内的embedding向量求距离,那么可以极大降低计算规模。
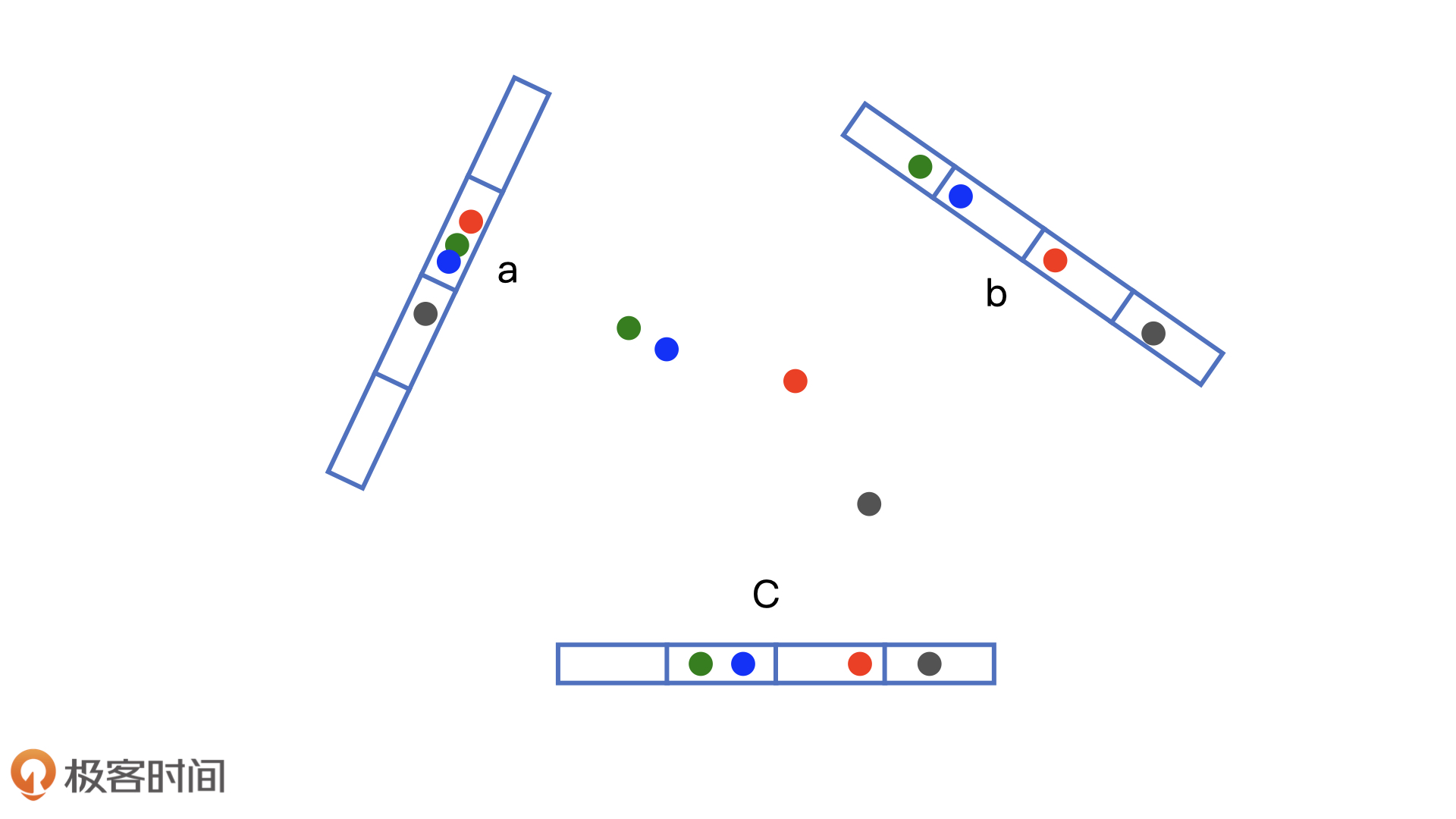
我们执行如下代码训练LSH,输入是所有的内容embedding向量,训练后的LSH模型具备了向量分桶能力:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 训练LSH实现评论embedding快速近邻向量检索 lsh = BucketedRandomProjectionLSH(inputCol='Embedding', outputCol='Buckets', numHashTables=2, bucketLength=0.1) model_path = './lsh_model' try: lsh_model = BucketedRandomProjectionLSHModel.load(model_path) except: lsh_model = lsh.fit(douban_df) lsh_model.save(model_path) # 评论向量embedding计算分桶 douban_df = lsh_model.transform(douban_df) """ +---+----------------------+-------------+----------+------+----------------+----------+----+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------+ |ID |Movie_Name_EN |Movie_Name_CN|Crawl_Date|Number|Username |Date |Star|Comment |Like|Words |Embedding |Buckets | +---+----------------------+-------------+----------+------+----------------+----------+----+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------------------+ |0 |Avengers Age of Ultron|复仇者联盟2 |2017-01-22|1 |然潘 |2015-05-13|3 | 连奥创都知道整容要去韩国。 |2404|[ , 连, 奥创, 都, 知道, 整容, 要, 去, 韩国, 。] |[0.10938933864235878,0.03443918861448765,-0.10702529400587082,-0.38637474924325943,0.15594946965575218,0.09199576601386071,0.031935117207467556,-0.09990134164690972,-0.20399864204227924,0.11699134185910226,-0.11464695297181607,-0.01393067641183734,0.477449905872345,0.06377089992165566,-0.0963845506310463,0.43218154385685925,0.12875955402851105,0.07581734843552113,0.09165327474474907,-0.4218080684542656] |[[1.0], [-4.0], [-3.0]] | |1 |Avengers Age of Ultron|复仇者联盟2 |2017-01-22|2 |更深的白色 |2015-04-24|2 | 非常失望,剧本完全敷衍了事,主线剧情没突破大家可以理解,可所有的人物都缺乏动机,正邪之间、妇联内部都没什么火花。团结-分裂-团结的三段式虽然老套但其实也可以利用积攒下来的形象魅力搞出意思,但剧本写得非常肤浅、平面。场面上调度混乱呆板,满屏的铁甲审美疲劳。只有笑点算得上差强人意。 |1231|[ , 非常, 失望, ,, 剧本, 完全, 敷衍了事, ,, 主线, 剧情, 没, 突破, 大家, 可以, 理解, ,, 可, 所有, 的, 人物, 都, 缺乏, 动机, ,, 正邪, 之间, 、, 妇联, 内部, 都, 没什么, 火花, 。