numpy机器学习 – 感知机分类
本文介绍如何推导与手写一个感知机分类模型,涉及到数学推导没法事无巨细,所以下面只是一个大概的流程记录。
理论简述
数据集是关于图片是”横版”还是”竖版“的分类问题:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
x1,x2,y 153,432,-1 220,262,-1 118,214,-1 474,384,1 485,411,1 233,430,-1 396,321,1 484,349,1 429,259,1 286,220,1 399,433,-1 403,300,1 252,34,1 497,372,1 379,416,-1 76,163,-1 263,112,1 26,193,-1 61,473,-1 420,253,1 |
x1和x2是图片的宽和高,我们知道宽>=高就是横版图片(y=1),宽<=高是竖版图片(y=-1),但我们要让模型自己学习这个关系。
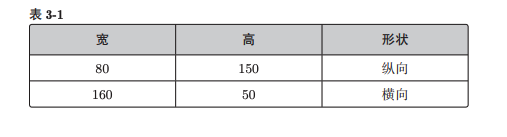
这两种图片在分布上呈现明显的差异:
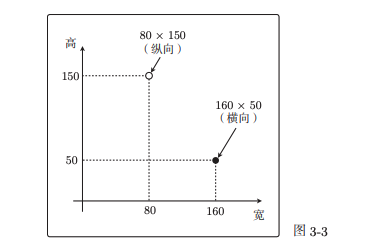
我们的目标就是训练一个直线,切开这两种点:
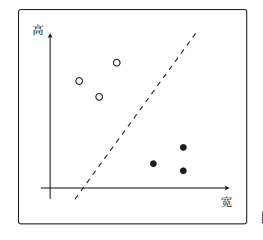
感知机模型就是一种原理简单的分类模型。
因为有2个特征x1和x2,感知机模型的分类函数就是这样,是2个向量的乘法:
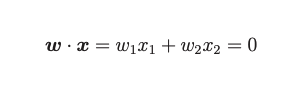
模型要训练的就是w向量,但这是什么含义呢?其实w与x做内积还可以用这样的方式计算:
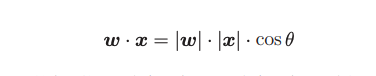
表示w向量的长度与x向量的长度与向量夹角的cos值做乘法,cos函数是有正负号的:
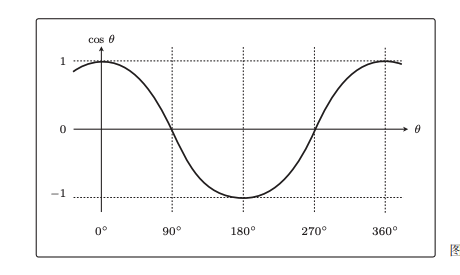
当2个向量夹角在90~270之间的时候为负数,否则为正数,当2个向量夹角为90度(垂直)的时候为0,那么2个向量w*x就是0。
我们把w向量用实线画出来,然后与w向量垂直的向量用虚线画出来,那么虚线就是分类边界了:
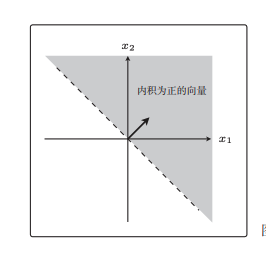
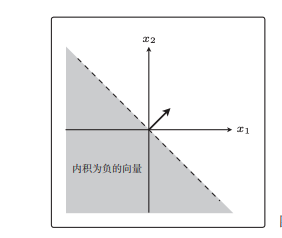
当(x1,x2)向量与w向量做内积后为正数时,表示x向量与w向量在同一侧;
当(x2,x2)向量与w向量做内积后为负数时,表示x向量与w向量在不同侧。
因此w*x具备了2分类的一种能力,就是看x向量与w向量的夹角即可,但是虚线分界线应该如何找到呢?那就是通过训练模型来修正w实线向量来最终得出的。
训练原理也很简单,我们首先明确样本中y=1是横版,y=-1是竖版。
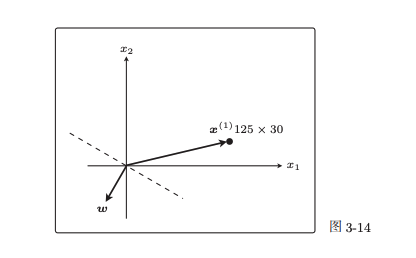
我们随机初始化w向量,当输入某个样本x时计算wx内积,发现如上图在不同侧,内积结果为负数,即模型认定分类为-1,但如果实际上样本y是分类1:

那么此时就需要修正w向量,修正方法就是对w向量做旋转:
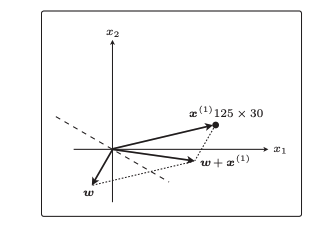
旋转方式就是w向量+x向量作为新的w向量,新的向量w+x从图形上来看就是现在w向上旋转了一下,更加贴近于x,也就站到了与x向量同一侧,下一次分类就会判定为y=1,分类即可正确。
同样的,如果内积为y=1,但实际样本y=-1,那么要做的是w-x向量,实现的效果是让w向量远离x向量,即w转向与x不同侧的方向,这样下次预测为y=-1就正确了。
将w向量的学习过程总结为数学符号:
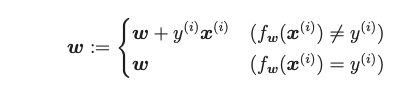
即预测分类与正确分类不一样的时候,我们需要对w向量修正,方式就是+x或者-x向量,具体看情况。
代码开发
先加载数据:
然后定义分类函数,就是w和x向量的内积,根据内积符号返回分类1或者-1:

训练过程就是逐个样本做内积分类y,和样本y比较一下:

如果预测y和真实y不一样,那就修正w。
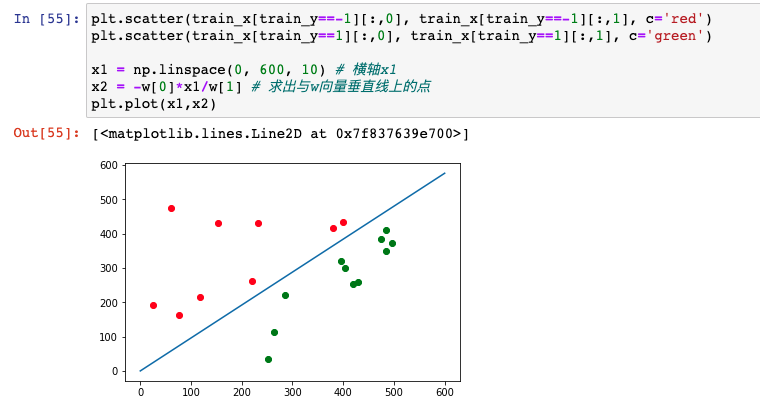
最后要绘制的分界线是与w向量垂直的那条直线,我们把w带入到w1*x1+w2*x2=0中,将x1作为横坐标,x2作为纵坐标,y作为颜色,根据x1即可求出直线上的x2点,绘制出上述图案。
如果文章帮助您解决了工作难题,您可以帮我点击屏幕上的任意广告,或者赞助少量费用来支持我的持续创作,谢谢~