, 团结, -, 分裂, -, 团结, 的, 三段式, 虽然, 老套, 但, 其实, 也, 可以, 利用, 积攒, 下来, 的, 形象, 魅力, 搞, 出, 意思, ,, 但, 剧本, 写得, 非常, 肤浅, 、, 平面, 。, 场面, 上, 调度, 混乱, 呆板, ,, 满屏, 的, 铁甲, 审美疲劳, 。, 只有, 笑, 点算, 得, 上, 差强人意, 。] |[0.10207881422985982,0.009545592398087426,-0.005397121676118909,-0.27453956138001895,0.26000592432825304,0.20473303055254424,-0.030830345179022448,-0.07669864853889477,-0.039627203943559945,-0.030836417169378297,0.08670296354173887,-0.11762266961585095,0.3601643921262244,0.11058124398497479,-0.29385836420171874,0.2274733007908231,-0.11165728573062707,0.295819340103374,0.04263881457083654,-0.21918029104155012] |[[1.0], [-4.0], [-3.0]] | """ |
- numHashTables:支持多个哈希函数,这样可以对同一个embedding向量分到多个桶,每个桶内都计算与其他向量的距离,这样可以提升搜索的准确率(因为相近的embedding有概率被划入2个桶,如果只使用1个哈希则会错过其搜索机会)
- bucketLength:能够决定分桶的数量,桶越多单个桶内的向量越少计算越快,但是误分桶的可能性越高,具体参考:https://george-jen.gitbook.io/data-science-and-apache-spark/locality-sensitive-hashing。
- outputCol:embedding向量的分桶结果,有几个哈希函数就会落入几个桶内,搜索会在多个桶内进行。
第5步:LSH求embedding的最近距离向量
因为LSH计算好了每个内容的分桶,相当于内容被投入到对应的桶内了,因此桶内的embedding之间可以俩俩计算距离,就为每个内容找到最相似的内容了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 求每个评论的embedding近邻 # 下面将计算并找出与每条评论距离在0.5之内的其他评论,即1条评论对应N行(也可能完美没有满足相似阈值的评论) comment_distance = lsh_model.approxSimilarityJoin(douban_df, douban_df, 0.5, 'Distance').select( col('datasetA.ID').alias('ID1'), col('datasetA.Movie_Name_CN').alias('Movie_Name_CN1'), col('datasetA.Comment').alias('Comment1'), col('datasetB.ID').alias('ID2'), col('datasetB.Movie_Name_CN').alias('Movie_Name_CN2'), col('datasetB.Comment').alias('Comment2'), 'Distance' ).filter('datasetA.ID!=datasetB.ID') """ +-------+--------------+---------------------------------+-------+--------------+-------------------------------------------------------+-------------------+ |ID1 |Movie_Name_CN1|Comment1 |ID2 |Movie_Name_CN2|Comment2 |Distance | +-------+--------------+---------------------------------+-------+--------------+-------------------------------------------------------+-------------------+ |435330 |栀子花开 | 两颗星给李易峰 |1470972|左耳 | 两颗星给颜值 |0.38069596328509925| |613184 |西游降魔篇 | 两颗星给黄勃 |1621735|小时代1 | 一颗星给郭碧婷,一颗星给郭采洁 |0.48683903755603564| |1373353|寻龙诀 | 三颗星给黄渤 |608897 |西游降魔篇 | 三颗星给黄渤 |0.0 | |1411122|长城 | 一分滚粗 |1522164|美人鱼 | 0分拿好滚粗 |0.460533064639379 | |1522164|美人鱼 | 0分拿好滚粗 |1710475|小时代3 | 负分滚粗没商量 |0.49409727822501526| |1619027|小时代1 | 一颗星给hold住姐,一颗星给郭采洁|1298111|寻龙诀 | 一颗星给舒淇,一颗星给黄渤,一颗星给夏雨,一颗星给特效|0.475884983339599 | |1635295|小时代1 | 两颗星给摄影 |1620559|小时代1 | 一颗星给郭采洁一颗星给凤小岳一颗星给全片服装! |0.48163949367050163| |1635403|小时代1 | 一颗星给雪姨 |1487506|左耳 | 两颗星给杨洋 |0.469489490113617 | """ |
approxSimilarityJoin需要传入2个embedding表格,会为每条左侧的embedding向量计算右侧与其在相同桶内的embedding向量之间距离,并且只保留距离在指定阈值之内的pair,这里左右都是同一张表,保留的向量距离阈值是0.5,距离存在Distance字段。
上面对输出结果进行了一定的整理,方便查看;另外,上述计算过程还是比较消耗内存的,如果OOM需要考虑调大spark任务的内存分配大小。
上述结果保留了每个Comment的相近Comment,即1个ID1可能对应多条ID2,因为它们距离都满足<=0.5。
第6步:为每条评论A仅保留TOP 3近似的评论B
对上述表格中的每条ID1做聚合统计,保留其Distance最近的3条ID2评论,将3条评论的信息拉平到列。
为了方便,我们使用视图表,直接写SQL完成处理:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
# 为每个评论保留top 3相似的评论 comment_distance.createOrReplaceTempView('comment_distance') sql = ''' -- 保留每个评论的top 3相似评论 with comment_with_rank as ( select *, row_number() over (partition by ID1 order by Distance asc) Ranking from comment_distance ), -- 每个评论留1条详情 comment_info as ( select * from comment_with_rank where Ranking=1 ), -- 每条评论top3拉平为列 comment_with_top3 as ( select ID1, collect_set(ID2) Similar_IDs, collect_set(Movie_Name_CN2) Similar_Movie_Name_CNs, collect_set(Comment2) Similar_Comments from comment_with_rank where Ranking <= 3 group by ID1 ) -- 输出结果 select a.ID1 ID, b.Movie_Name_CN1 Movie_Name_CN, b.Comment1 Comment, a.Similar_IDs, a.Similar_Movie_Name_CNs, a.Similar_Comments from comment_with_top3 a left join comment_info b on a.ID1=b.ID1 ''' similar_comment = spark.sql(sql) similar_comment.show(truncate=False) """ +-------+-------------+-------------------------------------------+---------------------------+-----------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------+ |ID |Movie_Name_CN|Comment |Similar_IDs |Similar_Movie_Name_CNs |Similar_Comments | +-------+-------------+-------------------------------------------+---------------------------+-----------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------+ |1003663|湄公河行动 | 燃 |[413813, 1826585, 21480] |[大圣归来, 复仇者联盟2, 变形金刚4] |[ 燃] | |100704 |大鱼海棠 | 我是水军 |[927552, 732687, 322503] |[西游伏妖篇, 大圣归来, 泰囧] |[ 我是水军] | |100735 |大鱼海棠 | 美术四颗星星,剧情倒扣一颗 |[317020, 1342752, 1463529] |[长城, 大圣归来, 寻龙诀] |[ 两颗星给舒淇,两颗星给陈坤。特技制作倒扣一颗星,故事情节怒扣一颗星!, 特效四分,景甜扣一分, 配音减半颗星,剧情减半颗星,制作加一颗星] | |1023406|七月与安生 | 三颗半星 |[967431, 1325652, 1145942] |[何以笙箫默, 寻龙诀, 复仇者联盟] |[ 三颗半星, 半颗星] | |1046207|七月与安生 | 七月,お元気ですか。 |[780413, 227188, 1889591] |[爱乐之城, 你的名字, 十二生肖] |[ 16 Oct 2016 BIF LFF// 静かな娘の視野で、見知らぬ誰かの姿を映す。君は誰だ?君 の名はなんだ?君のためにここにいる。, ハイテク、すごい!, 男主补完了!おめでとう!] | |1080723|复仇者联盟 | 爽歪歪 |[1109289, 1088785, 1081040]|[复仇者联盟] |[ 爽歪歪] | |1083168|复仇者联盟 | 黑猫警长大战变形金刚 |[1104097, 1087274, 1085367]|[复仇者联盟] |[ 孙悟空大战葫芦娃, 美国版孙悟空大战黑猫警长..., 美版金刚葫芦娃] | |1087859|复仇者联盟 | 绿巨人是BUG |[1123361, 1115515, 1079016]|[复仇者联盟] |[ 绿巨人是BUG, 绿巨人就是BUG] """ |
可以看到,结果表格中每条评论的3条相似评论被拉平到列,以数组的形式存在。
我们也可以看到,word2vec生成的内容embedding向量很好的发现了一些有意思的相似评论:
电影《大鱼海棠》的评论:“美术四颗星星,剧情倒扣一颗”,与其他3部电影的如下3条评论相近::
- 两颗星给舒淇,两颗星给陈坤。特技制作倒扣一颗星,故事情节怒扣一颗星!
- 特效四分,景甜扣一分
- 配音减半颗星,剧情减半颗星,制作加一颗星
不过突然发现collect_set好像把值乱序了,大家可以换成collect_list试试 
最后
word2vec可以为任意序列中的item生成embedding,比如商品访问序列可以训练商品embedding,其之间的距离可以一定程度上体现出商品之间的相似度。此时,将用户的商品序列的embedding求平均可以作为用户的embedding,此时用户embedding和商品embedding之间也可以进行距离计算,体现出用户对商品的偏好,此思路可以用作线上推荐商品召回。
word2vec训练好的embedding可以导入到向量实时检索系统,实现在线的embedding高效距离计算,其原理类似LSH,可以看一下facebook开源的主流向量检索服务:faiss。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~

1
1